

本文来自微信公众号:机器之能(ID:almosthuman2017),作者:四月,原文标题:《清华出品:一文看尽AI芯片两类瓶颈三大趋势,存储技术开拓新疆界 | 附报告》。
12月10日—11日,由北京未来芯片技术高精尖创新中心和清华大学微电子学研究所联合主办的“第三届未来芯片论坛:可重构计算的黄金时代”在清华大学主楼举办,并正式发布了《人工智能芯片技术白皮书(2018)》(以下简称《白皮书》),同期《白皮书》电子版在机器之心同步首发。
人工智能热潮面前,淘金洼地接踵而至,安防、医疗、零售、出行、教育、制造业……因循守旧的传统行业正因为人工智能的嵌入而焕发出更多维度的商业机会,而这些机会都离不开基础层算力的支持,于是“AI 芯片”成为了 2018 年度最为热门的关键词之一。
然而,一个尴尬却无奈的现实正横亘在人工智能落地之路上——算力捉襟见肘,走出测试阶段的 AI 芯片寥寥无几,特定计算需求无法满足,导致再完美的算法也难以在实际场景中运行。
最典型的例子,安防市场谈智能终端摄像头已经有两三年时间,尽管巨头新秀的口号此起彼伏,但迫于芯片市场进度滞后,该类摄像头至今仍未普及开来。但与此同时,算力的进步恰恰来自于算法的迭代和优化。算法和算力——鸡和蛋的互生问题,正在相互促进却又在彼此制约中发展。
今天,机器之心带来一篇深刻讲述 AI 芯片产业发展全貌的权威报告——由清华大学—北京未来芯片技术高精尖创新中心联合发布的《人工智能芯片技术白皮书(2018)》。
《白皮书》编写团队资深权威,包括斯坦福大学、清华大学、香港科技大学、台湾新竹清华大学及北京半导体行业协会,新思科技等在内的领域顶尖研究者和产业界资深专家,10 余位 IEEE Fellow,共同编写完成。

《白皮书》发布仪式现场,照片从左至右分别为刘勇攀、尹首一、X.Sharon Hu、Kwang-Ting Tim Cheng、魏少军、唐杉、Yiran Chen、吴华强。
《白皮书》以积极的姿态分享了近两年来 AI 芯片与算法领域的诸多创新成果,通过客观阐述 AI 芯片在软硬件层面的技术难度,剖析 AI 芯片目前所处的产业地位、发展机遇与需求趋势,梳理 AI 芯片产业现状及各种技术路线,增进产业人士和从业者对于 AI 芯片市场的风险预判,以更为自信和从容的姿态迎接芯片市场的新机遇和新挑战。

一、AI 芯片的基本定义
《白皮书》第一、二、三章开宗明义,综述了 AI 芯片的技术背景,从多个维度提出了满足不同场景条件下理想的 AI 芯片和硬件平台的关键特征,提出 AI 芯片技术的重要地位以及对于我国未来芯片及人工智能领域发展的意义。
业界关于 AI 芯片的定义仍然缺乏一套严格和公认的标准。比较宽泛的看法是,面向人工智能应用的芯片都可以称为 AI 芯片。由于需求的多样性,很难有任何单一的设计和方法能够很好地适用于各类情况。因此,学界和业界涌现出多种专门针对人工智能应用的新颖设计和方法,覆盖了从半导体材料、器件、电 路到体系结构的各个层次。
该《白皮书》探讨的 AI 芯片主要包括三类:
1. 经过软硬件优化可以高效支持 AI 应用的通用芯片,例如 GPU ;
