
文 / 王守崑
进入2016年,Chatbot 无疑已经成为互联网业界和投资领域的热点之一。在短短几个月的时间之内,行业巨头微软、Facebook、亚马逊、Google 和苹果纷纷发布了各自在 Chatbot 领域的战略和相关产品。
3月,微软在 BUILD 大会上发布聊天机器人框架 Bot Farmework;
4月,Facebook 在 F8大会上展示了 Messenger 平台,Telegram 宣布为机器人开发者设立奖金;
5月,Google 在 I/O 大会上正式推出 Google Assistant,同时发布了 Allo Messenger 以及语音家用音箱;Amazon 把智能音箱 Echo 背后的大脑 Alexa 开放出来,让用户可以通过浏览器使用;
6月,苹果在 WWDC 大会上开放 iMessage 给第三方集成,并且发布了 Siri SDK;IBM 的第一个法律机器人已经被华尔街雇佣;
最近,Yahoo 也不甘寂寞在聊天工具中发布了第一款 Chatbot — Kik Messenger。
至于 Chatbot 领域的创业公司,更是如雨后春笋般层出不穷。VentureRadar 总结了截止到6月份 Chatbot 领域最受瞩目的25家创业公司,所处的行业也是五花八门:包括个人助理、客户服务、招聘助手、品牌沟通、虚拟买手、保险代理以及机器人平台等等,大都拿到了天使或 A/B 轮融资,一派欣欣向荣的景象。

25 Chatbot Startups You Should Know, Andrew Thomson, June 14, 2016, Venture Radar
Chatbot 历史
追根溯源,Chatbot 并不是个新鲜的概念。
上点儿年纪的 IT 从业者很多都知道 ELIZA,这是上世纪60年代一位 MIT 的教授 Joseph Weizenbaum 开发的人工智能机器人,可以和人进行简单对话,但更多的时候可能你看到最多的回复是“What are you saying about…” (可以在 GNU Emacs 中运行 M-x doctor 唤出 ELIZA 的一个版本分支 DOCTOR)。
上个世纪90年代微软为 Office 软件配备的虚拟助手 Clippy(回形针),可能是最早大规模推向市场并接触到主流人群的 Chatbot 原型,它可以在用户使用 Office 软件的过程中提供对话形式的帮助,不过很多用户对它的评价是“intrusive and annoying”(冒冒失失令人讨厌),也正是因为反对的声音太多,2003年它就正式下线了。
进入二十一世纪,一款名为 A.L.I.C.E (Artificial Linguistic Internet Computer Entity)的聊天机器人吸引了行业目光,它嵌入了 AIML(Artificial Intelligence Markup Language)并结合一系列启发式规则重写了后台的处理引擎,大大改善了对话质量。由于和同类应用相比显著的优势,AliceBot 三次获得了 Leobner Prize ——机器人领域最重要的奖项之一。
遗憾的是,无论是 ELIZA 还是 ALICE,离通过图灵测试都还差得远。任何人跟他们聊上几句就会发现其中的破绽,或者答非所问,或者掉进明显的模式循环之中,感觉都是套路。
由于对话质量不尽如人意,以及应用场景的缺失,Chatbot 在过去的十年间并未吸引太多的注意,仅仅是作为一项有趣的、半科幻的不太成熟的玩具存在着。
从2016年3月份开始,如本文开始所提到的,巨头们的介入使得 Chatbot 以一种意想不到的方式迅速成为各个科技媒体和开发者社区讨论的焦点。
进入6月份,不光是科技和风投界的媒体,Forbes、Fortune、Financial Times 这些老牌的商业媒体也把目光投了过来,纷纷讨论 Chatbot 的广泛应用到底能够给目前的商业环境带来什么样的影响。难道真的是一夜之间 Chatbot 相关的技术发生了天翻地覆的变化,你手机里的 Siri 从一个呆萌的应声虫摇身一变,成为了无所不知无所不能的百事通?
