

虎嗅注:
伴随教育赛道的火热,分级阅读也火了。
分级阅读在国外是一个百亿美金的赛道,相关产品覆盖了美国90%的K12学校,不管是这种学习方法还是商业模式都已经被验证,移植进中国也是顺理成章。
近几年,国内大多数教培企业也在尝试做分级阅读,不过都是借鉴国外已有的分级阅读标准在英文领域进行尝试,搭建个性化的英语阅读平台。比如,51Talk、哒哒英语、VIPKID等在线英语平台纷纷披露了与英文分级阅读相关的产品计划。2017年8月,美式少儿英语分级阅读平台读伴儿宣布,已完成2400万元Pre-A轮融资,由鼎晖投资领投。
然而,中文分级阅读却一直未有较好的发展。
说起来,开创中文分级阅读这事,市场前景不错、家长需求明显,却多年没人敢碰,创业公司寥寥,获得融资的公司更是寥寥。
2017年12月,中文分级阅读平台考拉阅读宣布完成千万级美元A轮融资,由启明创投、GGV纪源资本共同投资, 这在中文分级阅读领域算是打响了头炮。
不过,为什么中文分级阅读这么难搞,其中的瓶颈和难点在哪里?中文分级阅读应该如何扎根“中国土壤”?
本期大咖私房话邀请就到考拉阅读CEO赵梓淳为大家带来对中文分级阅读赛道的解读。
赵梓淳先后就读于美国芝加哥大学的金融数学专业和哥伦比亚大学的金融运筹专业,是教育领域的连续创业者。其CTO任易是北京大学数据挖掘方向的博士,曾在IBM中国研发中心Waston for Life Service和微软亚洲研究院工作;首席数据科学家Jake Zhao曾在Facebook从事研究工作,师从于机器学习顶尖学者、深度学习的奠基人之一Yann LeCun教授。
在本次活动中,赵梓淳共分享了四大主题:
分级阅读领域的现状及未来发展方向是什么?
如何通过教育技术的深度融合革新传统的阅读培养模式?
中文分级阅读底层标准搭建的技术特征和壁垒是什么?
分级阅读当下还面临哪些难题?AI需要大数据,支持分级阅读系统构建的大数据从何而来?
以下是本期大咖私房话内容实录,enjoy~
英文分级阅读标准成熟,相关产品也很丰富
英语分级阅读已经是一个相对成熟的市场,覆盖美国90%以上学校。西方世界提出分级阅读的概念大概已经有百年的历史了,真正地提出分级阅读的标准像learningA-Z分级法这种工具标准大概已有十余年的时间,比较主流的分级标准是蓝思分级和GE分级。
分级阅读是什么?
举一个不恰当的例子,有点类似于“买鞋”,我们知道自己脚的大小从而买到一双适合自己脚的鞋。而不是当一个孩子去买鞋的时候,并不知道自己穿多大号的鞋子,而是说我要买一双8岁儿童的鞋,一定是因材施教,根据每个人脚的大小去匹配合适的鞋。
在分级阅读概念提出之前,西方国家的孩子阅读习惯其实跟中国差不多,国内背《四书五经》,西方国家的孩子就开始看《圣经》,逐渐的会发现其实这样效率是很低的。并不是说读《四书五经》或者《圣经》就不能锻炼自己的阅读能力,而是效率相对较低。
英文分级阅读市场现状
西方国家用了大概40多年的科学研究成果证明,分级阅读可以有效地提高孩子的阅读效率。在同等时间内,同等付出情况之下分级阅读可以提高孩子大约1.5倍以上的阅读效率。

以Lexile分级(蓝思分级)和GE分级为代表的英文分级阅读标准已推行40年。 近年来,在标准之上诞生了数家过亿美金的分级阅读教育产品公司。
比如,美国 K12 个性化阅读学习平台的 Newsela ,曾获得扎克伯格夫妇等人跟投1500 万美元的B轮融资。Newsela 聚合了美联社、《科学美国人》等热门媒体的新闻并将阅读难度分级,为不同年龄段、阅读水平和兴趣爱好的学生提供个性化的新闻阅读内容。
