
本文来自微信公众号: 数字生命卡兹克 ,作者:数字生命卡兹克,题图来自:AI生成
在各种小道消息,各种预测之后,终于,在OpenAI十周年的这一天。
也就是今天的凌晨2点,GPT-5.2终于跟大家见面了。
这是Gemini 3 Pro爆火,第一次让OpenAI没有领先优势,奥特曼在内部官宣红色警戒状态之后,他们掏出的第一款模型,也是OpenAI的十周年献礼。
而这款模型的特点也非常有意思,OpenAI的原话是:
We are introducing GPT‑5.2, the most capable model series yet for professional knowledge work.
我们正式发布 GPT-5.2,这是迄今为止在专业知识工作方面能力最强的一代模型系列。
专业知识工作,记住这个关键词,后面要考。
我们先从各种跑分上看,其实能看到,一些跑分其实没有质的飞跃,有一种数码厂开始挤牙膏的感觉……
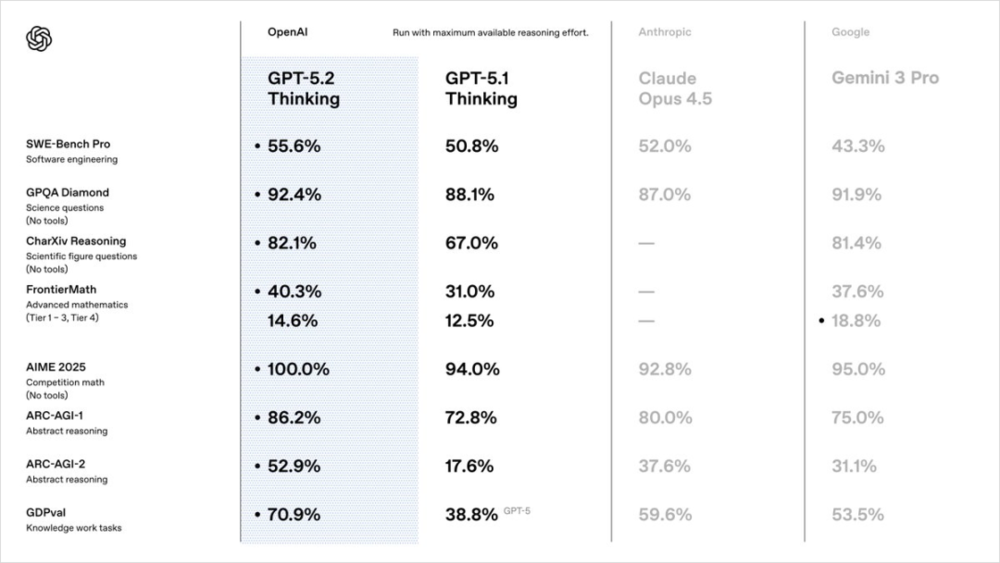
对比了GPT-5.2、GPT-5.1、Claude Opus 4.5和Gemini 3 Pro。
在软件工程(SWE-Bench Pro)、科学问题(GPQA Diamond)、数学竞赛(AIME 2025)这些传统评测集上,GPT-5.2确实又强了一些,也回到了第一的位置,全面领先。
在前端审美还有3D元素上,表现得更牛X了。
在视觉理解能力上也更强了。
比如要求模型识别图像输入中的组件,并返回带有近似边界框的标签。
即使在低质量的图像上,GPT-5.2也能识别主要区域并放置与每个组件真实位置大致匹配的框,而GPT-5.1只标注了几个部分,对它们的空间排列理解不是很好。
但是这些东西,说实话,确实也就那样,大家很难体感上还觉得有多牛X。
就像芯片厂子告诉你,我的手机芯片性能又提升了25%,你听了以后,哦确实强,但是完全不影响你继续刷抖音和小红书对吧。
不过有两个评测集,是我觉得这次GPT-5.2最大的亮点,且一定要单拎出来,跟大家单独聊一下的。
一个是ARC-AGI-2,一个是GDPval。
这两个,非常有意思。
先说ARC-AGI-2。
过去的AI评测,比如MMLU,考的主要是是知识。
比如它会问你“美国第一任总统是谁?”“光合作用的化学方程式是什么?”