先不忙下结论,我们看看过去几年,互联网的商业和技术环境中都发生了什么。
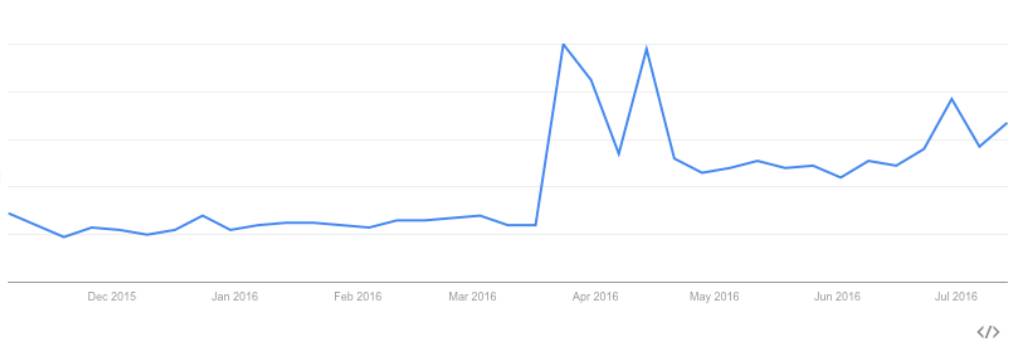
“chatbot” 在 Google Trends 上的热度随时间变化趋势
网络生态与技术变革
过去5年间,消息服务无疑是增长最快的网络应用。内有微信,外有 What’sApp、Facebook Messenger,月活超过6亿,在过去几年中成功占领了绝大部分用户的碎片时间,成为新的、事实上的移动互联网时代的“浏览器“入口。
并且,和 web 时代相比,由于移动应用的封闭性,缺少网页之间彼此互通有无的超链接作为联系纽带,移动互联网环境下的信息孤岛效应更加明显。据统计,当前平均每个用户手机上应用的数量大约是55个,平均每月使用的应用数量大约是23个,每天使用的数量大约是12个。不过,其中大约有一半左右的使用时间给了排第一位的应用,80%的时间给了排前三位的应用。
这种比”二八原则“还要夸张的注意力分配还造成了一个尴尬的事实,下载移动应用所带来的流量红利正在慢慢消失。在北美市场,2015年5月到2016年5月全年的移动应用下载量比前一年下降了20%(全球的数字为增加2%,主要由新兴市场贡献),并且,大约有65%的用户在过去一个月中没有下载任何应用。
在这样的大趋势下,大家意外的发现,Chatbot 似乎可以解决 App 生态环境面临的一系列困境。Chatbot 开发成本低,而且是真正的跨平台,不必考虑 Android/iOS 资源的投入。
在移动时代成长起来的用户天然接受即时消息通讯的方式,进入门槛低、粘性高,依附于大的平台,似乎是可以绕开 App 越来越低的下载率和活跃度的问题。消息服务作为 Chatbot 天然的载体,俨然已经成为移动生态环境的基础设施;那么,Chatbot 作为消息服务之上最自然的应用,会不会取代 App,构建出自己的生态环境?
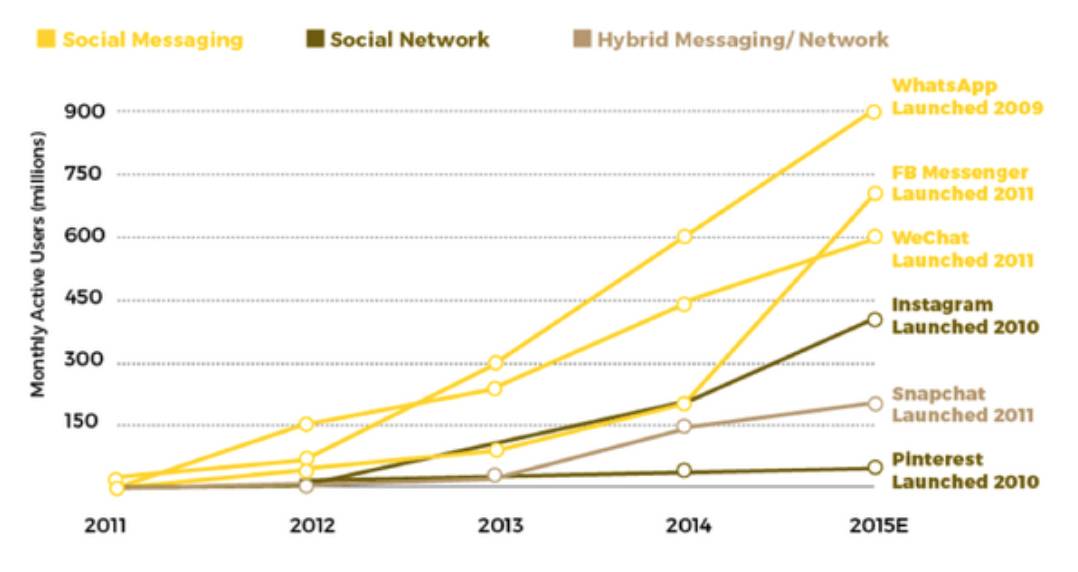
Source: Business Insider, Fortune, Mashable, AppAnnie, AdWeek, Quartz, Yahoo Finance, Experian, TechCrunch, Forbes, Tehc in Asia, eMarketer, Compete, Activate analysis
在技术层面,人工智能以一种出人意料的方式重回大众视野。
2016年3月,Google Deep Mind AlphaGo 在五番棋中以压倒性的优势击败世界冠军李世石,人工智能在围棋领域战胜人类顶尖棋手,这在5年前还是遥不可及的梦想,如今却成为现实。
事实上,自上世纪五十年代现代意义的人工智能诞生以来,已经至少经历过两次大起大落,也分化出大大小小各种流派,在最近一次低潮期,从业者们甚至更愿意用“数据挖掘”、“知识推理”、“机器学习”或“统计学习”这样的字眼来指代自己的工作,小心的避免使用“人工智能”这样过于耀眼承载了太多希望的词语。
