

造就第336位讲者 田兴
上海纽约大学神经与认知科学助理教授
自己挠痒自己笑?有病,得治。

认识人类自身一直是我们梦寐以求的目标。要实现这一目标,最重要的一环就是研究控制一切器官的大脑。
我先问大家一个问题,我们可以给自己挠痒痒,逗自己笑吗?

如果你不知道这个问题的答案,可以现在悄悄试一下。
大多数人都是不能挠自己痒痒,如果你能的话,我建议你去看一下神经科医生。
为什么我们不能挠自己痒痒,逗笑自己?
这与大脑的某种机制有关。请允许我在最后揭晓答案。
我们先来看大脑是什么?
它其实就是我们颅骨里3斤左右的东西,最基本单位叫神经元。一个人共有1000亿左右的神经元。根据神经元的类型和组织方式不同,大脑可以分成不同的脑区。每个脑区负责不同的功能。
我们把大脑比作一个硬件。众所周知,硬件必须通过软件来完成任务。比如你想吃鸡,就得在电脑上装吃鸡的软件,你想编辑图片,就需要安装Photoshop这种软件。
我们觉得大脑里可能也有这么一种“软件”,支持很多算法来对接大脑这个硬件。
我们如何来验证这个假设呢?
比较常见的一种方法是核磁共振。通过测量大脑释放某些物质的能量来为大脑照相。但它的缺点是费时,两秒才能照一张相,没有办法跟上人类思维的速度。
另一种无创方法,是用电生理技术照脑电图和脑磁图,可以每一毫秒照一张,实时监控大脑的动态。
我们就用这两种无创的方法来回答大脑是如何支持我们行为的。
具体的算法有很多,我就介绍三种最基本的算法。
01 输出越多,传导效率越低
我们做一个实验。

你现在盯着这个屏幕上的字一直看,使劲看,嘴里念叨“然然然然……”
你们觉得有什么奇怪的事情发生吗?
是不是这个字变得奇怪了?你觉得突然不认识这个字了。怎么右上角的犬字突然出现了?
我自己就经常这样,那时候我就说是不是我痴呆了,突然不认识这个字了?
其实,当你看“然”字的时候,你的视觉信号会分析它的字形,然后将这些信号传导到脑区,另一个脑区会分析这个字义。
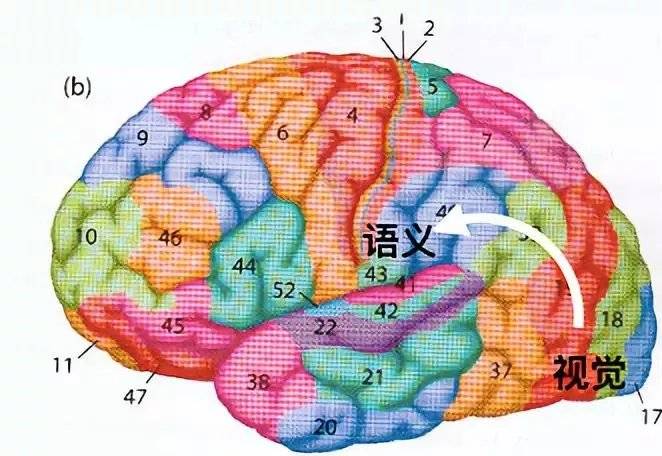
可如果你看久了,信息的传导效率会降低。
我们可以用数学模型来解释这件事。
大脑中的神经元是通过化学信号来传递电信号的。如果有信息输入进来,大脑通过神经递质把电信号传到下一个神经元。下一个神经元的输出就是最下面公式的“O”。
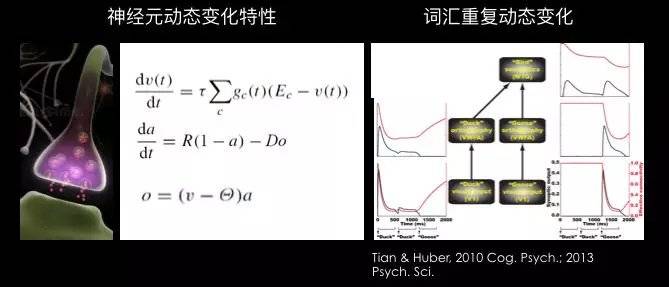
可以看到,输出其实是一个神经递质含量的函数。而神经递质其实就是它的传导效率。
从第二个公式上看,神经递质的传导效率又跟输出有关。也就是说,你输出越来越多,你的神经递质会越来越少。
它是一个动态的关系。
举个例子。你读“鸭子、鸭子、鹅”,你读了两遍鸭子,在视觉区和字形区,神经递质就会减少。在你说第二次鸭子的时候,对鸟类这个语义的激活程度已经很低了。但是接着你念了“鹅”,又再次激活了鸟的含义。
我们进一步用神经科学的方法来研究。
我们会让你看一个字,同时记录你的脑电图。我们发现在400毫秒之内,你会发生一系列的大脑的处理活动。