2. 侧重加速机器学习(尤其是神经网络、深度学习)算法的芯片,这也是目前 AI 芯片中最多的形式 ;
3. 受生物脑启发设计的神经形态计算芯片。

AI 技术的落地需要来自多个层面的支持,贯穿了应用、算法机理、芯片、工具链、器件、工艺和材料等技术层级。各个层级环环紧扣形成AI的技术链,而AI芯片本身处于整个链条的中部,向上为应用和算法提供高效支持,向下对器件和电路、工艺和材料提出需求。
针对应用目标是“训练”还是“推断”,把 AI 芯片的目标领域分成 4 个象限。

1. 云端AI计算
面向云端 AI 应用,很多公司开始尝试设计专用芯片以达到更高的效率,其中最著名的例子是 Google TPU,可以支持搜索查询、翻译等应用,也是 AlphaGo 的幕后英雄。

由于使用了专用架构,TPU 实现了比同时期 CPU 和 GPU 更高的效率。
针对云端的训练和推断市场,从芯片巨头到初创公司都高度重视。英特尔宣布推出 Nervana 神经网络处理器 (NNP),可以优化 32GB HBM2、1TB/s 带宽和 8Tb/s 访问速度的神经网络计算。 初创公司,如Graphcore、Cerebras、Wave Computing、寒武纪及比特大陆等也加入了竞争的行列。
此外,FPGA 在云端的推断也逐渐在应用中占有一席之地。
微软的 Brainwave 项目和百度 XPU 都显示,在处理小批量情况下,FPGA 具有出色的推断性能。目前, FPGA 的主要厂商如 Xilinx、Intel 都推出了专门针对 AI 应用的 FPGA 硬件(支持更高的存储带宽)和软件工具;主要的云服务厂商,比如亚马逊、微软及阿里云等推出了专门的云端 FPGA 实例来支持 AI 应用。
2. 边缘 AI 计算
边缘设备的覆盖范围其应用场景也五花八门。比如自动驾驶汽车可能就需要一个很强的计算设备,而在可穿戴领域,则要在严格的功耗和成本约束下实现一定的智能 。
目前应用最为广泛的边缘计算设备来自于智能手机,苹果、华为、高通、联发科和三星等手机芯片厂商纷纷推出或者正在研发专门适应AI应用的芯片产品。创业公司层面,主要为边缘计算设备提供芯片和系统方案,比如地平线机器人、寒武纪、深鉴科技、元鼎音讯等。
传统的 IP 厂商,包括 ARM、Synopsys 等公司也都为手机、智能摄像头、无人机、工业和服务机器人、智能音箱以及各种物联网设备等边缘计算设备开发专用 IP 产品。
自动驾驶是未来边缘 AI 计算的最重要应用之一,MobileEye SOC 和 NVIDA Drive PX 系列提供神经网络的处理能力可以支持半自动驾驶和完全自动驾驶。
3. 云和端的融合
总的来说,云和端各有其优势和明显短板。云侧AI处理主要强调精度、处理能力、内存容量和带宽,同时追求低延时和低功耗;边缘设备中的 AI 处理则主要关注功耗、响应时间、体积、成本和隐私安全等问题。
在实际应用中,云和边缘设备在各种 AI 应用中往往是配合工作。最普遍的方式是在云端训练神经网络,然后在云端(由边缘设备采集数据)或者边缘设备进行推断。随着边缘设备能力不断增强,云的边界逐渐向数据的源头,AI处理将分布在各类网络设备中,未来云和边缘设备以及连接他们的网络可能会构成一个巨大的 AI 处理网络,它们之间的协作训练和推断也是一个有待探索的方向。