2006年至今深度学习技术的飞速进展,无疑是当前这次人工智能崛起的最重要基石。多层神经网络在计算机视觉和语音识别领域已经取得突破性进展,在效果上比之前的方法有了质的飞跃。比如在图像识别领域的 ImageNet 竞赛中,2012年 Hinton 研究小组利用 GPU 跑的深度卷积神经网络算法远远超过了原有的各种机器学习方法,识别率甚至超过了人类。
包括原本认为很难突破的围棋,机器在原本人类擅长的领域表现得更加优异,所带来的心理冲击无疑是全方位的。验证了深度学习的威力之后,人们自然而然的希望扩展到各个领域,特别是一直自成体系,也公认难度很高的自然语言处理。
自从现代计算机概念诞生的第一天开始就对人类的语言处理问题有着强烈的兴趣,著名的图灵测试,也是围绕着测试者能够在多大程度上区分机器还是人类产生的语言来设计的。而 Chatbot 所做的事情,恰好综合了自然语言处理技术的各个方面。借人工智能崛起的这一波东风,一举突破当前在 Chatbot 领域面临的各种瓶颈,甚至通过图灵测试,也似乎不再是遥不可及的事情。
此外,自然语言作为人机交互界面,这无疑是比从鼠标键盘到触摸屏还要令人激动的巨大变革,彻底把各种智能设备的使用门槛降低为零。并且,如果能够在理解文本语义的基础上自动进行下一步动作,很多繁琐、重复的文字类的人工劳动将被自动化的机器取代,释放出的市场潜力无疑是非常巨大的——这会不会是“The next big thing”?看起来市场环境和技术各自沿着自己的轨道向前发展,在这个时间点双方交汇到了一个点上。
也正是因为这样的原因,在 Chatbot 领域巨头们争相投入,从前沿的算法研究到底层的基础设施平台搭建,从面向普通用户的最终应用到面向开发者的一线列工具,迅速成型并投入使用,唯恐在未来的竞争中落了后手。无论前景如何,从客观上来看,至少目前我们能够便捷的使用一系列平台和工具,使用这些工具,搭建一个 Chatbot 要比开发一个移动应用、或者是建个网站快得多。
Chatbot 相关技术
从应用的场景来看,Chatbot 可以分为开放域(Open-Domain)问题和封闭域(Closed-Domain)问题两大类。
开放域问题和图灵测试更接近,也更困难。没有任何限定的主题或明确的目标,用户和 Chatbot 之间可以进行任何话题的自由对话。可想而知,由于话题内容和形式的不确定性,开放域 Chatbot 要准备的知识库和模型要复杂很多。
并且,从实际的应用场景来看,开放域 Chatbot 更多应用在聊天、虚拟形象等泛娱乐领域,虽然用户基数比较大,也容易传播,但由于目的性不强、内容深度不够、对话质量不高等等一系列问题,用户粘性有限、商业价值较低,至少在目前的市场环境和技术水平之下,看不到明确的应用前景和清晰的商业模式。
和开放域问题不同,封闭域问题通常有若干明确的目标和限定的知识范围,也就是说,Chatbot 所面临的输入和输出通常是有限的。虽然这个限定范围会随着问题领域以及对推理深度要求的不同变化很大,但无论如何,与开放域问题相比,问题空间大大缩小,目标也更加清晰明确。
特别是从应用场景上来看,用户不会期待和一个客服机器人谈论历史知识,也不会向一个电商导购机器人提各种与购物无关的刁钻古怪的问题。并且,更加垂直和场景化的应用使得封闭域的 Chatbot 从诞生的第一天开始就肩负了商业使命,无论是节省人力成本还是提升人工效率,问题的定义和评判标准都是比较清晰和明确的。