比如,大脑可以在100毫秒、200毫秒和400毫秒的时间内,依次进行初级的视觉处理、字形处理和字义处理。
我们用动态的数据分析方法发现,当你盯着一个字看久了,视觉字形皮层和字义皮层之间确实存在传导效率降低的现象。
你认为这是短时阅读障碍,但其实是大脑很重要的一个功能。
为什么重要呢?假如你是一个原始人,在大草原上听见猫叫。你发现听过很多次猫叫,你也不会死,说明这个猫对你来说不重要。但是如果你突然听见老虎叫,你会立刻反应“哎,快跑”。
所以,新颖性探测对人类而言是很重要的。神经之间的传导过程是会影响我们的行为的。
02 不同信息源加权平均形成新的表征
我们的信息不一定总来自一个模态。如果有两个或者多个信息源输入的话,我们的大脑会怎么处理这些信息?
这个视频是我的学生在说一个音节。
你试着努力听这个音节,会听到什么?
好,现在你们闭上眼再听。
是不是听到的不一样?为什么会不一样?
其实这个声音一直都是发“BA”这个音节。但是大家睁开眼的时候听到的是“DA”,闭上眼听到的是“BA”。
为什么会这样?
因为你看见她的嘴动,是“GA”的口型。当你边看边听时,视觉看到的“GA”与听觉听到的“BA”融合在一起,就变成了“DA”。
如果用数学公式表达的话,它是一个加权平均的效果。什么意思呢?就是两个信息源根据不同权重加起来形成一个新的表征。
这个权重如何决定?我们大脑里有一个计算方式。

我们认为权重大小可能是与某个信息源的方差成反比。方差意味着它的不确定性,方差越大,不确定性越多。权重与方差呈反比,也就是说,越确定,你就会越依赖于它。
这就是为什么看电影的时候,你会觉得声音是从屏幕中的演员嘴里说出来的,而不是从两边的喇叭里说出来的。
如果大脑觉得两个信息源的权重是差不多,就像刚才“DA”的实验,你会听见第三种声音。
如果听的信息与看的信息一致的话,大脑会做1+1大于2的计算。而如果它们不一样的话,那就是1+1小于2。
这表明,大脑确实有一种机制把不同的信息源,按照不同的方式整合起来,从而影响我们的行为。

03 大脑有预测机制,直接调制听觉皮层
通常我们所说信息源一般是由外界而来。如果有信息是来自内部呢?比如说我们的记忆,对吧?

