
曾记得有一次聊天,有个朋友描述他对人工智能的印象,总结成三个词:西方的、商业的、未来的。
我当即表示你说的很好,唯一的问题是一条都没说对。
按下我们俩怎么展开斗殴暂且不提,这里希望破除的是大家对人工智能的某种固有印象。事实上,人工智能作为一种很早就发展起来的通用技术,绝不是西方的专利,也绝不仅仅是够创造商业价值。
甚至在某些机缘巧合下,人工智能能够成为我们用认识历史、认识自身民族、认识祖先与过去的利器。
梁启超说“学术乃天下之公器”,不仅是说学术天下人共有,同时也是说学术天下共致。作为一种基础工具的人工智能,往往能够在意想不到地方发生效用。比如说今天为大家介绍的借助人工智能技术,自动识别西夏文——一个纯粹中国的人文社科领域。

美感奇特的西夏文
虽然这项技术大多数人永远不会涉足,但这个案例的价值在于可以打破我们对AI的某些偏见。AI不只是集中在那几个领域,也不是欧美寡头的玩具,它甚至可能无处不在。
为什么要识别西夏文?其中隐含着哪些困难?
我们知道,西夏是与北宋、辽、金先后对峙的党项族国家,曾经统治河西地区超过二百年。与大众认知中不同,西夏不是个茹毛饮血的野蛮文明。他们曾经创立过惊人的文化、艺术与宗教文明,但随着1227年蒙古灭西夏,蒙元不为西夏立史,关于这个政权的记录快速消亡,李元昊立国时创立的西夏文也随之湮灭。
西夏文又名河西字、番文、唐古特文,曾在西夏王朝统辖的今宁夏、甘肃、陕西北部、内蒙古南部地区盛行了约两个世纪。但在西夏灭国后,这种参考汉字创立的奇特文字逐渐失传,最终成为了一种死文字。
直到1804年,武威大云寺发现了著名的《重修凉州护国寺感通塔碑》,西夏文才在埋藏了数百年后重现人世。从此识读西夏文开始成为了学界的重要工作。

《重修凉州护国寺感通塔碑》局部
二百年以来,出土的西夏文文献不断增多,其中大部分都被英、俄探险家带到了境外。但各国学者努力下,西夏文的基础文字识别已经完成,现阶段的工作重点是依据文字列表,去识读大量西夏文文献的具体内容,揭开西夏以及当时中原、西域各国的历史迷雾。
但在这个过程里,研究人员认读西夏文必须通过手工翻阅查找,耗费时间异常辛苦不说,由于西夏文是一种相似度极高的文字,人工识别还可能存在很大的错误率。
所以就有学者提出,利用计算机来自动识别西夏文。这种设想很好,但在具体操作中还是有巨大问题。比如西夏文结构复杂、组成字符各部分要素高度相似,并且平均笔画达到25画,计算机识别难以入手。
此外,西夏时期虽然已有印刷术,但出土文献还是以手抄本和刻版文字为主,同一个字的在不同文献上的位置不固定、整体布局会发生偏移,都给机器识别带来巨大困难。
于是有意思的事出现了,宁夏大学相关研究机构为代表的学术力量,选择了以人工智能技术解决西夏文的自动识别。
并且这个工作很早就已经开始,不断有成果涌现。从时间上看,绝不是赶这波AI热潮的产物。
人工智能完成西夏文自动识别
早在1996年,日本国立亚非语言文化研究所就制作了西夏文字库和排版系统。1997 年中国学者李范文和日本学者中岛干起利用该排版系统合作出版了《电脑处理西夏文〈杂字〉研究》。俄罗斯应该也都有西夏文数据化和计算机处理的项目与研究成果。