不过,也正是因为如此,封闭域问题 Chatbot 对对话错误的容忍度更低、对质量要求更高,这就要求 Chatbot 能够整合更多的领域知识、用户的基本信息,以及对上下文语境的分析和判断。并且,针对一个领域建立的模型和知识图谱,往往是很难方便的迁移到另外的领域。在这些因素的共同作用下,建立一个封闭域的 Chatbot 就不再单单是一个技术问题,而是融合了商业、产品、运营、数据知识积累和模型调优等等方方面面的权衡和综合考量。
从表现形式看,Chatbot 可以分为单轮对话和多轮对话两种类型。
单轮对话其实可以看做是问答系统(Question Answering System)的变形, 一般是一问一答的形式,用户提问,机器生成相应答案的文本或者是综合与答案相关的各种信息返回给用户。
多轮对话则更接近我们通常理解的人与人之间的对话模式,通常是有问有答,除了用户提问,机器也会主动向用户询问,并且会根据上下文来判断该给出什么样的答案或提出什么样的问题。
从应用的角度来看,单轮对话更适合使用在信息查询、客户服务、产品介绍等等目标明确、会话行程短的浅服务类项目,用户对通过使用这类产品获得的服务有明确的预期,更多的是把它看做快速获取信息、提升效率的入口。
而多轮对话服务,往往会应用在信息搜集、商品和服务导购推荐、专业方案咨询等等一系列结构复杂、会话行程长的深度服务项目里,用户通过使用这类产品会在某一领域获得相对完整的服务,解决一个复杂问题,或者获得某种方向性的引导。一般来说,企业使用多轮对话服务的目标不仅仅是提升效率降低成本,还往往可以改进产品质量带来更多的收入。
从技术的角度看,实现一个 Chatbot 也可以大致分为基于检索的模型和生成模型两种方案。
基于检索的模型在算法流程和结构上相对更容易理解,在很大程度上和搜索引擎的技术实现类似。一方面事先定义好了问题库和答案知识库或回答的模板,另一方面通过 NLP 技术对用户提出的问题进行分析,通过关键词提取、倒排索引、文档排序等等方法与定义好的知识库进行匹配,并返回给用户。
事实上,的确有一些 Chatbot 项目就是用开源搜索引擎来实现的。 在规则匹配和文档排序上可以加入各种复杂的启发式规则或者机器学习算法,从而提高匹配精度。并且,在知识库上还可以嵌入知识发现和推理机制,提升对话质量。
于此相反,生成模型通常不依赖于特定的答案库,而是依据从大量语料中习得的“语言能力”来进行对话,看起来这个过程更加接近人类思考和产生语言的过程。而这个“语言能力”,往往涉及到基本语言元素的知识表示、以某种结构(比如深度神经网络)来模拟的语言模型,以及对生成的语言对象的评价和选择标准。
两种模型有各自的优劣:
对于领域范围清晰、指向明确的问题,基于检索的模型的对话质量更高。并且,基于检索的模型不会犯各种语法错误,但它的回答很难跳出预定的答案库,需要花费很大的精力来维护更新知识库和匹配规则。