每个孩子可以根据文本难易程度选择阅读APP内的新闻,每天大概更新5-6篇的新闻,每篇新闻大概划分5 个不同水平的阅读难度,不同的孩子可以找到适合自己难度的文章。这样可以保证每个孩子在阅读水平不一样的情况下,可以看到同样价值的新闻内容。例如,把介绍飞人乔丹的新闻分成五个等级,最高级别的可能会有1000个单词,最低阅读级别可能只需500个单词就能浏览同样的内容。
另外,LightSail这家公司开发了一个可以在iPad、安卓、Chromebook等平板上安装的图书馆应用,收集了适合K12学生阅读的来自400多个出版商的8万多本图书。当然,LightSail的功能不只是平板阅读软件,它还可以根据学生的阅读水平推荐难度适宜的书籍,并将阅读与教学联系在一起,可以帮助老师掌握学生的阅读进度等数据。
而Renaissance这家公司成立的时间比较悠久,其创始人是一个家庭主妇。为了校验孩子读书的效果,她决定出一些和内容相关的书后题,后来发现效果很好,然后用同样的方法去教邻居家的孩子,效果都不错。 以此为出发点成立了分级阅读公司,现在已经经营40多年的时间,教育了几千万的美国孩子。
其实在国内,很久以前就已经提出了分级阅读的概念,也做了一些很有益的尝试,比如,南方报业出版社、接力出版社等都在做分级阅读方面的尝试,但分级标准基本上都是停留在按年龄或者按年级这样笼统的分级标准上。比如,适合8岁孩子看的书单、初级阅读书单、高中阅读书单等等。
这样的分级阅读标准和英文分级标准差别很大。英文分级是个性化的阅读匹配,它需要把每个人的能力测出来,并且需要把每个文本的阅读难度测出来,从而进行匹配。例如,蓝思分级,它能把人的能力测出来,从200蓝思到1700蓝思,同时把文本的难度也从200蓝思测到1700蓝思,从而进行匹配。
中文分级阅读难度远大于英文
但为什么一直以来国内没有做出中文的分级标准?中国的分级标准到底跟英文分级标准区别在哪,难度有多大?
第一,中文的基础组成常用汉字比英文的字母更复杂,对中文的文本难度进行评定需要更丰富的语料库;
第二,中文的句法结构和断字分词要比英文更难,加大了研究程度。
英文的基础组成是26个字母,而中文的基本组成是3500个汉字,并且是常用汉字。《康熙字典》里收录了大概800多万汉字,这种复杂构成会导致分析中文的时候往往需要更庞大的语料库。
另外,其实不论英文还是中文,表意单位都是词语,而英文的词语有天然的分词属性,单词之间分开的。但中文其实是没有天然分界线的。例如,量子自旋霍尔效应这样的词应该怎么去划分开,因为量子、自旋、霍尔、效应四个词语单独分开,和它作为一个词理解难度是完全不一样的。
举个例子,以蓝思为例,蓝思的文本难度主要去考察两个特征值。一个特征值是词频,蓝思有一个大的词频表,即每个词在词频表里出现的频率。词频的频率越高认为词越简单。同样表达好看的意思,beautiful会比gorgeous的词频相对要高,说明beautiful较简单。另外考察的因素就是句长,一个句子里含有的单词越多,相应地认为这个句子的理解难度越高,句子的结构越复杂,需要短时记忆能力也越高。
蓝思分级主要是以上这两个特征,而如果单纯地借鉴英文的一些经验嫁接到中文分级标准其实并不太适用。例如词频标准,中国的词频表里出现的频率较低的词汇,比如“鬣狗”这个词,“鬣”字出现的频率很低。但在实际应用中“鬣”可能不会影响到孩子的理解。因为你可能不需要知道“鬣”是什么意思,知道“鬣狗”是一种狗就可以了。再比如“卫生纸”这样的组合词,其词频比较低,但“卫生”和“纸”的词频较高,组合成“卫生纸”一词也并不难理解,这就和低词频相矛盾了。如果单纯地按照词频来进行判断一个词难不难,其实并不太靠谱。
另外根据句子长短来判断难易程度,其实对中文也不太适用。比如,不同的标点符号的使用会直接影响一句话的长短。中文的句法结构没有英文严谨,并且中文里有很多文言句式的用法,像”道阻且长“这样的句子其实就会比”道路很难走,很长“难于理解,所以中文和英文有着本质性的差异。
