

热豆腐,是真的会烫嘴的。事先说明,本文仅代表个人观点。

本周三开幕的阿里云栖大会上,身为中国互联网巨头的阿里一口气带来了许多的重磅消息。其中最重磅的,肯定就是阿里平头哥的首款AI芯片——“含光800”了。在发布现场达摩院院长张建锋专门表示:“含光800”是目前“全球最高性能AI推理芯片”。

估计是哪个兼职外包不负责任了
有趣的是,在阿里官方制作的宣传长图中,“含光800”的宣传字眼就变成了“全球最高性能AI芯片”。可能真的是长图版面不够的原因吧。
这颗被阿里置于聚光灯下的芯片到底成色几何?
基于发布会、现场采访、第三方了解到的资料,我有了一些自己的看法,整体的结论是——“含光800”对于阿里自身AI能力的实现与发展意义有限。这不禁令人感到有些可惜。
接下来,我们细细来分析。
“含光800”芯片的各种信息
目前“含光800”的官方信息主要来自两个地方:阿里云栖大会上的keynote演讲、阿里云栖大会上的“人工智能芯片技术论坛”,而就在发布的当天,我自己还专门跑到了平头哥的展台,通过问答交流的形式获得了更多的信息。

先再来总结下keynote演讲中的信息,核心的其实是“含光800”跟其他几款AI芯片的性能和功耗对比。
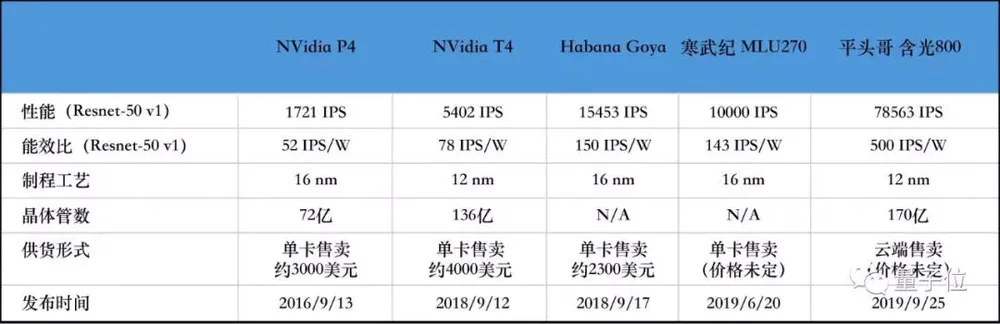
本表格图片转载自公众号“量子位”
作为对比项的另外4款产品分别是“AI Chip 1”、“AI Chip 2”、“GPU 1”、“GPU 2”。虽然阿里没有直接给出这四款产品的具体型号,但从国内某提前拿到阿里“含光800”芯片的新媒体的配置对比列表中,我们可以看到,实际上对比的4款产品为“NVIDIA P4”、“NVIDIA T4”、“Habana Goya”、“寒武纪MLU270”。
其中P4、T4是NVIDIA针对训练场景推出的云端AI加速卡,Goya是国外创业公司Habana推出的一款AI云端推理加速芯片,MLU270则是国内创业公司寒武纪推出的云端AI加速芯片。乍一看,似乎没什么问题。
而就性能对比的指标而言,阿里使用的则是Resnet50,一种最常见的CNN神经网络运算。单颗“含光800”1秒就可以对接近8万张照片进行Resnet50 AI计算处理。虽然阿里并没有提供常见的浮点运算指标,但拿来作为性能参考还算客观。
在实际应用上,张建锋演讲中主要突出的是两个:一个是杭州的城市大脑交通视频处理,另外一个淘宝拍立淘的图片识别。从阿里公布的数字来看,性能、功耗表现都有提升。
然后是当天下午、规模小一些的“人工智能芯片技术论坛”,期间透露了更多关于“含光800”的基础信息。援引知乎用户“甜草莓”昨天在现场的部分记录(已获得作者授权),我们整理出了其中比较重要的内容(也推荐大家去完整阅读相应回答):
这款芯片主要是针对目前阿里电商的图片识别(拍立淘)、城市大脑、语音识别、机器翻译场景做的优化。
这颗芯片同时支持Int8、Int16浮点运算精度,其中Int8主要用于CNN计算,Int16用来支持非CNN计算。
芯片中有4个核心,每个核心里面都有负责计算的Tensor array,以及配套的高速片上内存。阿里希望这颗芯片能够覆盖云到端整个场景的推理能力,据说芯片功耗能够在25W到276W之间波动。
这颗芯片预计今年Q4量产。

