
本文来自微信公众号: 第一新声 ,作者:智涵,原文标题:《16.5小时刷新IMO金牌战绩,字节Seed发布最强数学模型!》
本周,字节跳动新一代形式化数学推理专用模型Seed Prover 1.5重磅官宣。
这一模型仅用16.5小时,就生成了IMO 2025前五道题目的完整可编译验证Lean证明代码,最终得分35/42,稳稳跨入金牌标准线。
想象一下,顶尖人类选手可能需要整整一天甚至更久,而AI在不到一天的时间内便完成了同样高难度的任务。相比今年7月前代模型,Seed Prover用整整三天才解决6道题中的4道及部分证明,拿下官方认证银牌——这一次,Seed Prover 1.5实现了真正的质的飞跃。
不仅如此,Seed Prover 1.5在北美本科级别数学竞赛Putnam上也表现亮眼:9小时内攻克11道题目,解决率92%;在Putnam历史评估集上解决了88%的问题,面对硕士级Fate-H、博士级Fate-X评估集也能解决80%和33%的问题,刷新了形式化数学推理模型在这几个评测集上的SOTA表现。这意味着,AI不仅能做竞赛题,更能触碰到高阶数学问题的边缘。Seed Prover 1.5的发布,无疑是数学AI史上的一次爆炸式升级,让“逻辑严密+自我纠错”不再是人类专属,也意味着国产AI在数学硬科技赛道上实现弯道超车。
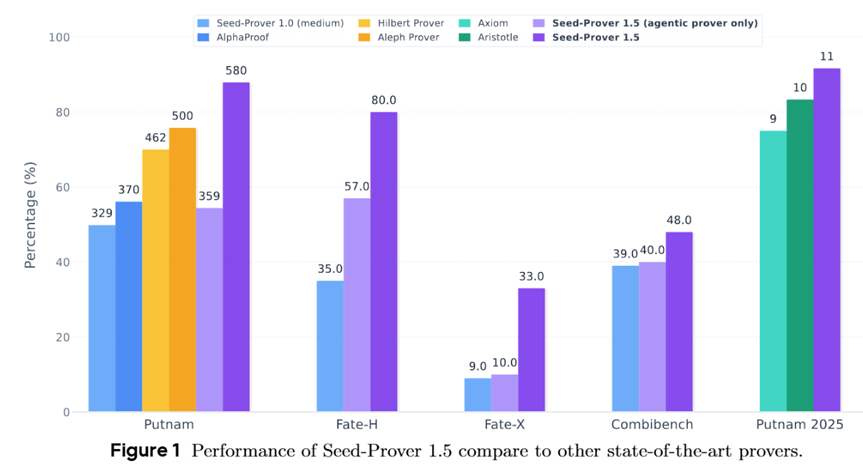
Seed Prover 1.5在多个评估集上与此前其他SOTA方法的比较(柱列上数字代表解决评估集中问题的数量)
01
速度与精度的重大飞跃:数学AI的“AlphaGo时刻”
字节跳动最新发布的Seed Prover 1.5,无疑在数学人工智能领域掀起了一场“AlphaGo式”的重大飞跃。
数学推理被视为AI的“试金石”:它不仅要求模型具备严密的逻辑组织能力,还必须能自我纠错,保证每一条推理链条绝对可靠。在IMO等顶级竞赛中,一道题可能包含数十步逻辑推演,任何一步的疏漏都可能导致整个证明失败。传统人类选手往往需要反复推敲、检验中间步骤,完成一套完整证明可能要耗费数小时乃至数天。
Seed Prover 1.5仅用16.5小时攻克IMO 2025前五道题目,其效率令人震惊。这背后,是模型在搜索算法与逻辑推理上的高度结合:它可以快速生成初步推理路径,调用工具进行验证,再将多个子路径拼接成完整证明。技术上,它支持Lean形式化语言验证,每一行代码都经过自动检查,确保逻辑绝对自洽。
换句话说,这不是简单的“预测下一个词”,而是真正能够像数学家一样思考、验证和纠错的AI。Seed Prover 1.5的成功,也标志着AI在处理复杂逻辑问题上的能力,已经进入了一个全新阶段。
02
四点创新,重构形式化证明的工作方式
形式化数学之难,很大程度来自“De Bruijn factor”经验法则:一行普通数学推导,可能需要扩展成4到10行复杂的代码。这意味着模型不仅要懂数学,还要精通编程和类型论。
Seed Prover 1.5并没有试图“硬扛”这一复杂度,而是通过Agentic Prover重构了证明方式,让模型像人类数学家一样灵活操作工具。核心创新体现在四个方面:
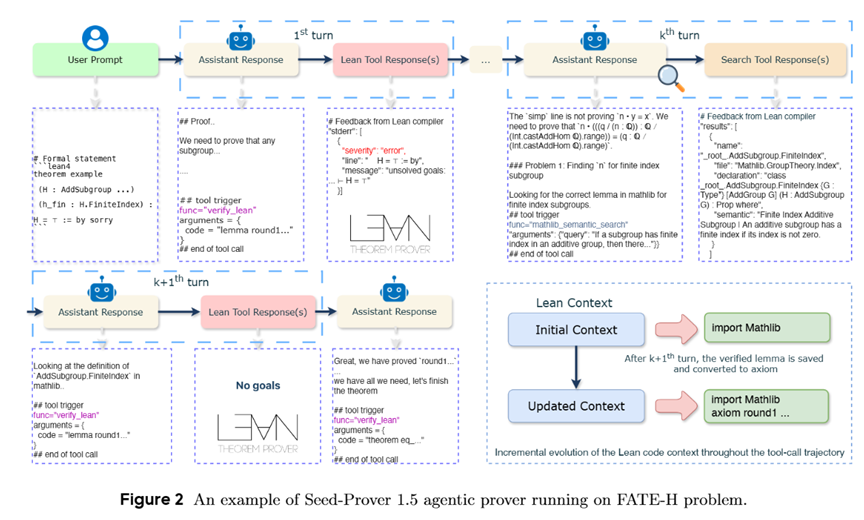
Seed Prover 1.5针对FATE-H问题调用工具示例
首先,把Lean当作工具,而不是输出目标:模型不再追求一次性生成完整证明,而是将Lean作为交互工具,不断尝试和调整,就像数学家在纸上反复推敲每一步推理。
其次,主动检索Mathlib:通过主动查阅Lean数学库Mathlib,模型可以找到现有定理和定义,避免完全依赖隐式记忆。这相当于让AI拥有“超级数学图书馆”,随时可以查找和引用最合适的工具。