考拉阅读这样做中文分级阅读
多维多特征确定文本难度
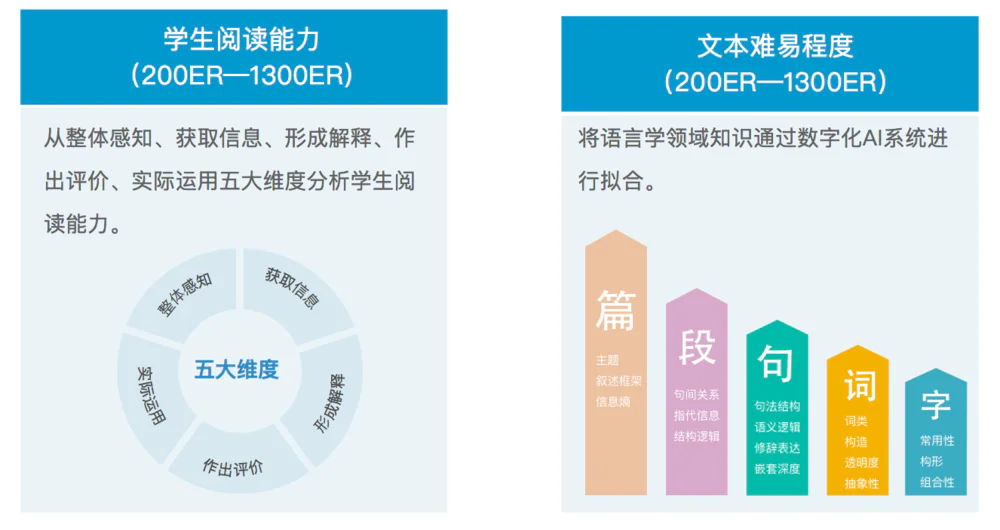
很多人都在问考拉阅读怎么去做中文分级阅读标准,我们在跟语言学家和算法团队交流之后,最终确定从字、词、句、段、篇五个大维度,大概几十维的特征,现在已经达到了七十多维的特征进行分级标准的确定。比如,字有常用性、构形、组合性等等;词有词类、构造、抽象性等等;句分语义逻辑、修辞表达、句法结构、嵌套深度等等;段又分句间关系、结构逻辑等,采用更多的特征维度共同去表征一个文本的难度。
具体的文本难度分析大致分为三步
第一步,考拉阅读构造了大概上千万字的黄金语料库,黄金语料库是一个非平衡语料库,主要取材于各个版本的语文教材及其教辅资料,其是指垂直于某一品类的语料库,如小说、历史传记各有其对应的语料库;因为教材有一个好处,它已经按照不同的年级对文本进行了难度的划分,同时也对孩子的阅读能力按照年级进行了区分。之后我们的语言学团队联合语言学家洪明教授和来自人民日报的十几个人组成的标注团队,从字词句段篇五个维度、几十维特征,给文本进行标注,历时半年之久,从字、词、句、段、篇五个维度进行特征提取。
第二步是要做更大的平衡语料库。平衡语料库即指一个孩子在日常生活中需要真实接触的语料,如按照一位10岁小孩需要看20%的名著小说、50%的课文和30%的漫画这种比例来配语料库。平衡语料库的传统做法是采用人工进行大量语料标注,考拉阅读则依托人工智能的算法,目前已经处理了约2亿字的平衡语料库。
因为中文的的句子相较英文要复杂得多,机器在理解中文的第一步就会遇到词性分析、语言模型上的困难。所以,有赖于现在流行的AI技术,如RNN、LSTM等深度学习技术,可以弥补中文在NLP上的缺失。现在考拉阅读可以做到,将一个句子按照句法树、依赖关联等予以拆解,以分析每一个成分在句子中的比重,从而实现阅读文本的难度分级。
第三步,需要把这些提取出来的特征拟合进AI系统,而区别于欧美英文分级阅读,考拉阅读的分级阅读系统最大的优势即在于AI在此发挥的作用。随着用户数量的增加,产生的数据越多,该系统中的模型可实现自主学习,不断优化,从而对文本阅读的难度感知越发准确。另外,我们为了去校验这样一套标准,在每一段结束之后会给孩子出相应的题目,通过大量的用户层面的数据进行反向反馈,不断优化我们的标准。
基于本文难度做阅读能力分级
当有了文本难度分级之后就该考虑人的阅读能力该如何分级。考拉阅读目前已经测试了全国一线城市到四线城市近40万的小朋友阅读能力。测试学生阅读能力的常模(虎嗅注:常模是指一定人群在测验所测特性上的普遍水平或水平分布状况,是一种供比较的标准量数)需要耗费公司很大的精力。比如托福GRE每出一道题大概需要花费五千美金做出常模。考拉阅读在做常模的时候需要走访到线下的各个学校,确保测试的真实性。然后把孩子的阅读能力拟合到分级标准里,把分级标准按照从200ER(中文分级阅读标准,ER来自enjoy reading缩写)到1300ER进行划分。
比如《小蝌蚪找妈妈》这样的文本难度大概在300ER左右,新闻类文章大概在700ER到900ER之间,难度比较大的有钱钟书老先生的《管锥编》,还有《道德经》大概能到1200ER以上,基本上接近文本难度的极值。对于600ER阅读能力的孩子应该匹配什么难度的文本,为此,我们引进了俄国心理学家维果斯基提出的“最近发展区”。什么是最近发展区?就是孩子阅读能力可以触及的区间。例如给一年级的学生看《红楼梦》,书虽好但却看不懂。如果天天看《小蝌蚪找妈妈》难度的书籍,基本也学不到新的知识。后来做了大量线下实验后发现600ER的孩子比较适合看550ER到700ER难度的文本,并且保证孩子对文本的理解程度在60%至90%之间,既保证了孩子对文本的理解,又不丧失阅读兴趣。