现场拍的“平头哥”展位图
最后,我现场跟偶遇的身着达摩院T恤的平头哥员工聊了大约十多分钟,对方透露出来的更多细节:
这颗芯片Int8模式下,浮点运算能力接近Peta TFlops(坊间计算推测在800Tera Flops左右);
这颗芯片在阿里内部的定位,也是云端专用的推理加速模块;
“含光800”芯片暂时不具有大规模互联的能力;
芯片内部无视频编解码模块,编解码任务交由外部CPU处理;
单颗芯片峰值的视频AI计算,需要有两颗英特尔至强CPU进行辅助的编解码处理;
平头哥内部也在进行训练芯片的研发,未来可能会公布相应产品。
基础信息列完整了,接下来进入真正的分析。
“含光800”身上的几点疑问
既然开头已经说了整体的结果,我们直接就以疑问的形式来进行分析好了。
1、阿里为何违背行业发展趋势,打造单芯片大算力的推理芯片?
就目前而言,云端已经有多颗AI芯片,大体又可以分为训练和推理两大类。
两者其实就是现阶段以神经网络为核心的AI应用过程中的两个关键步骤,训练需要利用大量数据、多种策略来训练神经网络模型,所以核心的需求是大容量、高带宽的存储空间,以及充足的、能够适应多种神经网络模型训练的计算能力。简单点概括,就是计算和存储都是“越大越好”(前提是云端)。
鉴于最近这些年半导体制程的不断放慢、AI计算的逐渐成熟,甚至出现了AI训练芯片跟不上需求的现象,于是乎在人工智能芯片界两大巨头英伟达和Google,不约而同地都开始尝试用高速的芯片间链路将A芯片的计算能力、存储内容链接起来,以降低一定效率的基础来换取单个计算单元(许多个芯片通过网络共同组成)更大的计算能力和存储能力。

华为Atlas 900——全球最强的AI训练集群
这也是为什么,NVIDIA选择在今年3月去专门花69亿美元收购了Mellanox,后者的看家本领就是云端的大规模高速网络传输解决方案。就连华为最新用昇腾910搭建的世界最强AI训练集群Atlas 900,也配备了Mellanox的RoCE技术。
说完训练,再来看推理。
虽然同是“AI运算”,推理的计算需求和存储需求其实完全不同,因为神经网络已经在训练阶段完成,所以推理阶段关键的就是需要足够大小、用于存储神经网络和计算对象的存储能力(可以放在芯片外部来做),以及运行神经网络所需要的计算力。

