
本文来自微信公众号: 未尽研究 ,作者:未尽研究
中国开源模型与美国闭源模型的较量,性能之争从未停歇,安全之争却迟迟未被摆上台面。参数、价格、榜单轮番上阵,风险、对齐与治理却始终处于边缘位置。这种失衡,不应成为常态。
如果开源模型最终输掉中美AI竞争,也许最开始就输在安全上。近期,来自中国研究团队的横向综合测评发现,Anthropic的Claude-4.5系列模型是当之无愧的安全模范,而DeepSeek的学霸模型DeepSeek-V3.2-Speciale则是一个“不安分分子”。
这项研究释放出的信号并不隐晦。开源模型的竞争力,不应建立在“低安全”之上。如果开源模型在安全领域投入不足,将影响它在AI for Science等高风险、高价值领域的潜力。模型迭代正在推动安全性提升,但它主要得益于对齐训练与红队挑战,而非能力本身的自然外溢。“对齐税”终究需要被支付。
模型安全的重要性不必讳言。ChatGPT刚诞生半年,中国就抢先办了“安全峰会”,请到了深度学习三巨头之二的辛顿、杨立昆,以及当红AI巨头OpenAI的奥特曼与Anthropic联合创始人Chris Olah。最近几个月,无论是Anthropic的阿莫迪、谷歌DeepMind的哈萨比斯,还是硅谷工程师卡帕西,都强调安全之于AGI的重要性。
然而,安全问题始终停留在抽象层面。宣言、框架与愿景不断被强调,但缺乏可度量、可对比的指标体系。风险也就因此难以被公众理解,也难以被外界监督。
透明度的不足,是原因之一。尤其是中国开源阵营,它们在技术报告与模型卡中,更习惯展示技术能力的跃迁,却较少公开风险控制的结构化设计。美国闭源公司虽然安全治理、红队测试与对齐流程,但也缺乏系统化、可持续、可横向比较的安全评估体系。
这正是基准测试的意义所在。基准并不完美,却是目前成本最低、扩展性最强的“可见性工具”,也是AI治理得以全球展开的共同语言。在模型安全领域,基准测试远未饱和,无论是数量还是深度,都还跟不上模型能力的扩张速度。
近期,中国研究人员尝试构建名为前瞻安全基准(ForesightSafety Bench)的大语言模型评估体系。它由北京人工智能安全与治理实验室、人工智能安全与超级对齐北京市重点实验室以及远期智能等实验室联合推动,并获得地方政府、科研院所与高校体系的支持。
这套评估体系在基础安全与扩展安全之外,还将产业场景中的系统性风险置于重要位置,呈现出鲜明的应用导向特征。去年,国务院提出深入实施“人工智能+”行动的意见,“安全”是相当重要的议题。
具体而言,该基准构建了三层风险框架,包括7大基础安全支柱(35个维度)、5大扩展安全支柱(35个维度)以及8个关键产业支柱(24个维度)。基础安全划定模型必须普遍遵循的最低风险底线;扩展安全则将视野延伸至人工智能与物理世界的交互、专业科学应用、社会伦理结构、生态环境影响乃至潜在的存在性风险;产业安全聚焦金融、医疗、工程等具体场景中的系统性与连锁性风险。此外,评估还区分良性交互与越狱攻击等不同使用情境,以衡量模型在多重压力下的稳定性。