通过考拉阅读研发的“量化中文分级阅读标准系统”可以测出文本的阅读难度。据上图依次可以看到从小学一年级到小学六年级文本难度增长比较显著,在初中到高中阶段增长缓慢,所以最终考拉阅读选择在阅读能力跨度比较大的K12 领域去推广分级阅读标准。
根据分级阅读标准做学生阅读能力测评
当分级阅读标准制定出来以后又该如何有效利用,并且对语文教学进行改革?
首先是从C端进行切入,利用分级阅读产品对上千所小学的几十万用户进行阅读能力的测评,从而获得有效的测评数据。老师可以依据测评数据进行数据化的驱动,制定个性化的阅读授课方案,把每个学生的阅读能力技能点的缺失量化出来,针对性授课。
同时,可以对学生的阅读能力进行拟合,以更具体的形式呈现出来,比如,阅读能力在600ER的学生,最终拟合出来的结果是5.1,即五年级第一个月的中国孩子的平均阅读水平,这也得益于背后强大的数据库支撑。
在做区域性学生阅读能力测试的过程中我们发现,不同地区的孩子阅读水平相差很大,比如,中关村二小四年级的平均阅读能力可以达到600ER,而甘肃省某山区同年级孩子的平均阅读水平却只有400ER左右,未来可能会根据不同地区建立不一样的常模,进行因材施教。
分级阅读产品落地过程遇到的问题
在分级阅读产品落地的过程中也面临诸多问题。首先是中西方教育理念的不同,西方教育会认为分级阅读是一个很好的工具,就像给厨子一把好刀,具体该怎么用这把刀是由厨子说了算。 例如测出孩子的阅读能力之后,发现孩子对历史很感兴趣,老师会抛开阅读能力的测评结果,让学生更多的学习历史知识,所以说西方教育的分级阅读产品更多的强调了人为的因素。
但在国内会发现很难去推动分级阅读产品落地,仅仅告诉老师怎么去选书其实还不够。所以我们又做了下一步的尝试,把每本书的多种指标,比如,是否为教育部推荐书目、孩子感兴趣指数等进行拟合得出推荐权重,比如《小王子》推荐权重为90%,此书值得给班级同学布置阅读任务。老师可能才会去布置,这是东西方教育的差异之一。
另外,游戏化的教育产品在国内受欢迎程度会更高一些,所以我们后来又增加了很多有关游戏化的因素在里面,会发现C端的活跃数据提高很快,这也是东西方孩子和教育的一些差异。
那么,分级阅读到底对中文教学有没有意义,目前已经证实可以有效提高阅读效率,根据大数据分析系统进行数学建模,依据数据分析结果进行个性化的学习路径和基于难度及兴趣的阅读内容推荐。考拉阅读图书基因组计划也在做这方面的尝试,把人工智能和兴趣推荐结合起来,真正做到因材施教。
AI与教育结合,有价值也有局限
首先关于人工智能和教育结合的价值。第一,真正的个性化学习推荐,根据每个孩子的学习数据提供合适的学习内容,也可以帮助老师进行个性化的教学辅导;第二,提高老师的能效,依托人工智能技术去辨别每个孩子的阅读能力,提高老师的效率,扩大单个老师的服务范围;第三,降低对名师的依赖,依靠人工智能的辅助,非名师同样可以提供优秀的教学服务,间接提高教育公平性。
AI+教育的局限性比较明显,我们前期在做调研的时候跟学生交流:在阅读的过程中什么东西的激励更有意义,是平台给的排行榜第一名,还是阅读之后可以获得更多的金币?学生给的答案是老师或者家长的表扬。其实这些东西是通过人工智能永远无法取代的。人工智能不能为学习者带来更为丰富的学习体验,这很重要。其次人工智能不能解决更深层次的认知问题。比如,孩子不会解这道题,到底是走神了还是怎样的,其实更多的数据是没有办法收集的。
但是人工智能的确是一个好的工具,它可以让之前很多很难做的事情变得简单起来。很多专家判定采用传统的统计学、语言学的方法去做中文分级标准,大概至少需要10年到20年的时间,但是随着人工智能、深度学习技术的介入,极大地提高了效率。
Q&A
Q1:考拉阅读是怎样将人工智能、大数据技术应用在中文分级阅读领域中的?