二、突破 AI 芯片两大困境
《白皮书》第四章分析在 CMOS 工艺特征尺寸逐渐逼近极限的大背景下,结合 AI 芯片面临的架构挑战,AI 芯片的技术趋势。一方面,研究具有生物系统优点而规避速度慢等缺点的新材料和新器件,采用新的计算架构和计算范式;另一方面,将芯片集成从二维平面向三维空间拓展,采用更为先进的集成手段和集成工艺,将是 AI 芯片技术在很长一段时期内的两条重要的路径。
1. 冯·诺伊曼的“内存墙”
在传统冯·诺伊曼体系结构中,数据从处理单元外的存储器提取,处理完之后再写回存储器。在 AI 芯片实现中,由于访问存储器的速度无法跟上运算部件消耗数据的速度,再增加运算部件也无法得到充分利用,即形成所谓的冯·诺伊曼“瓶颈”,或“内存墙”问题,是长期困扰计算机体系结构的难题。
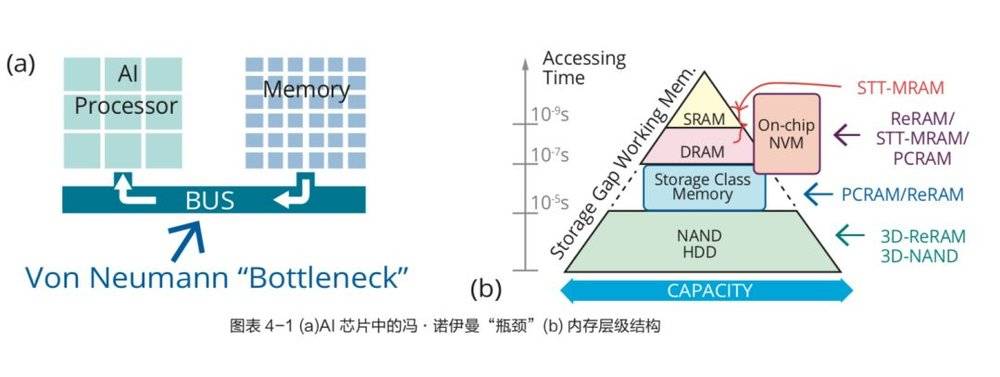
提高 AI 芯片性能和能效的关键之一在于支持高效的数据访问。目前常见的方法是利用高速缓存 (Cache) 等层次化存储技术尽量缓解运算和存储的速度差异。

从上图可见,AI 芯片中需要存储和处理的数据量远远大于之前常见的应用。 比如,在常见的深度神经网络的主要参数中,VGG16 网络需要 138M 个权重参数,一次推断过程需要 15.5G 次乘累加运算。
不夸张地说,大部分针对 AI,特别是加速神经网络处理而提出的硬件架构创新都是在和冯·诺伊曼的瓶颈做斗争。概括来说,在架构层面解决这一问题的基本思路有两种 :
(1)减少访问存储器的数量,比如减少神经网络的存储需求(参数数量,数据精度,中间结果)、 数据压缩和以运算换存储等 ;
(2)降低访问存储器的代价,尽量拉近存储设备和运算单元的“距离”,甚至直接在存储设备中进行运算。
2. 摩尔定律“失效”
由于基础物理原理限制和经济的原因,持续提高集成密度将变得越来越困难。目前,CMOS 器件的横向尺寸接近几纳米,层厚度只有几个原子层,这会导致显著的电流泄漏,降低工艺尺寸缩小的效果。此外,这些纳米级晶体管的能量消耗非常高,很难实现密集封装。
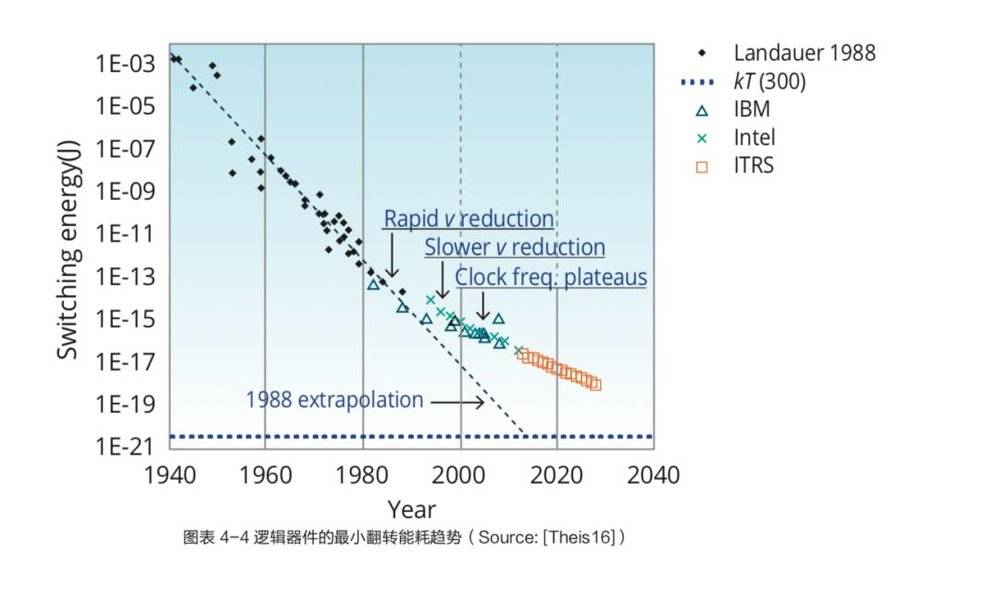
另外,目前 DRAM 技术已经接近极限,而物联网 (IoT)、社交媒体和安全设备产生的大量数据所需要的存储、交换和处理都需要大量的存储器。非易失存储技术的主力是 NAND 闪存,最先进的 3D NAND 具有多达 64 层和 256 Gb 的容量,预计于 2018 年进入市场。
由于 DRAM 和 NAND 闪存都是独立于计算核心的,即使采用最小的 SRAM 单元填充 1 平方厘米芯片面积的一半,也只有约 128 兆的片上存储容量。因此,我们有充足的理由开发提供大量存储空间的片上存储器技术,并探索利用片上存储器去构建未来的智能芯片架构。