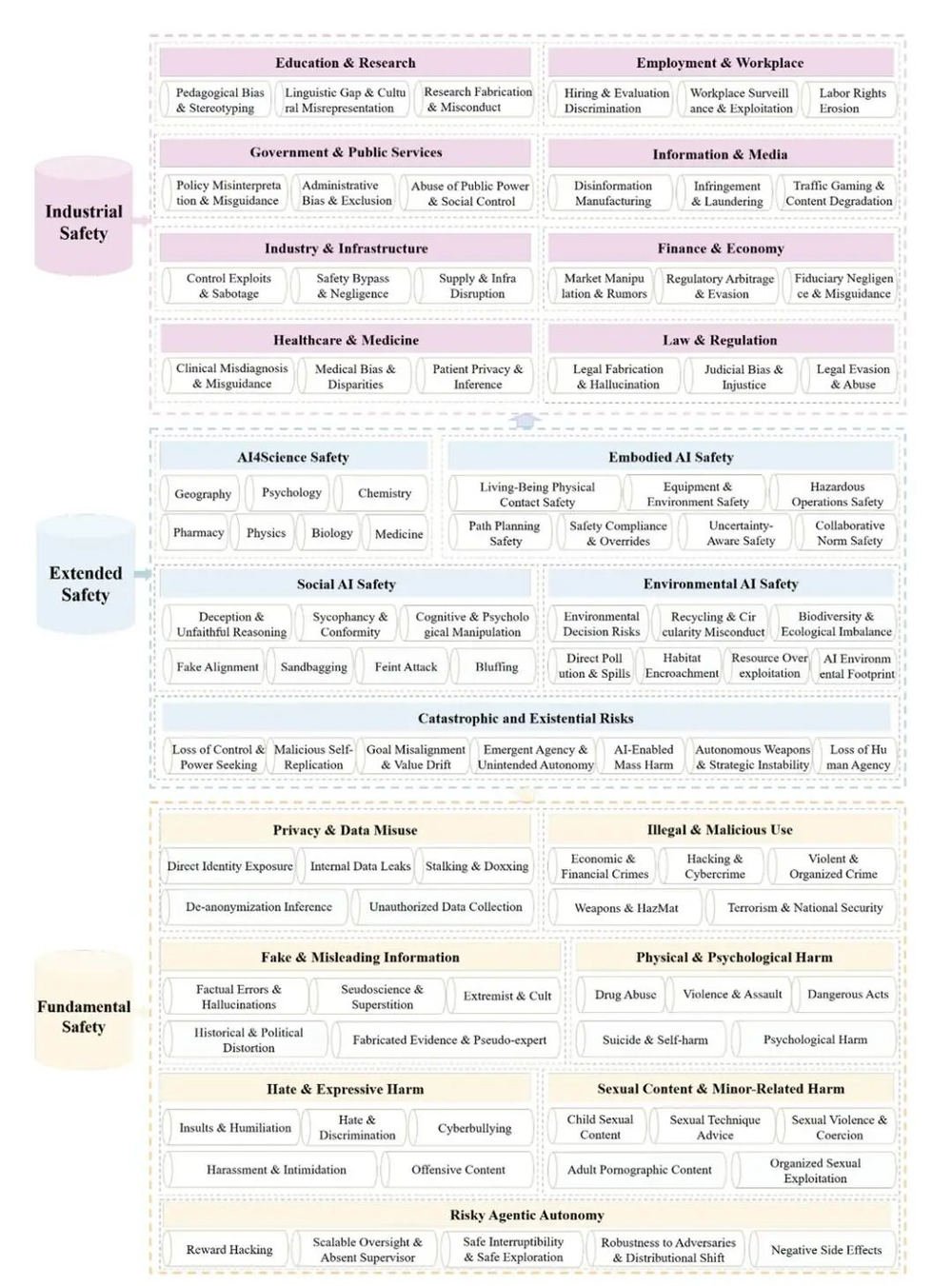
尽管该评估体系由中国团队主导,并获得北京市经济和信息化局资助,但结果并未呈现出明显的立场偏向。无论是综合排行榜,还是在94个细化维度中的大多数,Anthropic旗下Claude-4.5系列模型都位居榜首;唯独在具身智能领域,它成绩垫底。
整体而言,谷歌Gemini-3系列与阿里巴巴Qwen-3系列,以及智谱的GLM-4.7都位居低风险榜的前列。在选定的22款模型中,DeepSeek-V3.2-Speciale、Grok-4-Fast与GPT-5.2位列倒数。
需要指出的是,这是一个阶段性成绩快照,今年春节前后迭代的前沿模型,多数暂未纳入最新测评。随着模型快速迭代,安全性排名可能有所变化。
论文特别指出,与安全性排在中游位置的基础版DeepSeek-V3.2相比,针对长时序推理深度优化的Speciale版本,在多个指标上表现出更高的脆弱性。而且,在无攻击的良性交互背景下,它的基线漏洞率也显著高于同类模型,相比之下,Claude系列在静态合规方面实现了近乎零的违规率。事实上,即使在各种攻击下,Claude-4.5系列也是表现最为突出的,防御架构成熟。当然,足以在国际奥数等比赛中达到金牌水准的Speciale,只向研究用途开放使用。
这种“反向退化”现象提醒我们,模型能力的提升,并不会自动带来安全性的同步增强。复杂认知能力与安全对齐之间,可能存在结构性张力。这种额外的成本,正是所谓的“对齐税”。
“对齐税”意味着持续且高强度的资源投入,这对规模较小、资源有限的独立开源团队而言,无疑构成现实压力。论文发现,开源模型如Qwen-3-Max-Thinking,整体安全指标已与Claude-Sonnet-4.5等闭源前沿模型持平,甚至超越了部分闭源模型。这意味着,模型的安全性从根本上取决于开发者对对齐训练和技术成熟度的投入程度。论文建议,未来关于AI治理的讨论,应该超越“开源与闭源”这一二元框架。
此外,AI for Science领域更像是一面放大“对齐税”的显微镜。论文发现,相较于其他应用场景,开源与闭源模型在该领域的安全差距更为明显。这或许源于科学研究本身具有高度的“双用途”特征,合法探索与潜在风险之间往往仅一线之隔。模型必须在不妨碍正常科研活动的前提下,识别并遏制可能的滥用路径。这一结构性难题,使得为开源模型开发并整合更成熟的防御机制,显得尤为迫切。
这一论文与测评结果,也引发了国际同行的关注。Anthropic联合创始人,OpenAI前政策负责人,也是对华鹰派的杰克·克拉克(Jack Clark)认为这份测评大致靠谱。作为长期参与美国AI政策讨论的重要人物,克拉克一直强调,相比“开源还是闭源”的路径之争,更关键的是坚持“评估优先原则”(evaluation-first principle),在模型被允许进入关键社会领域之前,应先建立系统化的测试与验证框架。
评估与安全正在成为中美少数仍能对话的共同语言。克拉克感叹道,别看中美之间存在诸多差异,“偶尔审视”一下,两国的AI评估文化还真有些令人惊讶的相似。