赵梓淳:因为在中文分级阅读领域还没有大量的可用数据,从语料库到学生行为数据等,国内都是一片空白,整个框架都需要去搭建。
首先,我们打造了大概上千万字的非平衡语料库,主要取材于各种语文教材。语言学家洪明教授和来自人民日报的十几个人组成的标注团队,从字词句段篇五个维度、几十维特征,给文本进行标注。
第二步,用机器学习方法去学习语料库中专家打标签的规则,其实也得益于现在技术的发展,现在大概已经处理了几亿字的平衡语料库。
再下一步要得出分数,像英语主要考察词频和句长两个特征,它们用手写规则就可以得出公式,但在中文里这两点其实都不太靠谱,所以我们最后需要几十维特征来表征中文的阅读难度,把大概将近五十维的特征,拟合进AI系统,最后得出从200-1300ER的分值。
随着产品层面的数据越来越多,可以反向校准这个标准,实现自我进化。
Q2:对学生阅读水平的评估报告现在做可以到什么程度,对于学生有什么帮助?
赵梓淳:现在已经做到可以测评出每个孩子的阅读水平,以及和同年级学生阅读水平的对比、排名情况、五大维度的阅读能力缺失情况等几十维的测评报告,包括不同能力的缺失接下来怎么去应用我们的产品去进行查缺补漏。在调研过程中发现其实真正能提高阅读能力的方法就是大量地阅读。美国有一个理论叫SSR理论(Sustained Silent Reading),就是重量不重质的阅读,在一定时间之内会有一个质的飞跃,接下来我们也会根据孩子的阅读兴趣进行个性化的阅读推荐。
Q3:中西方阅读习惯上有什么不同,针对亲子阅读有哪些可以展开的内容?
赵梓淳:中西方之间的差异,首先是对阅读的认知是不一样的,阅读在美国是一门核心课程,而国内则定义为语文教学中的阅读理解模块。
第二个是美国有很多大学提供专门的阅读老师课程或专业,并且有理论去支撑阅读教学。
第三是国内外重视程度不一样,国外有专门的阅读课程和阅读相关的活动,但在国内很难让老师在教学中应用此类阅读分级产品。
关于亲子阅读,考拉阅读也在去研发相应的功能,例如考拉阅读家长端,家长可以和孩子共读一本书,并且产生交流等。另外,孩子在读《水浒传》时,他可能读不懂背后的深意,只读到了李逵嗜杀成性,他能不能想到背后其实是官逼民反,是时代扭曲了人性。其实这些都是可以去探索的点。
Q4:考拉阅读怎样保证对内容的有效筛选,阅读标准一旦开始普及,对传统教育会带来什么样的机遇和挑战?
赵梓淳:首先是要确保内容的来源合规合法,我们选取的内容基本上会是各地的权威书单,各教育局推荐的书单,新课标规定的书单等;另外是各类获奖的书单,比如宋庆龄基金的一些获奖书单,还有名家书单、畅销书榜单等。
第二个问题,首先考拉阅读的定位并不是一家纯粹的教育服务公司。根据商业模式粗浅地将教育公司分为两种,一种是提供教育服务的公司,像学而思、新东方等;另一种是教育服务公司,比如1V1的线上教育公司VIPKID等。而分级阅读未来的机会可能会重构少儿出版机构。但无论如何,教育的本质是能否提供优质的教育服务。
Q5:ER指标代表的是什么?考拉阅读在绘本的分级阅读方面做了哪些相应的工作?