这种评测呢,坦率的讲,对于一个读了半个互联网的AI来说,有点像开卷考试,它有很大概率不是真的推理出来的,而是背出来的。
这就导致一个问题,在实际的评测中,我们分不清AI是真的聪明,还是只是记性好。
于是,François Chollet,就是那位Keras(一个著名的机器学习框架)之父,2019年第一次在论文《On the Measure of Intelligence》里,提出了ARC这个变态测试。
而这个测试,跟知识储备一毛钱关系都没有。
全名叫,Abstraction and Reasoning Corpus,抽象与推理语料库。
设计目标就是测模型的通用智能的能力。
大概就是,不看你在某一道题上有多熟练,而是看你在没见过的新题上,能不能自己推理出规则、举一反三。
目前正式版发展到了第二代,也就是ARC-AGI-2,我给大家放一下,ARC-AGI-2里面的一些典型的题目,大家就懂了。
这种能力,现在称为流体智力
这玩意儿对AI来说,难于登天。在很长一段时间里,顶级AI的得分都低得可怜。
在ARC-AGI-2上,之前GPT-5.1的得分是17.6%,而GPT-5.2,直接飙到了52.9%。直接翻了三倍。
这是一个很恐怖的数据。GPT-5.2的模型,直接在排行榜上屠榜了。
而且,效率还很高。
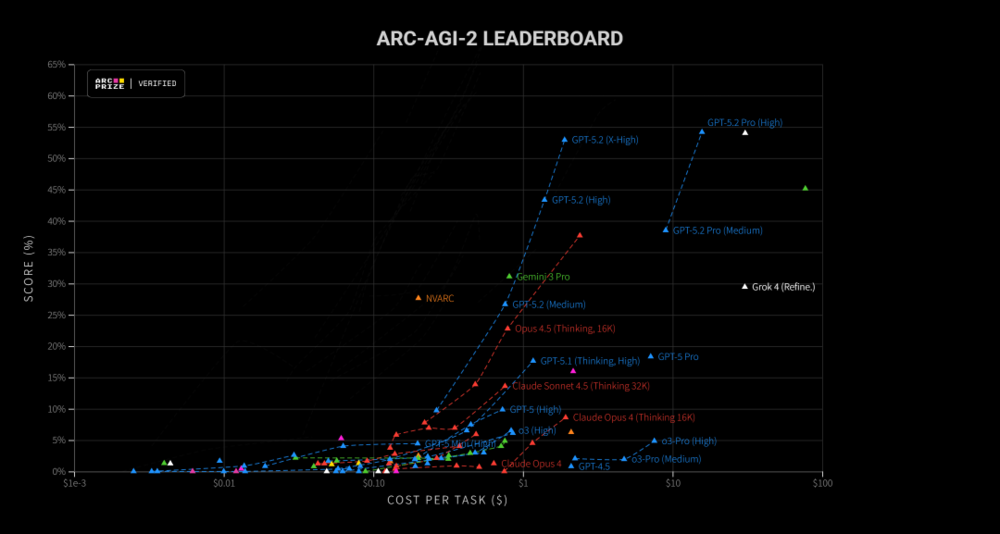
基本都在同成本区间,能力做到了最高。
在真正的智力水平上,GPT-5.2确实达到了目前的最优。
这就比较有意思了。
然后是第二个,也是我自己现在最关心、也是我认为最重要的一个:GDPval。
可能很多人没听说过这个评测集。它是OpenAI自己在2个半月前新出的。
其实你看这个名字也能看出来一点端倪。
他们要用一个全新的标准,来衡量AI在
过去,我们说一个模型牛X,是因为它代码写得好,或者知识答得准,或者考试分数高。
这当然很重要,但就像我常说的,这个世界不只有程序员和科学家。还有律师、设计师、市场经理、护士、建筑师、销售……无数专业知识工作者。
他们工作的价值,其实很难用一张考卷来衡量。
于是,OpenAI他们在美国贡献GDP最高的9个行业里,选取了44个核心职业,然后,他们找到了在这些行业里平均有14年工作经验的资深专家,让他们出了1320道专业知识任务,并且每一项,都基于真实工作成果。

比如,给律师的任务,可能就是一份真实的合同草案和客户需求,让他去审阅和修改。
给市场经理的任务,可能就是一堆产品资料和市场数据,让他写一份营销方案PPT。
给制造工程师的任务,可能就是一张产品设计图,让他优化生产流程。
这些任务,不仅有文字,还可能包含PDF、Excel表格、图片、PPT,是高度复杂的、多模态的、没有标准答案的真实工作。
整套任务的平均用时,是人类专家要花7个小时才能做完,有些甚至是一两周的活。
然后,模型和人类的成果,会被同领域的另一批专家进行盲评。
他们也不知道谁是AI,谁是人类。
评委只需要回答一个问题:你更愿意把哪份交给客户?是这份,还是这份?