生成模型直接从语料来训练知识表示和语言模型,可以有效降低维护问答库和规则的精力;同时,生成模型可以应对各种不在预设的问题库的问题,表现形式更加灵活。但是,好的生成模型往往需要巨大规模的训练语料,并且,对话中的上下文关系、信息和人格的一致性、以及关键意图识别等等一系列问题都是生成模型需要克服的难关。
早期 Chatbot 领域的架构几乎都是基于检索模型的,但深度学习技术取得突破性进展之后,越来越多的研究者和业界的工程师把目光转向了生成模型,因为深度学习的 Sequence-to-Sequence 方式可以非常好的实现生成模型的框架。
深度学习有一个非常诱人的优势,就是拥有可以避免人为特征工程的端到端(End-to-End)框架。通俗地讲,就是有机会利用深度学习强大的计算和抽象能力,自动从海量的数据源中归纳、抽取对解决问题有价值的知识和特征,使这一过程对于问题的解决者来说透明化,从而规避人为特征工程所带来的不确定性和繁重的工作量。
例如 AlphaGo 在提升围棋水平的过程中,并没有像传统围棋程序那样硬编码大量的布局定式、死活类型和官子技巧,而是直接通过学习高质量棋谱(以及通过增强学习自身产生的棋谱)提升水平。具体到 Chatbot 领域,这让我们能够设想只要有足够多的对话语料,就可以利用端到端框架直接进行训练,而不必考虑复杂的语法规则、微妙的对话情景等等一系列人为特征工程需要关注的焦点。这无疑代表了大家都希望追寻的美好前景。
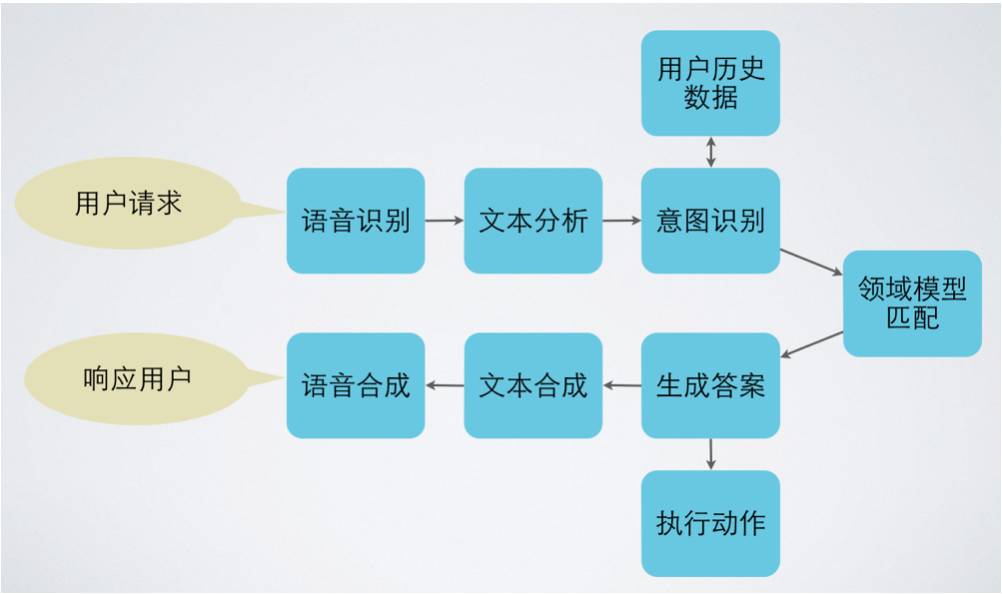
来源: 爱因互动,EinBot Conversation Generating Framework
问题与展望
不过,在巨头重金压注、风投界推波助澜和科技媒体摇旗呐喊的背景之下,也有一些冷静的观察者指出了一个基本事实,那就是目前 Chatbot 能够做的事情还相当有限,整体的用户体验依旧和合格的 APP 相去甚远。TechCrunch 在最近的一篇文章中指出:
“关于 Chatbot,看见的 demo 都很好,但这些 demo 都忽视(或者是故意不提)关键的一点——很多 App 尤其是好用的 App,通常并不需要涉及那么多输入,往往滑一滑、点一点就可以了... … 现阶段,很多 Chatbot 还不支持语音,因此你得手动输入文字,这样做还不如直接用 App 省事。此外,很多时候 Chatbot 搞不懂你的意思,意味着你得多次重新输入,改换表述让 Chatbot 理解你的意思。”
这段描述点明了 Chatbot 目前在具体的应用环境中面临的两大困境:
一方面在许多场景下 APP 的操作更加简单,Chatbot 并未体现出以自然语言作为交互界面的优势。
另一方面,对于机器理解人们日常使用的自然语言这件事情,事实上我们与几年前相比并未取得明显的进步,也就是说,目前的聊天机器人,还没那么“智能”,远远达不到人们对流畅对话的期待。比如下面这个 Facebook Messenger 上面颇为流行的查询天气的机器人 Poncho 和用户之间的对话:
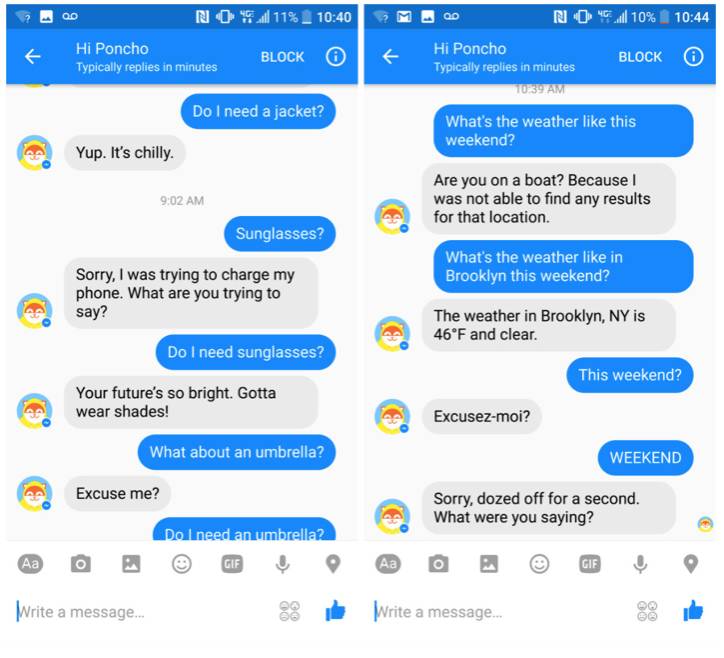