在计算架构和器件层面,类脑芯片是一个不错的思路。神经元和大脑突触的能量消耗比最先进的 CMOS 器件还低几个数量级。理想情况下,我们需要具有生物系统优点而规避速度慢等缺点的器件和材料。
近年来,可以存储模拟数值的非易失性存储器发展迅猛,它可以同时具有存储和处理数据能力,可以破解传统计算 体系结构的一些基本限制,有望实现类脑突触功能。
三、架构设计之三大趋势
《白皮书》第五章讨论了建立在当前 CMOS 技术集成上的云端和边缘 AI 芯片架构创新。针对不同计算场景和不同计算需求,云端和终端芯片的架构设计趋势将朝不同的方向发展,而软件定义芯片已经成为灵活计算领域的主流。
1. 云端训练和推断:大存储、高性能、可伸缩
虽然训练和推断在数据精度、架构灵活和实时性要求上有一定的差别,但它们在处理能力(吞吐率)、可伸缩可扩展能力以及功耗效率上具有类似的需求。
NVIDA 的 V100 GPU 和 Google 的 Cloud TPU 是目前云端商用 AI 芯片的标杆。

(Cloud TPU 的机柜包括 64 个 TPU2,能够为机器学习的训练任务提供 11.5 PFLOPS 的处理能力和 4 TB 的 HBM 存储器。这些运算资源还可以灵活地分配和伸缩,能够有效支持不同的应用需求。)
从 NVIDA 和 Goolge 的设计实践我们可以看出云端 AI 芯片在架构层面,技术发展呈现三大特点和趋势:
(1)存储的需求 (容量和访问速度) 越来越高。未来云端 AI 芯片会有越来越多的片上存储器 (比如 Graphcore 公司就在芯片上实现的 300MB 的 SRAM),以及能够提供高带宽的片外存储器(HBM2 和其它新型封装形式)。
(2)处理能力推向每秒千万亿次 (PetaFLOPS),并支持灵活伸缩和部署。对云端 AI 芯片来说,单芯 片的处理能力可能会达到 PetaFLOPS 的水平。实现这一目标除了要依靠 CMOS 工艺的进步,也需要靠架构的创新。比如在 Google 第一代 TPU 中,使用了脉动阵列 (Systolic Array)架构,而在 NVIDA 的 V100GPU 中,专门增加了张量核来处理矩阵运算。
(3)专门针对推断需求的 FPGA 和 ASIC。推断和训练相比有其特殊性,更强调吞吐率、能效和实时性,未来在云端很可能会有专门针对推断的 ASIC 芯片(Google 的第一代 TPU 也是很好的例子),提供更好的能耗效率并实现更低的延时。
2. 边缘设备:把效率推向极致。
相对云端应用,边缘设备的应用需求和场景约束要复杂很多,针对不同的情况可能需要专门的架构设计。抛开需求的复杂性,目前的边缘设备主要是执行“推断”。衡量 AI 芯片实现效率的一个重要指标是能耗效率——TOPs/W,这也成为很多技术创新竞争的焦点。在 ISSCC2018 会议上,就出现了单比特能效达到 772 TOPs/W 的惊人数据。
在提高推断效率和推断准确率允许范围内的各种方法中,降低推断的量化比特精度是最有效的方法。此外,提升基本运算单元 (MAC) 的效率可以结合一些数据结构转换来减少运算量,比如通过快速傅里叶变换(FFT)变换来减少矩阵运算中的乘法;还可以通过查表的方法来简化 MAC 的实现等。