结果,GPT-5.2 Thinking在这套GDPval上,赢或打平行业专家的比例,达到了70.9%,而GPT-5.2Pro模型是74.1%。
注意,这里的参照系不是普通实习生,而是行业专家。
也就是说,在一个有着十几年经验的采购经理、或者审计师面前,GPT-5.2干出来的活儿,有七成的时候,比专家干得好,或者至少一样好。
而GPT-5,只有38.8%。
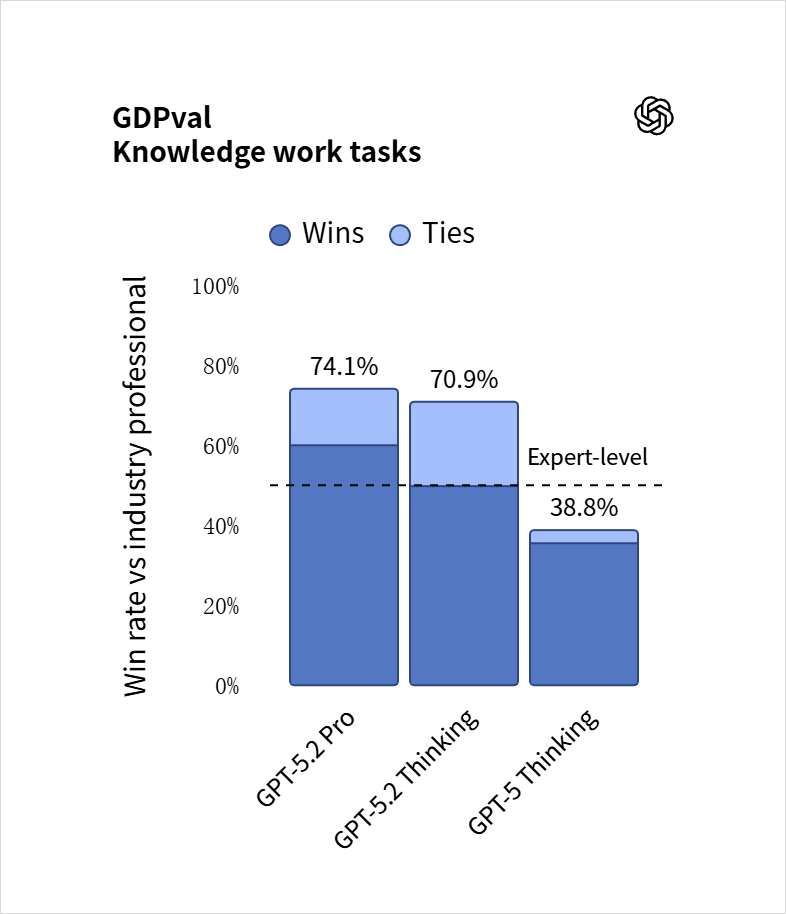
这个进步的速度,还有有一点快的。
看一下官方放的case的对比,还是比较直观的。
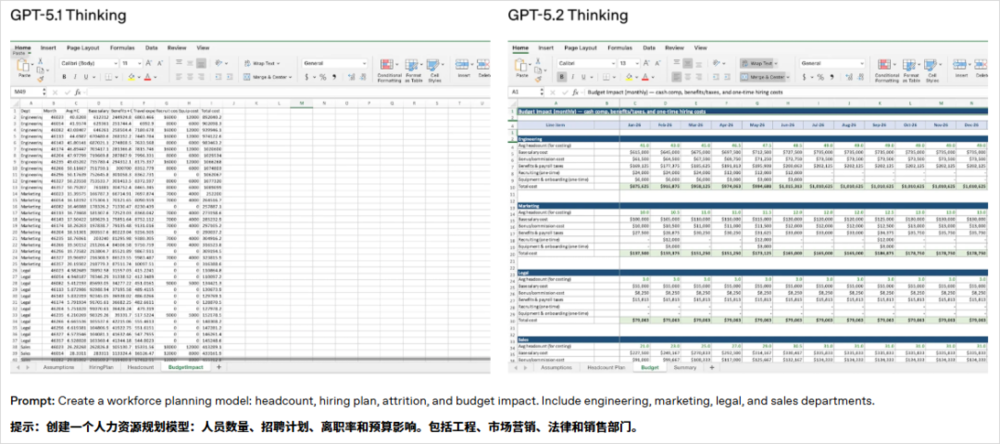
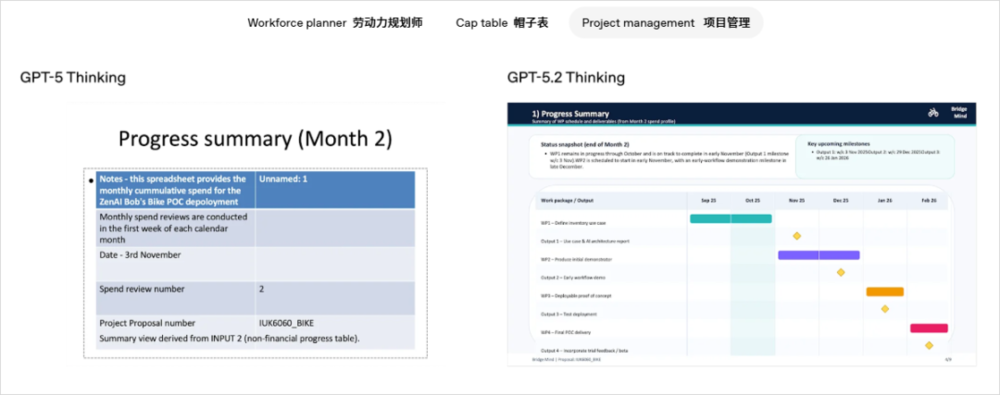
我们过去的模型,都花过于着重笔墨在编程开发上了。我并不是说编程开发不重要,它很重要,很牛X。
但,其他的领域的工作,我也觉得应该被重视。而GDPval,就是我认为最重要的一个指标。
而且这次GPT-5.2,在上下文上,也有大幅的加强。
