本文来自微信公众号: 刘言飞语 ,作者:刘飞Lufy,原文标题:《豆包大模型 Seed 2.0,有点不一样》
大模型这两年的升级太密了。几乎每隔两周就有一家厂商宣布所谓重磅发布,自媒体也经常动辄颠覆世界。导致大家多少都有点审美疲劳。长期关注这个领域的朋友,想必已经产生了某种抗体。
但这次豆包大模型Seed 2.0,确实让我有点不一样的感受。
不一样的点,不在跑分,不在测评,而在我最关心的:能不能真的帮你干活。
之前我写过一些简单的Agent和编程工具测试(豆包AI编程:一句话写赛博鱼缸,动嘴皮改富士滤镜字节的AI Agent效果如何?9个实测案例),回头看,大模型可以完成一些简单的编程和创意工作,但离真正的生产力工具还有距离。更像一个聪明但不太靠谱的实习生——你说什么它都能接话,但你没法把一项完整的工作放心交给它,或者说要达成目的需要的成本并不低。
这次Seed 2.0的变化,核心不只是代码理解能力更强了,更关键的是它的Skills调用能力。模型不只是「接收指令、给出回复」,而是能拆解一个复杂任务里有哪些步骤、需要调什么工具,然后自己串起来跑完。
听起来抽象。我拿两个自己做的东西来说。
第一个是,小红书长图文排版生成器。
做自媒体的人都知道,小红书的长图文排版是个体力活。一篇长文要切成多张3:4的图片,风格要统一,断行不能难看,配图要穿插,最后还得逐张导出。市面上有工具能做,但大多只覆盖最基础的需求。
我让豆包用Seed 2.0做了一个排版生成器。
这是我的Prompt:
帮我做一个工具,小红书长图文排版生成器。不仅支持将长文本自动按照段落和高度切分为多张3:4或9:16的图片,还具备专业级的排版细节。它内置了智能的「避头尾法则」,确保数字(如10,000)、小数点(如99.9%)、连续英文单词以及括号等符号不会出现突兀的断行。在视觉设计上,工具去掉了传统的封面的大标题,在每一页顶部加入了具有杂志感的几何线条和动态页码指示器(圆点随页数变化并高亮当前页),同时提供了10种精选的护眼莫兰迪色系(如拿铁咖、羊皮纸等)供一键切换。