另一个重要的方向是减少对存储器的访问,这也是缓解冯·诺伊曼“瓶颈”问题的基本方法。利用这样的稀疏性特性,再有就是拉近运算和存储的距离,比如把神经网络运算放在传感器或者存储器中。
3. 软件定义芯片
对于复杂的 AI 任务,甚至需要将多种不同类型的 AI 算法组合在一起。即使是同一类型的 AI 算法,也会因为具体任务的计算精度、性能和能效等需求不同,具有不同计算参数。因此,AI 芯片必须具备一个重要特性:能够实时动态改变功能,满足软件不断变化的计算需求,即“软件定义芯片”。
可重构计算技术允许硬件架构和功能随软件变化而变化,具备处理器的灵活性和专用集成电路的高性能和低功耗,是实现“软件定义芯片”的核心,被公认为是突破性的下一代集成电路技术。清华大学微电子所设计的 AI 芯片 (代号 Thinker),采用可重构计算架构,能够支持卷积神经网络、全连接神经网络和递归神经网络等多种 AI 算法。
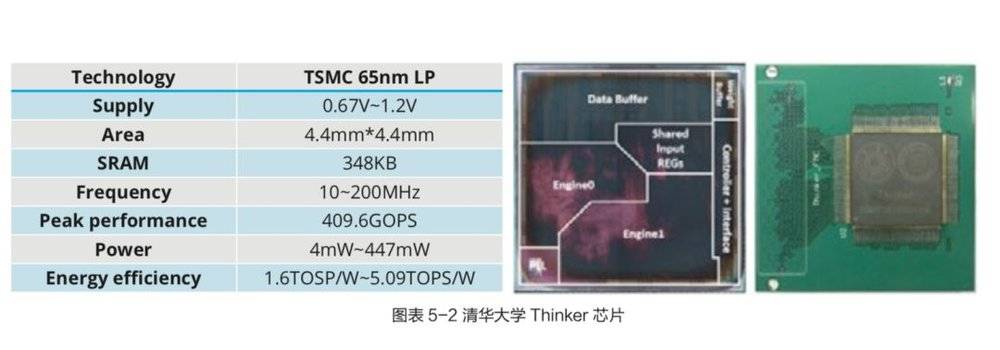
Thinker 芯片通过三个层面的可重构计算技术,来实现“软件定义芯片”,最高能量效率达到了 5.09TOPS/W :
1. 计算阵列重构:Thinker 芯片每个计算单元可以根据算法所需要的基本算子不同而进行功能重构,支持计算阵列的按需资源划分以提高资源利用率和能量效率。
2. 存储带宽重构:Thinker 芯片的片上存储带宽能够根据 AI 算法的不同而进行重构。存储内的数据分布会随着带宽的改变而调整,以提高数据复用性和计算并行度,提高了计算吞吐和能量效率。
3. 数据位宽重构:为了满足 AI 算法多样的精度需求,Thinker 芯片的计算单元支持高低(16/8 比特)两种数据位宽重构。高比特模式下计算精度提升,低比特模式下计算单元吞吐量提升进而提高性能。
采用可重构计算技术之后,软件定义的层面不仅仅局限于功能这一层面。算法的计算精度、性能和能效等都可以纳入软件定义的范畴。
四、新兴存储技术打开新思路
《白皮书》第六章主要介绍对 AI 芯片至关重要的存储技术,包括传统存储技术的改进和基于新兴非易失存储(NVM)的存储器解决方案。
可以预见的是,从器件到体系结构的全面创新或将赋予 AI 芯片更强的能力。近期,面向数字神经网络的加速器 (GPU、 FPGA 和 ASIC)迫切需要 AI 友好型存储器;中期,基于存内计算的神经网络可以为规避冯·诺依曼瓶颈问题提供有效的解决方案 ;最后,基于忆阻器的神经形态计算可以模拟人类的大脑,是 AI 芯片远期解决方案的候选之一。
1. AI 友好型存储器

上图显示了新兴存储技术中带宽和容量的快速增长。新兴的 NVM 由于其相对较大的带宽和迅速增长的容量,可以在 AI 芯片的存储技术中发挥至关重要的作用。对于嵌入式应用,NVM 的片上存储器也可以提供比传统 NVM 更好的存取速度和低功耗,可在非常有限的功率下工作,这对于物联网边缘设备上的 AI 芯片特别具有吸引力。
2. 片外存储器
3D 集成已经被证明是增加商业存储器的带宽和容量的有效策略,其可以通过使用从底部到顶部的硅通孔 (TSV)技术,堆叠多个管芯或者单片制造的方法来完成。DRAM 的代表作品包括 HBM 和混合存储器立方体(HMC)。