用我们以前的大海捞针测试,在一个256K的巨型文档里面埋四根针,让AI来根据文档内容回答。
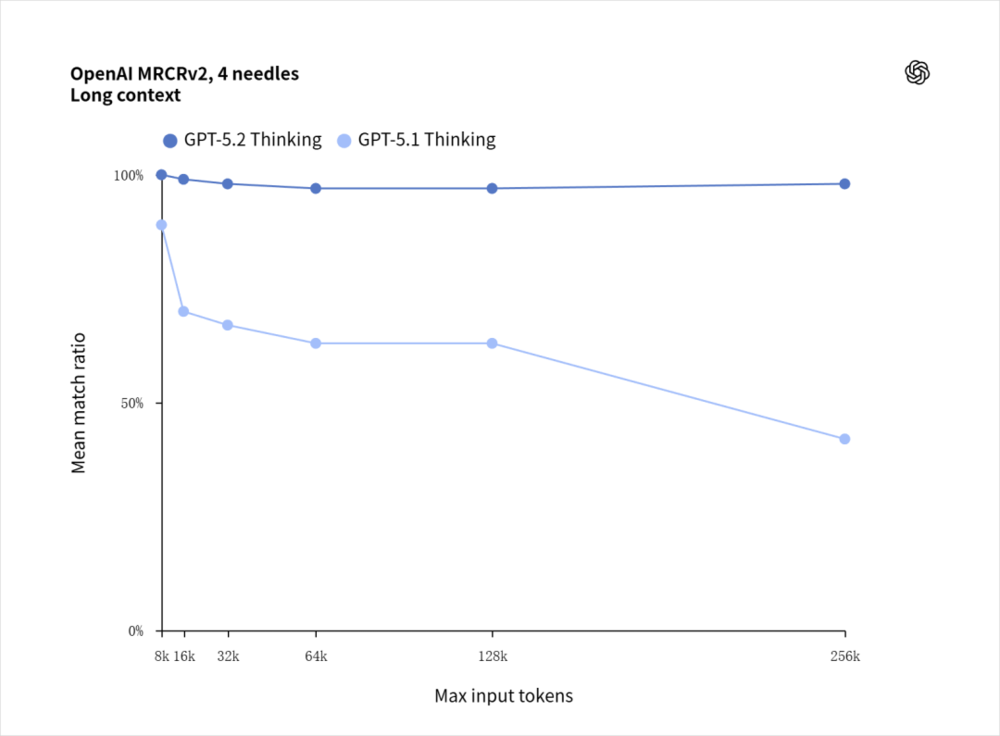
GPT-5.2干到了离谱的100%,这也是我印象中,唯一一个能干到100%的。
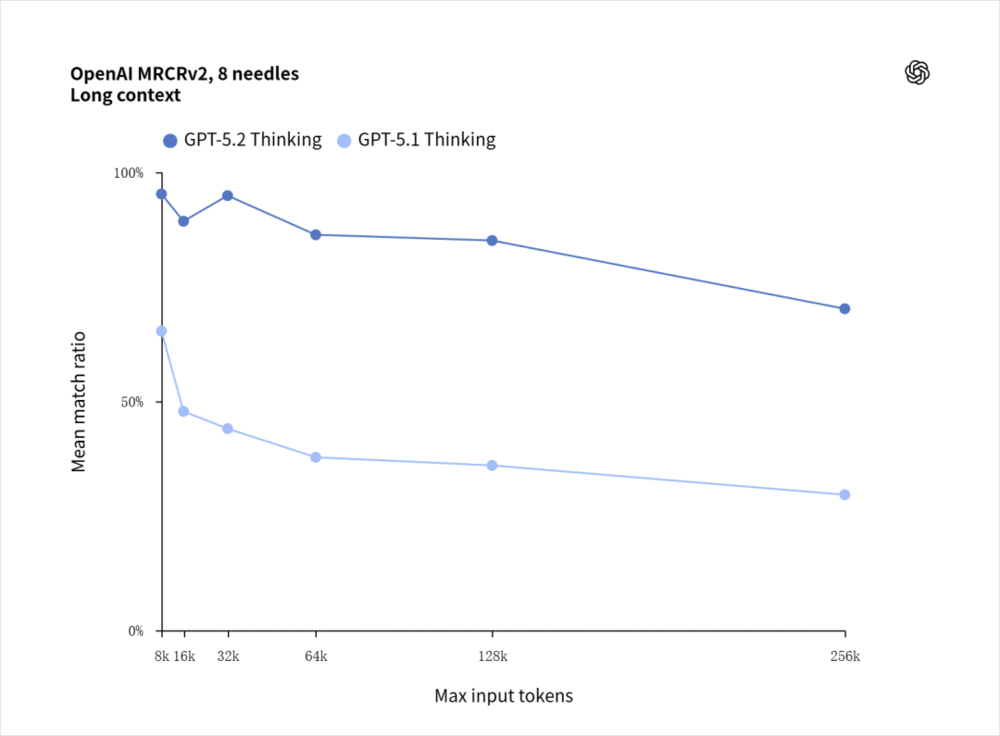
8根针的正确度会下降,但是这个衰减,已经比GPT-5.1牛X太多了。
而且,还有最新的知识库截止日期:
牛X的知识工作处理+最新的知识库截止日期+更棒的智力+准确性超高的上下文。
这简直,就是真正的天选牛马搭子,对打工人的加持,实在是太强了。
这是真正,奔着大众、奔着实用去的。
目前今天会开放给ChatGPT付费会员,明天会开放给免费会员,会直接替代GPT-5.1,但是如果你是付费会员的话,还会在老模型中存续3个月。
就是这。
可惜截至我发文的凌晨6点这一刻,作为尊贵的200刀的ChatGPT Pro会员,我还是没有拿到GPT-5.2的体验资格。
一些所谓的ChatGPT上的为GPT-5.2专用的文件精修,也只能等拿到实测以后,再出一篇GPT-5.2的打工合集了。
然后开发者的话,已经可以通过API调用。
价格上,会比5.1贵一些。

整体上,GPT-5.2的所有消息差不多就这样了。
而我自己一直期待的,成人模式,还是没有到来。
奥特曼自己说的是12月上线。
也不知道能不能等到。
反正他说,下周还会再送一些小的圣诞礼物。
盲猜一手OpenAI家的生图模型,或者成人模式。
对于一个创作者来说,这两玩意,真的很需要……
最后总结,GPT-5.2在我心中,是一个合格的迭代,并没有跟很多模型一样,专注于纯粹的传统刷分,而是聚焦在了广大白领打工人身上,帮大家解决实际工作中的问题。
这个点,我觉得就很酷,非常的刚需。
但是从路线上来说,感觉GPT-5.2还是被原生多模态的Gemini 3 Pro压了一头,12月大概率还是要发个生图模型出来的,不知道对标Banana,会不会有新的惊喜。
总之,还是保持期待。
本文来自微信公众号: 数字生命卡兹克 ,作者:数字生命卡兹克