NVIDIA T4推理加速卡
典型的产品就是被阿里拿来对比的NVIDIA P4、T4,这个系列还包括一款2015年发布的M4,数字前面不同的字母代表的是NVIDIA最近几代GPU英文代号的首字母(Maxwell、Pascal、Turing)。
这三款产品面对的都是云端市场,尽管芯片的架构、运算力等参数都发生了变动,但是整体的设计思路仍保持一致:利用PCIE接口(目前应用最广泛的计算机高速传输接口)本身的传输带宽,以及供电能力打造人工智能推理加速模块,同时还要满足云端对于灵活性、扩展、散热、成本在内的一系列需求。
这一设计思路也已经被其他AI芯片制造商、云端服务器制造商所采纳,并且相当数量的同档位产品已经被推向市面:华为Atlas 300、寒武纪MLU100/MLU270 S4、Xilinx U50,服务器方面目前最强的就包括华为的Atlas G5500/G2500系列推理服务器。以华为Atlas 300和Atlas G5500的组合为例,能够在4U(服务器厚度单位)的高度内放下32张加速卡,实现极其密集的AI推理能力。
而在云端场景之外,诸如NVIDIA、Google、华为还专门打造了性能等级更小、功耗表现更好的推理芯片,并且还在不断制作成更小的应用模块。典型的例子如NVIDIA的Xavier、Jetson,以及华为的Atlas 200。
结合上面这么多云端的AI芯片产品来对比,阿里这颗“含光800”芯片的做法就很奇怪了——在云端做推理,同时还要单芯片大算力,同时芯片本身还不具有高速的数据链路。
这种做法虽然可以完成AI任务的处理,但是坏处同样明显:单芯片更大的面积意味着更低的芯片良率、更高的芯片打造成本;单芯片强大,但是影响了云端部署的灵活性,按照官方的说法,低负载情况下可以关闭部分芯片,但关闭的芯片部分同样是需要成本的;更大的训练芯片需要更大的数据带宽传输,在云端实际部署时,训练卡之外的硬件容易出现瓶颈,反而影响系统的整体的效能。
2、阿里这颗芯片并没有比竞品先进很多?
先说英伟达的两款,的确是英伟达官方针对推测场景推出的加速卡。但作为现在全球人工智能生态最成熟、也是最全面的巨头的两款产品P4、T4支持全部类型的神经网络(支持从FP32、Int16、Int8、Int4在内的多种运算模式)。同时也因为基础架构上与英伟达人工智能训练场景中的V100 GPU等大芯片共通,人工智能开发者也能够快速地将在V100 GPU上面训练所得的人工智能神经网络转移到P4、T4上,加速人工智能在不同领域的前沿应用。
至于“Goya”,Habana官方给出的定位的确是“推理芯片”,在四个对比者当中“Goya”也是与“含光800”最相近的一个,同样也是主打提供AI计算能力。假如能跟“含光800”一样的12nm制程(晶体管密度和频率都可以提升,功耗还能降低),整体功耗也放大到与后者一致的接近300W,“Goya”是不是性能就会跟“含光800”差不多甚至更高?这显然是非常可能的(当然,也不是单纯堆叠那么简单)。

最后是国内创业公司寒武纪的“MLU270”,这的确也是一个云端的推理芯片,但它比“含光800”更专一,针对安防市场而打造。整个加速卡都专门为视频流结构优化过的。根据寒武纪的资料,MLU270一张卡就能自身处理多达48路1080p视频。换句话说,云端服务器插上MLU270,机器本身的CPU、存储系统其实基本都不需要占用太高的负载,只需要将通过网络传输过来的视频流直接交给MLU270就行。
这个时候我们再来看专门说自己应用场景包括了杭州街头交通场景的“含光800”,却是没有编解码能力的。而根据虎嗅在现在了解到的内容,“含光800”在处理视频分析时,会又服务器上面的Intel至强CPU进行先期处理。因为“含光800”的“强大”,足足需要两颗Intel至强CPU才能完成编解码的需求。
这两颗同样参与到AI运算里面来的CPU,同样也是有功耗的,以英特尔的服务器端次旗舰CPU Platinum 8280为参考,一颗CPU的满载功耗就有205W,两颗CPU加起来就是410W。显然阿里应该是没有把这部分的功耗算入公布的功耗对比中。
值得一提的是,英伟达的两款小加速卡同样也是内置了编解码处理器的,处理能力也有38路之多。

平头哥在现场的展示就是AI视频应用
换个方向想,假如阿里真的就不拿这张卡来做视频的AI处理,而只是处理不需要复杂的编解码过程的图片呢?拍立淘显然属于这样的场景。根究张建锋在现场的分享,阿里利用“含光800”芯片打造的这套系统能够在5分钟内完成拍立淘10亿张照片的图片识别任务。
碰巧的是,在云栖大会的另外一个keynote当中,另外一位演讲者偏偏又公布了几个关于阿里巴巴AI使用情况的统计数字。在日处理图像一项中,对应的数字刚好也是10亿张。

