

对于很多AI芯片从业者来说,他们已经想要一套公正且好用的AI芯片评测(Benchmark)标准很久了。
提起Benchmark,很多人并不陌生,你肯定都曾在电脑或者是手机上用过它(最大概率可能是鲁大师和安兔兔)。但很多人不知道的是,国内某手机大佬口中的“不服跑个分”,其实并不是一项娱乐项目,而是计算机发展历史中一项重要的发明。

来,我们先让计算机重复计算20次3200万位的圆周率小数点吧!(8秒内就完成了)
数十年间,计算机经历的变化数不胜数,核心的CPU、GPU等计算核心,无论是基础的处理器逻辑、还是处理器微架构、亦或是具体的应用场景,都发生了翻天覆地的变化。因为这些不同,对比不同硬件、不同系统下的性能就变得异常复杂。
而Benchmark正是为这而生,它就是为了规避去对比不同硬件和软件环境造成的复杂不同,直接通过模拟实际应用的程序运行,直接去对比运行的结果,进而得出跨软硬件环境的具体应用性能对比指标。我们可以通过一个比喻来理解:假设十个各自语言不同且相互不不理解他人语言的学生,同时回答一道他们能够看懂的数学题,评估他们数学能力的第一步,其实是要先把他们的答案翻译过来。
或许你要问了,为啥我们要费这么大劲去做性能上的对比?

主要有两点原因,一个是对软硬件的指引作用,其次是反映特定用途下软硬件产业发展状况。我们可以再举个例子,在电脑的GPU领域,3DMark一直是最老牌、最权威的Benchmark,它通过让GPU完成各种预设的图形渲染任务来评估GPU的性能。正因为它的存在,我们才有了“显卡天梯图”的存在,通过不同版本的3DMark“协作”,你可以将过去10年里的各种型号显卡全部按照性能一一排列。
但很多人即便用过它也不知道的是,从1998年至今,它已经更新了12个版本,完整支持微软图形API DiretX从6.0以后开始的所有版本,测试的内容也在不断迭代。这些更新是比显卡制造商都要更早、更频繁的,换言之,其实3DMark也起到了“显卡性能发展风向标”的作用。
巧合的是,“标尺”和“风向标”,正是当下AI芯片领域最需要的两样东西。
AI芯片Benchmark,众所期盼
说到这个时候,我们再倒回来看AI,虽然看起来是新生事物,但AI的本质是很清楚的——在人的协助下,让计算机自行完成编程,进而实现一些超越人类编程能力的程序。
没错,它依旧是程序,也依旧需要计算。所以Benchmark对于AI芯片来说,作用其实跟CPU、GPU上的是类似的,但因为AI芯片领域的特点,也有一些细节存在差异。
首先第一点是“训练”与“推理”中Benchmark的地位截然不同。前两者作为AI中的两个主要环节,评测的对象完全不同。前者主要针对训练的效率,通常是直接利用不同的AI模型训练时间来对比;后者则是AI实际推理应用的推理能力,也是目前各家AI芯片厂商自说自话的环节。
有的AI芯片厂商选择用自己定义的操作数来描述芯片的推理能力,有的用理论的浮点数字来佐证,还有的则是直接根据自己的使用场景给具体结果,连可以拿来对比的数字成绩都省了。一个公正可信的AI芯片推理Benchmark,真的是众所期待。