而使用弹性网络、神经网络、AI算法以及深度学习来识别西夏文,则是中国领先完成的一个创举。
用AI识别西夏文,主要依托的是计算机字符识别( optical character recognition,OCR) 技术,这种技术上世纪60年代就成为了人工智能研究的主要领域之一。它的核心技术主张是基于人工智能运算来识别文字符号的数字影像,并将其转换为对应的数字文本,达到可识别、可编辑、可转化的目的。
OCR技术目前在很多领域已经相当成熟,比如我们经常用到的印刷文件文字提取。在OCR识别领域,更多的应用是手写体内容的精准识别,而利用OCR识别考古文献中的非广泛使用文字却基本处于空白。
这里可以结合论文简单介绍两种AI识别西夏文的案例。
比如在《基于弹性网络的西夏文识别》当中,研究人员利用弹性网络技术,将西夏文中的笔画特征进行网格化提取。再统计像素点在每个网格内的概率分布,形成一种可读取的特征模型。最后使用文档主题模型方法对提取的特征降维处理,结合数据库对文献进行识别。
根据论文,这种方法平均识别率可达87.99 %。
再比如《基于Mean Shift算法的西夏文字笔形识别》,Mean Shift算法,即偏移均值向量,是机器学习领域的一种基本算法。其基础理论是利用信息密度来完成聚类、图像分割、跟踪任务,可应对相似但界限模糊的图像处理应用。利用这种算法,研究人员将原始资料生成概率统计直方图,通过相似度来判断归类具体的西夏文笔形。
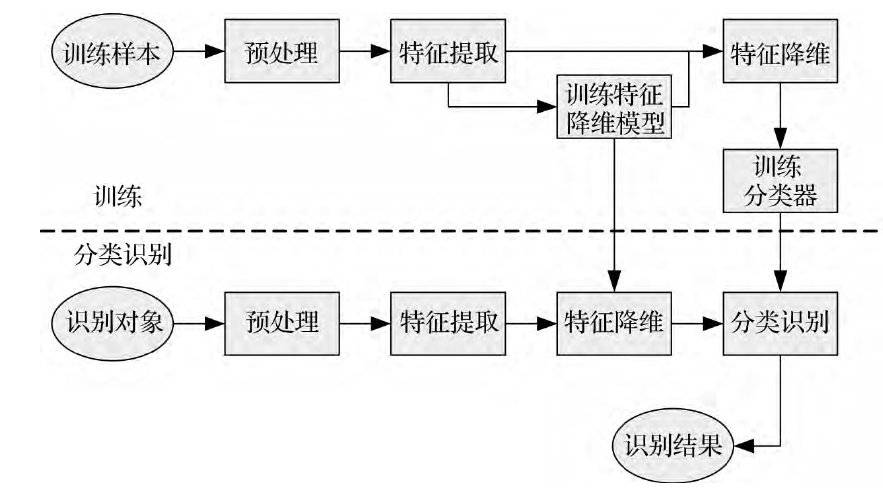 西夏文智能识别算法流程
西夏文智能识别算法流程
这里仅仅是两个具体应用案例,利用深度学习等前沿人工智能技术识别西夏文的应用还在不断发展。
文献与考古领域的人工智能应用
可能识别西夏文距离我们的日常生活还相对较远,但推广至当整个人文社科领域,AI的应用可能就会从另一个角度无限贴近我们的生活。
从近期来说,AI推动学术效率,可能会影响我们的学科配置、学术训练甚至高等教育体系。从长远来看,AI推动的进一步识别历史与文献的能力,是我们窥探自身过去,了解“中国”为何是“中国”的全新工具。
在我们沉浸于未来带来的快感时,人工智能却可能在历史领域快速发挥它的价值。通过西夏文识别的例子,不难发现在文献与考古这些社科领域当中,人工智能至少可以发挥以下几种功效:
1、考古图像的识别与归档,比如基于算法的文物识别、文物数据化、考古现场数据化。
2、文献文本的识别与转码,比如原始文献的文字识别读取、文献聚类、文献数据化。
3、文献数据库的知识图谱化与机器学习应用。比如学科文献图谱化、时代文献图谱化、科研项目数据图谱化,以及基于知识图谱训练的人文社科领域智能体。这一点尤其重要,想象力也最为充沛。就像金融、翻译等领域很可能被AI替代一样,文献学与历史研究领域大部分依赖考证、校勘、资料爬梳的工作,也存在被AI取代的可能性。
类似的人文领域与AI跨界还有很多,有些甚至涉及哲学与伦理层面的技术与人文互搏,以后我们会陆续介绍。