
本文来自微信公众号: 未尽研究 ,作者:未尽研究
英伟达再次交出了超预期的财报,但定义下一阶段预期的关键变量,悬念保留到了3月中旬的GTC 2026峰会。下一代AI芯片路线图、Groq技术资产整合,以及与中国市场合作边界,关系到英伟达下一阶段的转型之路。
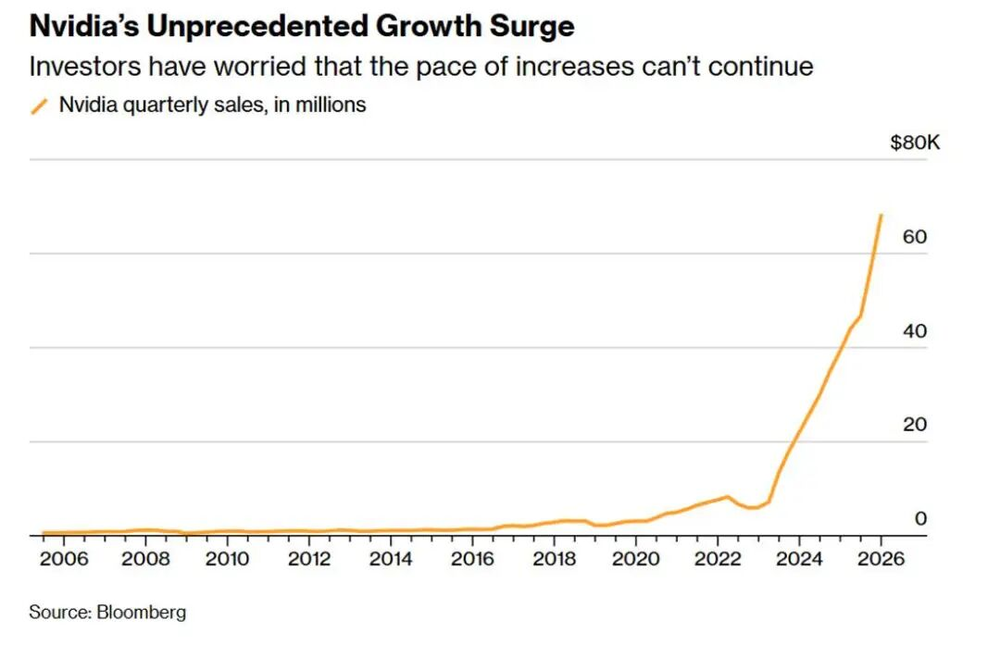
英伟达还是那个英伟达。超预期本身已被市场预期。老黄很善于整这个。四季度,公司营收681亿美元,显著超越华尔街预期的662亿美元;对下一季度的营收指引为780亿美元,同样显著超越预期。新一代Blackwell架构芯片产能持续爬坡,推动公司数据中心业务增长75%,超过公司整体营收增速,公司毛利率也回升至75.2%。
英伟达市场地位再次得到巩固。当打的Blackwell芯片,已经部署了至少9GW(吉瓦)。相比传统分散部署的GPU集群,GB300 NVL72这种高度集成、系统级设计的方案,每瓦性能提升了50倍,每token成本降低了35倍;近四个月内,对CUDA软件持续优化,让GB200 NVL72性能提升了5倍。黄仁勋证实,OpenAI最新的GPT-5.3-Codex,正是GB NVL72系统训练的。这开启了Agentic AI时代,强化了“算力即收入”叙事。
财报发布后,英伟达股价一度上涨4%,但随着电话会的进行,英伟达股价涨幅收窄。对于下一阶段的布局,黄仁勋卖足了关子,要留到GTC大会;而对中国市场的前景,黄仁勋依旧语焉不详。
开放竞争
在迎来超预期财报的同时,英伟达也迎来了更强的挑战。在电话会议上,黄仁勋好几次提到与Meta的合作,有种与AMD隔空较劲的意味。AMD刚从Meta手里签下一项跨年、跨代的算力订单,与上次绑定OpenAI一样,以约占当前10%的股权,换取多达6GW的订单。它们也是英伟达的大客户。在年初的CES上,苏姿丰宣布下半年推出MI455,对抗Rubin平台,2027年上市的MI500硬刚英伟达下一代Feyman架构。
如果只看算力性能,也许同期的英伟达芯片,都要超过竞争对手。但是,AI已经进入推理时代,不同应用场景需要针对不同约束条件优化;模型厂商正在寻找新的技术路径,也将改变芯片适配市场格局。
这正是过去一年英伟达GPU叙事出现松动的底层原因。谷歌TPU越来越能打,吸引了OpenAI与Anthropic。近期,前谷歌TPU资深工程师创立的MatX,融资5亿美元。英伟达刚收购前谷歌TPU资深工程师创立的Groq,市场非常想知道,黄仁勋将如何将其整合到自己的生态内。但Groq的人才并非全部被英伟达收入了囊中。Groq前高管创立的Positron,号称能让每瓦效能达到Rubin架构的5倍;还有不少Groq工程师流向了同样侧重内存架构创新的d-Matrix。
英伟达的风险敞口已经扩大。在这次电话会议上,黄仁勋没说的是,用英伟达芯片训练出来的GPT-5.3-Codex,在推出之后一周,OpenAI就上线了更轻量版的Codex-Spark。后者是这家AI巨头首个运行在英伟达竞争对手Cerebras芯片上的模型,响应速度更快,达到1000token/秒。这将为Cerebras芯片支持OpenAI未来的模型做好准备。Cerebras创始人Andrew Feldman称,Codex-Spark是为实时软件开发而打造的,在编程领域,响应速度本身就是产品。也许他也可以模仿黄仁勋的口吻说,“速度即收入”。
此外,推理并行、智能体并行等等已经出现的新趋势,或仍藏在实验室或论文里的新尝试,都会改变推理负载结构,从单纯的解码吞吐,转向更强调内存管理、缓存复用与系统调度能力。这种变化,正在对AI推理芯片的设计重点提出新的要求。
而且,随着AI推理逐步落地,vLLM和SGLang等主流大模型推理库逐步支持谷歌TPU、亚马逊Trainium,以及AMD的MI系列芯片。更关键的是,这些开源推理引擎和模型,正在逐渐抽象底层硬件差异,开发者不必基于GPU底层编程,可能压缩英伟达GPU在开发入口层面的CUDA生态溢价。
在电话会议上,Melius Research的Ben Reitzes很直接地提问,英伟达75%的毛利率是否能够长期保持下去。黄仁勋的回答是,“如果能向客户交付代际性能飞跃的话”。英伟达想要维持75%以上的毛利率,就意味着售价必须是成本(COGS)的4倍。而客户的自研芯片,想让TCO(总拥有成本)低于英伟达的GPU,事实上并不需要追平英伟达芯片的性能,毕竟,它可以只为此支付成本价;推理时代的规模效应,使这种成本摊销更具现实基础。