现实中,是有人在做这样的事情的。更准确地说,他们是一队人,其中的研究人来自哈佛、斯坦福、加州大学、伯克利、明尼苏达大学、多伦多大学,提供支持的公司更是牛,包括了Intel、AMD、Google在内一大批AI芯片制造商。
这个项目的名字,叫做“MLPerf”。他们是这样描述自己的:
Mlperf的目标是建立一套通用的基准,使机器学习(ML)领域能够衡量从移动设备到云服务的培训和推断的系统性能。 我们相信一个被广泛接受的基准套件将使整个社区受益,包括研究人员、开发人员、机器学习框架的开发人员、云服务提供商、硬件制造商、应用程序提供商和最终用户。”
就在差不多一周前,MLPerf首次给出了他们Inference Benchmark 0.5(推理基准测试0.5)的介绍,和一部分测试结果。
推理基准测试0.5版介绍及结果
我们首先来看的这次推理基准测试的基础设置,概括起来就是“5种人工智能模型、4种场景”。其中5种人工智能模型中有4个是视觉类的,4个场景则覆盖了从手机到服务器的多种场景特征。
不夸张地说,这样的测试基准设置,基本完整覆盖了当下AI推理的所有可能应用情况。
接下来,自然是大家最关心的成绩。虽然我们上面提到了5种模型和4个场景,也就是说一个硬件平台最多能够有20个成绩,但因为不同的AI芯片设计都是有针对性的,在现实中并不需要支持所有组合。例如突出处理延迟但不突出处理任务量的Single Stream场景中,成绩主要来自SoC平台。而提供数据最多的,也正是Intel和NVIDIA这两家使用通用处理器来完成AI任务的公司。
也正是因为这种各家AI芯片都“选填”成绩的做法,让实际可以用来对比的成绩不多,处于让PK结果有意义的考虑,我们直接聚焦到竞争最激烈的战场,也就是结果最多的ResNet-50模型测试。
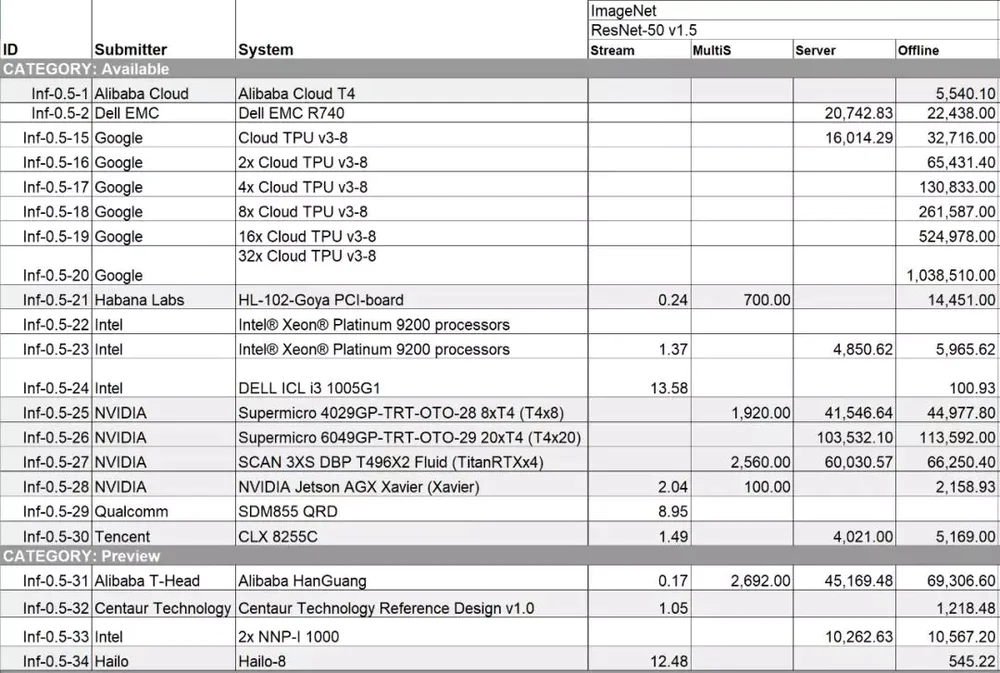
从数据的分布来看,Offline场景提交的结果最多,因为它是最好实现的场景(也应该是大部分AI专用芯片测试时首先实现的场景)。在这个模型/场景组合中,这次最吸引眼球的当然是阿里的含光芯片,实现了单芯片69,306.6这个惊人的数据。除此之外,含光在ResNet-50其它几个场景的数据也是遥遥领先,非常强悍。
Google这次提供了多种TPU配置(1-32个Cloud TPU v3)的结果,并且由“32x Cloud TPU v3-8”系统得到了全场最高的1,038,510。NVIDIA这次则通过自己和第三方给出了多种T4组合的成绩,分别是5,540.1(单芯片,阿里云)、22,438(4芯片,Dell)、44,977.8(8芯片,NVIDIA)、113,592(20芯片,NVIDIA)。另外,NVDIA还提交了TitanRTX和Jetson AGX Xavier的数据,但这两款产品并不主要运用在推理领域,基本可以忽略。
从目前来看,同属于同一个芯片设计思路(直接堆脉动阵列计算能力)的Google TPU v3和阿里平头哥的“含光”,是目前理论能力最强的AI推理处理器。但我们也可以看到,NVIDIA的T4虽然在AI绝对性能上比不过前两家,但在“Sever”场景下,内部配备了更多芯片模块,支持更多应用的NVIDIA T4的性能较“Offline”的下降是最小的,这其实就是优化功夫做好的表现。
最后是其他一些“参赛者”,例如Intel自己偷偷拿出来的NNP-I,这款产品目前仍很神秘,两颗芯片10567的成绩也不算出众,但至少算是“有点东西”了。还有一些CPU和国外非头部AI芯片公司,没啥太大的意义,我们先暂时把它们忽略。
原来无从下手对比的几家公司,通过MLPerf这把新“标尺”,一下子就变得可以对比起来。只要不出幺蛾子,MLPerf继续保持现有发展状态,成为行业公认的评判标准,那么它自然而然地就会成为未来AI芯片全局发展的“风向标”。
到那个时候,你就再也不会因为数量众多的玩家和数量众多的AI芯片无法对比而犯愁了。
AI芯片Benchmark的启示?
作为一个全新的测试项目,MLPerf能在0.5版就给出这些测试结果,已经算是“完成了任务”。但仍有可惜之处:国内的AI芯片初创公司都没有参与到这个测试当中来,究竟自家的AI芯片性能如何?是时候拉出来“溜溜”了。
另外一点是在这一版测试中,只给出了性能指标。虽然这个性能指标看起来已经将各家的产品分了高下,但它仍是不完整的,因为最终应用时,大家最终考虑的肯定是效率。也就是达到这样的性能所花的代价,比如需要消耗多少能量,投入多少成本等等。
但同样的,因为目前AI推理场景覆盖了从手机到云端的整个链条,这个功耗的测试比较十分复杂。可能要看未来MLPerf怎么来解决这个问题。
最后是启示,我们在开篇中已经提到了Benchmark可以反过来引导行业的发展,本次的0.5版本中,我们其实从提交了的成绩中总结3点结论:
NVIDIA依旧是那个爸爸,覆盖了训练到推理、云到端全场景,除了绝对的计算能力之外,软件支持NVIDIA最好;
目前其他AI芯片公司无法跟NVIDIA这样的巨头PK,可以选择更加窄、应用更加垂直的AI推理赛道。
AI芯片创业公司,目前在“Sever”、“Offline”这两个榜单中很难取得好的成绩,提前布局“Steam”和“MultiS”榜单比较重要。
评论