上图显示了 NVIDA 的 GPU 产品与 HBM 集成的 AI 应用程序。对于 NAND 闪存,3D NAND 正在深入研究。最近,三星已经开发出 96 层 3D NAND。
3. 片上(嵌入型)存储器
由于能够连接逻辑和存储器电路,并且与逻辑器件完全兼容,SRAM 是不可或缺的片上存储器,其性能和密度不断受益于 CMOS 的尺寸缩放。其易失性使得芯片上或芯片外的非易失性存储器成为必须。当前主要和新兴存储器的器件指标如下:
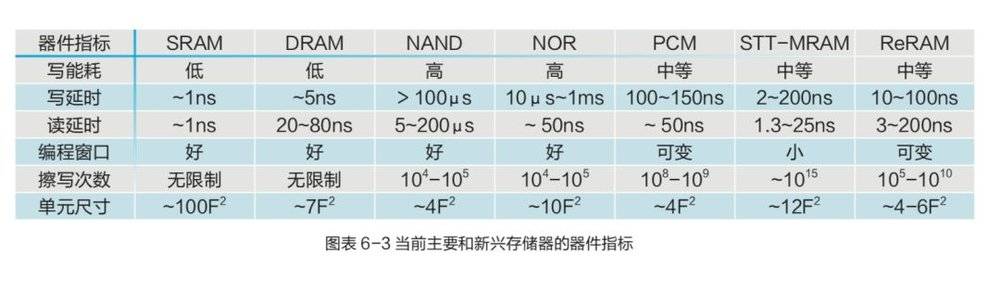
此外,自旋力矩传输存储器 (STT-MRAM) 由于其高耐久性和高速度被认为是 DRAM 的替代品。
五、五大计算技术开辟疆界
《白皮书》第七章重点讨论 AI 芯片在工艺、器件、电路和存储器方面的前沿研究工作,和以此为基础的存内计算、生物神经网络等新技术趋势。
虽然成熟的 CMOS 器件已被用于实现这些新的计算范例,但是新兴器件有望在未来进一步显著提高系统性能并降低电路复杂性。这其中包括近内存计算、存内计算,以及基于新型存储器的人工神经网络和生物神经网络。
基于新兴非易失性存储器件的人工神经网络计算最近引起了人们的极大关注。这些器件包括铁电存储器 (FeRAM)、磁隧道结存储器(MRAM)、相变存储器 (PCM)和阻变存储器 (RRAM)等,它们可用于构建待机功耗极低的存储器阵列。更重要的是,它们都可能成为模拟存内计算 (Analog In-memory Computing) 的基础技术,实现数据存储功能的同时参与数据处理。这些器件一般都以交叉阵列 (crossbar)的形态实现,其输入/输出信号穿过构成行列的节点。

上图就是一个 RRAM 交叉阵列的例子,其中矩阵权重被表示为电导。交叉阵列非常自然地实现了向量和矩阵乘法,使用图中集成 1024 单元的阵列进行并行在线训练,清华大学吴华强课题组在国际上首次成功实现了灰度人脸分类。
另一种更具生物启发性的方法是采用脉冲神经网络等,更严格地模拟大脑的信息处理机制。IBM TrueNorth 和最近宣布的英特尔 Loihi 展示了使用 CMOS 器件的仿生脉冲神经网络硬件实现。
六、神经形态芯片的终极梦想
《白皮书》第八章介绍神经形态计算技术和芯片的算法、模型以及关键技术特征,并分析该技术面临的机遇和挑战。
神经形态芯片 (Neuromorphic chip) 采用电子技术模拟已经被证明了的生物脑的运作规则,从而构建类似于生物脑的电子芯片,即“仿生电脑”。
广义上来讲,神经形态计算的算法模型可以大致分为人工神经网络(Artificial Neural Network, ANN) 、脉冲神经网络络(Spiking Neural Network, SNN) ,以及其他延伸出的具有特殊数据处理功能的模型。在没有历史记忆情形下,SNN 与 ANN 具有一定程度的等价性。
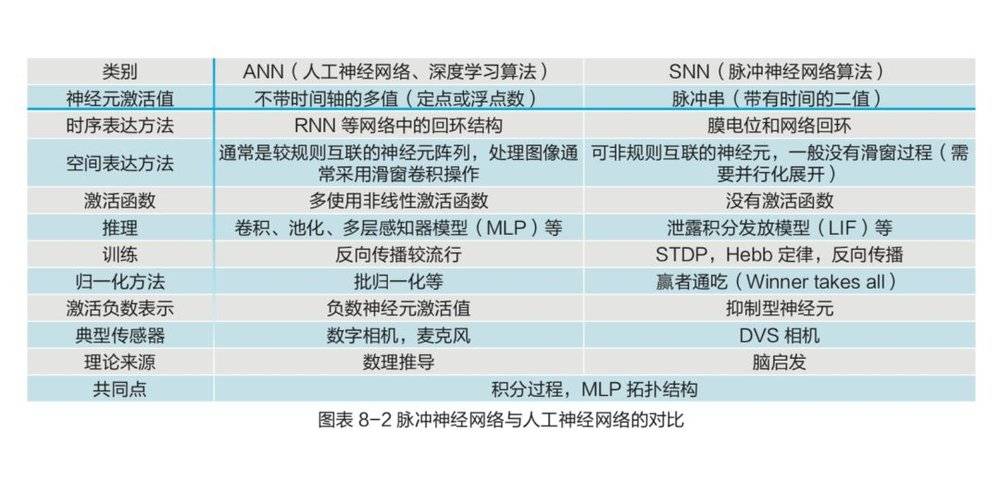