从中可以看出,对于语法结构完整、指向明确的问题,Poncho 能够给出相应的回答;但稍微发挥一点,省略语法结构,它就难以领略用户的真正意图,迷失在语境之中了。明显可以看出,Poncho 对上下文的理解是割裂的,仅仅是理解简单的天气查询也这样困难,更不用说很多需要复杂的语义和逻辑执行的问题了,这也是 Chatbot 普遍面临的难题。
在 Chatbot 所面临的两个困境之中,第二个问题,也就是对话的质量,是最关键的,因为本质上来讲,第一个问题的解决在很大程度上依赖于我们对第二个问题的解决有多成功。
试想,对于指令性的和获取信息类的操作,有什么是比自然语言作为交互界面更合适的呢?一个能够完整、准确的理解自然语言的 Chatbot 无疑能让我们放弃在界面和交互设计上所花费的额外的心思,更加贴近问题和产品的本质,贴近需求本身和用户价值。
因此,无论业界和媒体在这件事情上怎样的风生水起,无论巨头和创业公司面对用户许下怎样的美好未来,能否兑现承诺,取决于我们在机器理解人类自然语言这件事情上能否取得真正的突破,哪怕是在特定的领域、特定的场景下,能否诞生不低于人和人之间平均对话质量的应用。
客观来看,强 AI、顺利通过图灵测试的机器,这些科幻小说中的场景看起来依旧不会是短期内能够发生的事情,Chatbot 领域工业界的先行者们更愿意从解决具体的问题入手,一点一滴的积累经验。比如在行程规划、个人助理、售前咨询、客户服务等领域,都有不少朝气蓬勃的创业公司在深入的研究用户需求,搭建技术基础设施、开发相关的 Chatbot 产品。
虽然这些 Chatbot 所提供的对话质量和服务还不能完全令人满意,但至少这些探索和尝试对提升产品体验、吸引用户关注和教育市场起到了相当有益的作用。
无论如何,知识自动化和更加自然的人机交互这一趋势无可避免,由此带来了机器智能的两大应用场景:要么协助或替代人力的知识产生和传播过程,要么更好的服务于这些被替代下来的人们。相信这些都将是无比广阔的市场和商业机会,Chatbot 能不能引领我们,敲开这扇大门?
参考资料:
[1] How Chatbots And Deep Learning Will Change The Future Of Organizations,Daniel Newman,Forbes,June 28,2016
[2] The Rise of the Chatbots: Is It Time to Embrace Them?, knowledge@Wharton, June 9, 2016
[3] Deep Learning for Chatbots, Part 1 – Introduction, April 6, 2016, Denny Britz, WildML
[4] Deep Learning for Chatbots, Part 2 – Implementing a Retrieval-Based Model in TensorFlow, July 4, 2016, Denny Britz, WildML
作者:王守崑,个性化推荐系统和相关技术在中国的早期实践者,豆瓣早期初创团队成员之一,曾长期担任豆瓣网首席科学家兼副总裁,微信公众号:ResysChina,个性化推荐技术与产品原创社区。