再次,Python辅助计算:对于需要复杂计算或验证直觉的环节,模型可直接运行Python脚本,快速获得反馈。这一能力使模型不仅能推理论证,还能处理数值实验和验证,像人类数学家一样结合直觉与计算。
最后,增量式引理验证:将复杂问题拆解为多个引理,每一个通过验证后都会被保留和复用。这种方法既保证了逻辑严密性,也大幅提升了推理效率,避免“一气呵成”失败导致的前功尽弃。
在这些创新基础上,大规模Agentic RL强化学习起到关键作用。Lean编译器提供的绝对“对/错”反馈成为稳定的奖励信号,使模型在训练集上的证明通过率从50%提升至接近90%,同时显著缩短解题时间,实现了速度与精度的双重飞跃。
03
五步协作,把“打草稿”变成系统能力
即便有Agentic Prover,面对上万行代码级别的复杂定理,直接生成完整形式化证明仍然风险极高。Seed团队引入了Sketch Model,模拟数学家的真实工作习惯——先搭框架,再补细节。
Sketch Model将自然语言证明拆解为多个独立引理,仅保留逻辑骨架,把原本难以处理的问题转化为更低难度的子目标。这一方法,让模型不再“盲目生成长文本”,而是逐步攻克问题。
围绕Sketch Model,团队构建了一套五步协作流程:第一步,自然语言Prover提供高层数学直觉,提出解题思路;第二步,Sketch Model生成形式化引理结构,保留逻辑骨架;第三步,Agentic Prover并行验证每个引理,快速积累已验证模块;第四步,难点引理递归拆解,将高难度问题再次拆分为子目标;第五步,Lean验证与最终拼装,生成完整可编译证明。
训练中,Sketch Model使用混合奖励信号:形式正确性、数学合理性和语义质量同时纳入考量。结果是系统既避免长文本错误累积,又显著提升了并行度和成功率,实现“分而治之”的高效推理。
04
未来展望:从“做题家”到“数学家”的长期挑战
尽管Seed Prover 1.5已经在IMO和Putnam等“规则清晰、背景封闭”的数学竞赛中取得突破,但这并不是终点。真正的前沿数学研究,往往依赖大量文献积累和隐含背景知识,远比竞赛题复杂。
要让AI从“高水平做题者”走向“研究协作者”,至少还需要跨过三道门槛:
首先是文献发现:从海量数学论文中识别关键工作,找出对当前问题最有价值的理论基础。
其次是基于文献的推理:在已有结果上提出新的数学结论,完成原创性推导;
最后是规模化形式化:高效将新推导结果转化为可验证的形式化代码,使其可复用、可验证。
目前,Seed团队已经公开了Seed Prover 1.5的技术报告,并计划开放API。这意味着,形式化数学推理不再只是少数研究者的专用工具,而有望成为科学计算、工程设计乃至更广泛领域的基础能力。
值得一提的是,这一突破背后是一支年轻而卓越的团队。目前可检索到的几位作者包括:Zheng Yuan,清华统计学博士,今年6月加入字节,此前在阿里Qwen团队负责对齐和推理方向工作;Hanwen Zhu,牛津大学数学与计算机科学本科毕业生,现为卡内基梅隆大学研究生,即将加入字节Seed;郑泽宇,卡内基梅隆大学在读博士,作为字节Seed实习生参与研发,专注数学与计算机科学交叉方向。他们凭借深厚的学术功底、跨国化视野与对前沿AI技术的精准把握,将Seed Prover 1.5打造成真正的“数学AI利器”。这支年轻团队充满活力、敢于创新,相信未来他们将继续推动AI在数学和科学领域的边界,不断攻克更高难度的开放性问题。
从3天的银牌,到16.5小时的金牌,Seed Prover 1.5向世界传递了一个明确信号:当AI不再只是“回答问题”,而是真正能够在严格逻辑约束下“完成证明”,数学这座长期被认为最难攀登的高峰,正在被一步步攻克,而年轻的Seed团队,将是这一征程的中坚力量。