无疑,英伟达正在推动自身转型。这包括推出Triton推理服务器与KV缓存调度等工具,将竞争重心从编程接口,延伸至系统级性能与部署效率。KV缓存调度,有助于避免重复生成KV缓存,减少推理成本开销。英伟达也计划推出新的推理定制芯片CPX。此外,在年初的CES上,黄仁勋还介绍过,Rubin架构芯片将引入全新的内存存储平台,实现推理上下文在十亿级规模下的扩展。
在电话会议上,黄仁勋称,首批Vera Rubin样品已经发给客户验证,有望下半年量产出货。但无论是Vera CPU,还是Rubin GPU,更多细节会在3月16日的GTC 2026上揭晓;也许,还会有Feynman架构。
同样的,多位分析师追问了数次,英伟达将如何整合近期收购的Groq,都被黄仁勋“我有一些很棒的想法”,“你来GTC大会就知道了”挡了回来。市场期待,就像英伟达收购Mellanox那样,最终Groq的技术资产也将扩展英伟达的生态。最近一个财年,英伟达网络业务营收超310亿美元,是收购整合Mellanox技术资产当年的10倍以上。
开源生态
如果说,市场还可以等待三周后的GTC 2026,英伟达最终仍将通过产品和战略回应市场预期,那么中国市场的预期,则并非英伟达自身可以控制的变量。
在电话会议上,英伟达确认,虽然美国政府批准了向中国客户提供少量H200产品,但尚未产生任何收入,相关产品是否最终能够顺利进入中国市场仍存在不确定性。公司在最新指引中依然未计入来自中国数据中心业务的潜在收入,只是表态称,在倡导美国在全球竞争的能力基础上,“我们将继续与美国和中国政府接触”。
今年1月,在美国商务部放宽了对华出口H200芯片的限制后,英伟达在中国市场的命运,又交到了美国国务院、国防部和能源部的手中。15日,美国商务部工业与安全局(BIS)发布最终规则(Final rule,编号2026-00789),将特定先进AI芯片对华出口从“推定拒绝”,修改为满足合规条件下的“逐案审查”。21日,美国众议院通过《AI守望法案》(AI OverWatch Act),要求国会向审查导弹出口那样,审查先进AI芯片的出口许可证。
最新BIS的合规要求包括:证明这些芯片不会挤占美国客户现在与未来的产能;出口数量不超过美国出货的一定比例;H200芯片在离境前必须经由符合资质的第三方查验;执行严格的“了解你的客户”(KYC)程序,筛查并防止未经授权的远程访问;申请人必须掌握部署于中国境内H200的任何预期(intended)的最终用户,以排除“推定拒绝”实体,或敏感用途;基于H200芯片训练的模型权重与算法,无法被“推定拒绝”实体或“未披露主体”或敏感用途访问。

在这一监管框架下,开源模型厂商若使用H200进行训练,将面临非常高的合规不确定性。因为一旦模型权重公开,申请人难以证明其不会被受限实体获取或远程访问。各类“推定拒绝”实体名单的最终审核,也涉及美国政府间多个部门。路透社报道称,中国客户暂未向英伟达下达H200芯片的订单。美国商务部官员在国会听证会上证实,截至24日,H200销售记录为零。
在电话会议上,英伟达对这一结果的表述为,“我们在中国的竞争对手,在近期IPO的支持下取得了进展,从长远来看,有潜力颠覆全球AI产业的结构。”这句话的意思,不仅仅是英伟达的收入在中国清零,而是对长期的全球竞争力的担忧。
开源模型已经成为AI生态的关键力量。行业分析师Dylan Patel认为,当中国无法再使用英伟达AI芯片时,开源模型就不会再针对CUDA架构优化,转而优先适配国产AI芯片,这不仅会削弱英伟达的护城河,更会让中国形成独立的协同生态。而当这个中国主导的生态成熟后,就会进一步扩展到全球市场。这才是英伟达最核心的顾虑。
这一顾虑正在成为现实。据路透社称,对于即将更新的DeepSeek-V4,英伟达和AMD并未如常提前获得访问权限,而多家中国AI芯片厂商已经提前数周参与适配。
英伟达的GTC,曾经是全球AI生态的交汇点。在ChatGPT尚未发布的时候,DeepSeek就站在GTC的舞台上演讲,连续三届,成为这一生态的重要参与者,直至去年首次缺席。
三周之后,GTC的舞台仍将热闹,然而,市场将从对Rubin与Groq的披露中收获更多信心,还是对全球AI生态分化趋势的重新评估,仍有待揭晓。