借鉴生物脑的互联结构,神经形态芯片可以实现任意神经元间的互联。即在指定规模的仿生神经网络下,任意一个神经元都可以把信息传递给指定的另一个或多个神经元。如此强大的细粒度互联能力是其他神经网络 / 深度学习芯片目前还无法做到的。
神经形态芯片在智能城市、自动驾驶的实时信息处理、人脸深度识别等领域都有出色的应用。如 IBM TrueNorth 芯片可以用于检测图像中的行人、车辆等物体,且功耗极低 (65mW)。它也可被用于语音、 图像数据集识别等任务,准确性不逊于 CNN 加速器芯片。此外,在线学习能力也是神经形态芯片的一大亮点。
研究人员已证明,与其他典型的 SNN 网络相比,在解决 MNIST 数字体识别问题上,英特尔 Loihi 芯 片将学习速度提高了 100 万倍。
在传统 CMOS 工艺下,神经形态芯片的物理结构较为成熟,但对于可以仿真大规模神经网络而言 (如 大于人脑 1% 规模的系统而言),仍存在很多挑战,包括:
(1)散热问题将导致单芯片规模无法继续增长,片上存储和积分计算单元的密度不够,导致集成的突触和神经元数量无法继续提升,功耗居高不下。
(2)由于其阵列众核的特性,在片上、跨芯片、跨板、多机等尺度下的互联和同步问题突出。
(3)为了提升密度,大多 ASIC 芯片可模拟的神经形态算法过于单一或简化,缺乏灵活性和模仿真实生物神经元的能力。
七、AI 芯片的测试判断
《白皮书》第九章探讨了 AI 芯片的基准测试和发展路线图。目前,我们还没有看到任何公开、全面的针对 AI 芯片的基准测试工作。业界对于 AI 芯片的评估主要靠运行一些常见的神经网络以及其中使用较多的基本运算来进行,比如由百度提出 Deepbench。
EXCEL 中心的研究人员 (由美国 NSF 和 SRC 资助) 正在积极研究非冯·诺依曼硬件的基准测试方法学,比如针对 MNIST 数据集的任务。为了应对面向 AI 应用的硬件基准测试的相关挑战,我们需要收集一组架构级功能单元,确定定量和定性的优值 (Figures of Merits, FoM) 并开发测量 FoM 的统一方法。
神经形态计算的材料和器件需要具备:
(1) 多态行为,能够根据过去的历史决定当前状态值 ;
(2) 低能耗,能以很低的能耗从一种状态切换到另一种状态 ;
(3) 非易失性:无需刷新就可以保持状态的属性 ;
(4) 阈值行为:受到重复激励后可以剧烈地改变某些属性 ;
(5) 容错性。
判断一颗基于某种特定器件工艺、电路形式和体系结构而实现的芯片好坏,在很大程度上取决于它针对的具体应用和算法 / 模型。为了对各种各样的器件进行基准测试,有必要明确目标应用、适用的算法和模型以及电路设计等信息。
只有提供足够详细的信息,才可以既不限制选择范围,又同时明确器件需求。
《白皮书》最后一章对 AI 芯片的未来发展进行了展望。由于人工智能技术整体发展还处于初级阶段,AI 芯片行业的发展也随之面临极大的不确定性。而这种不确定性恰恰为各种 AI 芯片技术创新提供了一个巨大的舞台,我们可以期待在这个舞台上看到前所未有的精彩表演。
(点击此处原文链接,获得报告全文。)