大脑并非机器,有其主动性。它不是等着信息来了再分析,而是会主动预判的。
讲到这里,就是时候解释为什么我们不能逗自己笑了。
我们都知道,我们的运动系统控制着我们的动作,感觉系统让我看见、听见。这两个系统不是彼此孤立的。
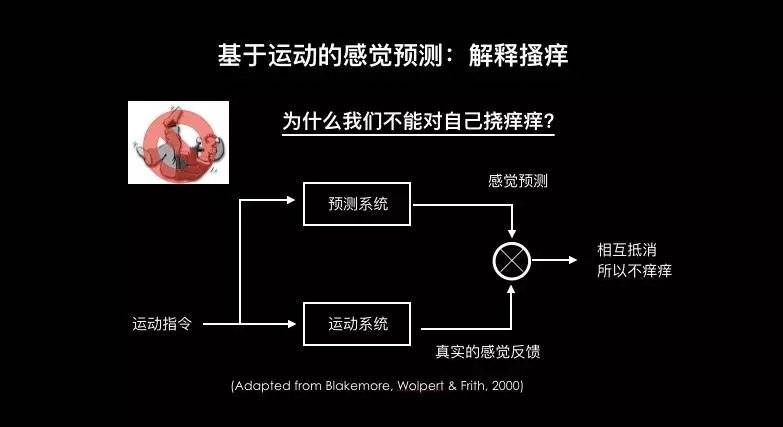
运动系统发出信号时,可以直接传导到感觉系统。而这个信号可以是预测某个动作产生的结果。
就像你自己挠痒痒和别人挠痒,其实痒的感觉是一样的。唯一的区别是大脑里的运动系统会提前告诉感觉系统说:“我自己会碰到自己了。”
这个预测信号与反馈信号是一模一样的,所以会互相抵消,你就不会有痒的感觉了。
不止是挠痒痒的现象,你有没有想过为什么我们能流利地说话呢?
你们觉得说话是很容易的事情,其实它是非常困难的。你想,以我现在的语速,大概1秒钟能说8个音节,也就是每125毫秒要说一个音节。
我不仅要把意思表达出来,要知道如何来说,如何控制我的肌肉来输出,还要随时监控我说的话,保证它是我想说的。
我们是如何在125毫秒之内完成如此多功能的?
我们认为大脑里有一个预测机制,会从你的运动系统直接告诉感觉系统你将要说什么、怎么说。而这个预测与反馈对比,进一步来控制我们的输出。
如果要用神经科学来证明的话,有一个问题就是你的输出与大脑的预测在时间上和空间上是重叠的,我们的所有结果都会被说话所掩盖。
于是,我想到了最传统的心理学范式——想象说话。

想象其实就是一个预测的过程。如果被试者想象说话,我们可以直接观察大脑是否有这个预测过程。
有意思的是在想象说话后的170毫秒,被试者大脑产生了一个图像,跟你真正听见声音时,大脑产生的图像一模一样。
这就证明了大脑里确实有预测机制,它可以激活听觉皮层。

那预测机制能否与反馈机制融合在一起呢?只有融合在一起,才能实现监视我们说话的功能。
我们又做了一个实验。
我们让被试者来想象说“DA”这个音节。可以是想象大声喊“DA、DA、DA”,又或是想象小声说“DA、DA、DA”。然后,我们会让他们听真实的“DA”声。
结果我们发现想象声音的大小会影响真实听见声音的大小。如果你想象大声说话,那么你后面听到声音时,会觉得声音变小了。

比方你今天回家太晚,觉得伴侣会跟你吵架。于是在电梯里,你已经想象过一遍吵架了,吵得非常凶,声音非常大。待会你进屋的时候,会觉得声音稍微柔和了一些。
所以说,想象的东西其实在大脑里也会有反应,可以直接调制你的听觉皮层。
最后,所有实验得出的结果是,我们所有的思维、意识和行为都是一套复杂完整的算法在脑这个硬件上计算出来的结果。
这个算法就是我们认知神经科学主要研究的方向。

由于认知神经科学只有几十年的历史,我们对大脑算法的理解还非常肤浅。
但是,现在全世界约有几十万个神经科学研究者在共同奋斗,还有工程学、医学甚至哲学等等其他领域的人们在加入我们。世界上所有主要国家也都在开展或正酝酿开展脑计划,包括我们中国。
对大脑机制的研究非常有意义,不仅可以加深我们对自我的认知,而且有着巨大的应用前景。比如预防治疗脑疾病,尤其是一些精神疾病。此外,还会促进人工智能质的飞跃。因为只有我们研究出了大脑的算法,计算机才能进行模拟,真正地理解人。