赵梓淳:ER本质是一个单位,来源于享阅教育(enjoy reading)的缩写ER。关于绘本分级阅读相对较难,因为它不是纯粹的文本,有的孩子可能没有看过文本,但绘本可以帮助理解。绘本教育在传递内容之外还在输出关于美学教育等的各种功能,单纯按照文本难度去划分难易程度是不太合理的。
Q6:目前的商业模式以B2B为主,未来会考虑做2C市场吗?
赵梓淳:两端的市场都在做相应的尝试,因为B2B去挣政府或者教育机构的钱,周期比较长,不稳定性因素也比较高,所以2C的市场一直在做。无论凯叔讲故事还是得到都在涉及少儿内容市场,其实本质都是在做出版行业的事情。少儿阅读规模是一个百亿、千亿级的市场。目前的本质问题在于好的内容稀缺,怎么去有更好的机制让少儿阅读市场迸发出更好的内容,让优质的创作者得到相应的报酬,会是接下来的市场着力点。
Q7:接下来的分级阅读会考虑做学科阅读吗?对于孩子阅读能力提升的过程应该怎样提供适宜的服务?
赵梓淳:全科阅读会是我们接下来的发力点。全科阅读在西方国家已经是较为受欢迎的阅读理念,现在的产品中已经涵盖了短文阅读模块、历史、地理及和建筑相关的内容,但前期还是要去输出分级阅读的理念。无论是静默阅读理念,还是全科阅读教育理念、非虚构类文本的阅读理念等,是一个循序渐进的过程。
对于阅读能力的提升,首先我们会测出孩子的技能点缺失情况,根据缺失情况推荐阅读文本和书籍, 并且生成每日的任务指标,包括阅读时间、阅读文本,做题数量等。另外孩子可以根据感兴趣的内容选择相应的文本,过程中会伴有老师的指导,及每学期的阅读能力的测评,综合来去提升孩子的阅读能力。
Q8:目前的分级阅读产品更偏应试教育的阅读方式,未来会怎么样改善?
赵梓淳:分级阅读产品是为了引导孩子读更多的书,但在商业化和市场化过程中,如果要进学校推广分级阅读产品,就必须去迎合学校的需求,也就是应试教育。题海战术虽然让人感到反感,但要弥补技能点的缺失,确实需要大量题目引导学习,我们的产品自始至终推崇的是静默阅读,重量不重质的阅读告诉你什么书更适合读。接下来要做的是怎么在游戏化的过程中让孩子爱上阅读,既要迎合这个体制又要在体制中做出一些改变。
Q9:考拉阅读为什么没有切入英文分级阅读市场?
赵梓淳:好未来开发了一款面向中小学教师及学生的在线英语分级阅读产品“雪地阅读”,可以在线给孩子布置作业,去完成相应的阅读任务等。首先如果国内自主研发英语分级阅读标准其实是没太大说服力的,另外一种方式就是从国外引进分级阅读标准,那这样和大公司相比是没什么优势的,最终会成为资本角逐的猎物。
相反,中文分级阅读存在很大的空白市场,无论是技术上的难点还是现实上推动的难点,很少有公司去触碰这块。我觉得可能是小公司的一个机会,其实这就是创业的一个悖论,当大家都觉得好的时候,其实是一片红海。越难的事情坚持下来,未来可能就会看到一些更有价值的东西。
Q10:快速阅读对ER值有没有影响?未来商业模式上有哪些规划?
赵梓淳:相比较快速阅读而言,我们现在更多的关注在阅读好的体验上,更关注阅读之后能收获多少。如果线上既强调好又强调快对孩子来说可能会混淆目标感。所以在这样的情况下我们的产品理念没有去强调“快”的概念。
在商业模式上,首先是To B的生意,通过To B建立品牌背书;接下来是2C的生意,我们其实是天然适合2C的,阅读产品并不像背单词和学数学,孩子每天晚上要听睡前故事,是客观存在的场景。如何让阅读变得更有乐趣,让孩子读到他们能读懂的东西,获得成就感,从而建立激励体系,这是我们要做的事情。
评论