结合起来,就是说“含光800”真正能够高效处理的图片任务,只要5分钟就运转完了,空下来的其他时间怎么办?还是只能拉上CPU陪太子一起读书?(“5分钟这个数字估计也是按照性能,通过计算得出来的,而非实际全系统部署表现”)但如果是别的云端AI加速卡,就例如NVIDIA T4,你可以做的推理任务种类就多了去了,更不要说NVIDIA早早已经用TensorRT这款配套软件为GPU优化了各种的人工智能架构,这方面阿里必然不如NVIDIA。
当然,一般人都看不到这些细节。大家能够看到的只有阿里官方那张长图上面的“含光800”等于10颗GPU,甚至有的新媒体还嫌NVIDIA T4太新,直接用上一代的NVIDIA P4数据来对比,写出了“阿里平头哥首款AI芯片发布!46倍于英伟达P4,刷新全球推理性能最高纪录”这样的标题。
3、“含光800”对阿里未来的AI能力发展起多大价值?
结合刚才第二点中的分析,尤其是“含光800”对于外界计算力和存储能力的依赖,它的真实定位其实更接近手机SoC芯片中的AI加速模块,而且还是用途非常专一的那种(例如处理图像的DSP、ISP)。
这种做法目前在AI芯片领域,只有极少的公司会选择这种模式,就以上文提到的、自身产品思路跟“含光800”相近的Habana,其实也另外推出了自己的云端AI训练芯片,在实际的解决方案中也同样运用上了Mellanox的RoCE网络方案。

相比之下,阿里这次直接单独丢出一个超强的推理芯片,没有训练芯片配套、没有训练能力、没有高速网络,更绝口不提在应用方案中对于外部CPU的依赖。这种做法只有两种合理的解释,要么阿里有充足的信心,在整个半导体系统(包括服务器、各种处理器、通信等等)中部署一整套自己的、专用而又优化的解决方案;另外一种情况或许是,阿里或者说是平头哥,就没打算发展AI芯片业界所默认的种种能力,而打算另辟蹊径呢?
此外一点不能不提到的,是张建锋演讲中提到的一句话:“平头哥用大概一年半的时间实现了含光800从设计到商用。其中7个月完成了前端设计,之后用3个月就成功流片。”
一年完成一颗芯片从设计到流片的全过程,这在现今各种前沿芯片动辄5、6年(英伟达的GPU架构一般提前5-6年开始研发)提前研发、优化的大背景下,可谓神迹。张建锋在现场给出的解释是:“得益于阿里在软硬件方面的积累”。只能说,是我们之前想的、做的、见识的,都太保守了。
当然,我这里还有另外一个版本、我自己认为更有可能性的脚本。“含光800”之所以能够1年完成一切,理由就两个字——简单。没有复杂的频繁外部存取需求、没有复杂的编解码器打造需求、本身的架构简单,芯片的制造也会拥有更高的良品率,进一步加快芯片的流片速度。
对于这样一款产品,我实在想不出它能对阿里未来的AI能力发展起多大作用。即便往多了说,也就是让平头哥的员工又跟台积电好好对接了一次业务,算是为未来的芯片流片积累了点经验吧。
差点忘了说一个数字,虎嗅咨询了国内几家已经在台积电(TSMC)流过片的创业公司,根据他们预估,这颗芯片整体的流片成本应该在500万美元以上。鉴于半导体行业的特性,这个数字仅能作为参考。
阿里造芯,为何如此着急
在这个倡导芯片自主的历史阶段,阿里的确需要赶紧交上份看起来不错的成绩单。
只是这事儿急不来。
显然,在造AI芯片这件事上,流淌着互联网公司DNA的阿里与拥有工程师DNA的华为,已经走出了截然不同的道路。作为中国最有希望大规模应用和普及AI能力的两类巨头,日后必然会分个高低。从目前的进度来看,拥有已经成立了接近20年的海思的华为,客观来说,进展更好。
资本市场也挺现实的,就算你们发了个芯片,股价也没涨,这几个意思?
再次重申,以上均为个人观点。
评论