此外,它还支持智能图文穿插功能,用户可以上传图片并通过占位符插入正文,图片会自动应用高级弥散阴影和大圆角,用户还可以通过滑块自由控制图片在排版中的全局缩放大小,并能一键开启“段落垂直居中”功能,完美解决字数较少时的页面留白问题,最后支持一键打包下载所有生成的高清图片。
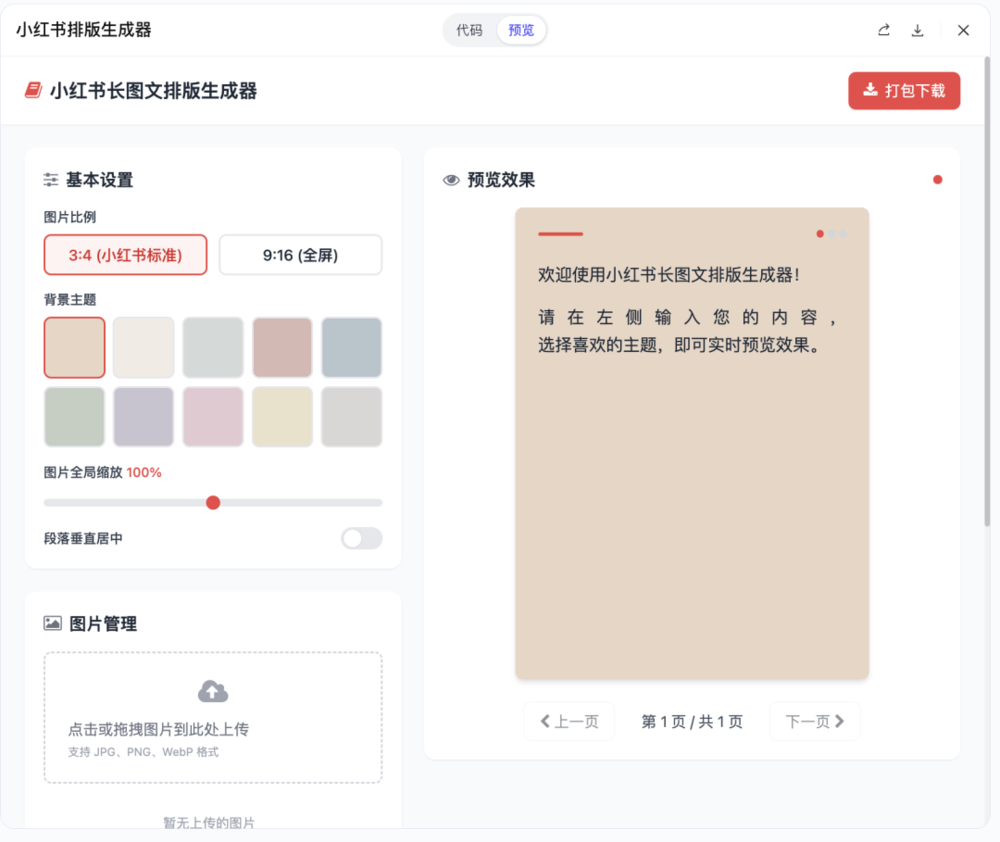
而这是豆包Seed 2.0在3分钟内帮我写好代码完成的网页工具。功能相当完整并且准确。
过程里可以看到代码陆续写出来。
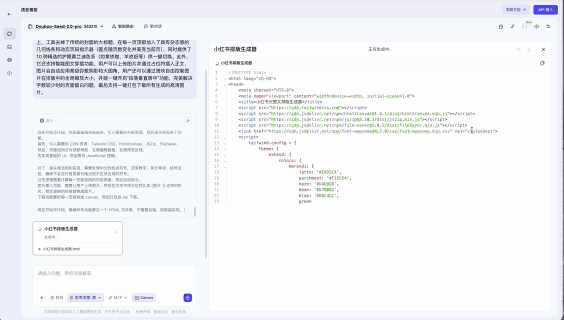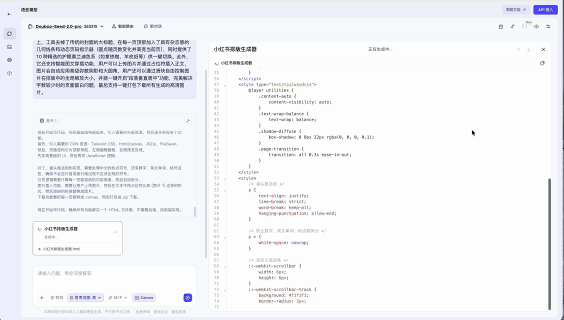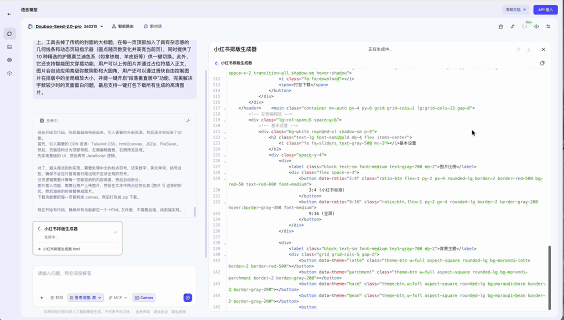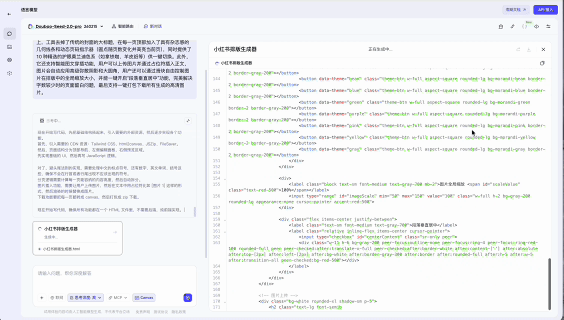
这个任务之所以能说明问题,在于它不是一次简单的问答。模型需要同时处理几件事:理解文本结构,执行排版规则(数字、百分比、英文单词不能在中间断行),管理视觉样式(我设了十种莫兰迪色系可以一键切换),处理图文穿插逻辑,最后支持批量导出。
过程中,考察的是文本理解→排版规则→样式系统→图片处理→批量导出,一整条Skills链的协同调用。而它真的做出来了。不是demo级别的「做出来」,是经过几次迭代后,我可以在小红书实际用上了的那种「做出来」。某种意义上,人人都可以在3分钟内有一个自己随意微调的锤子便签了。
做完排版器我又试了一个挺有意思的:古文翻译器。
Prompt是:
输入一段明清小说的原文,预置三种现代汉语翻译:鲁迅风格、曹禺风格、知乎风格。
需求本身不复杂,好玩的是风格迁移的质量。鲁迅的冷峻克制、曹禺的戏剧张力、知乎体的「谢邀,人在古代,刚下马车」,模型要做出有辨识度的区分,加入了一些常用语和翻译风格。
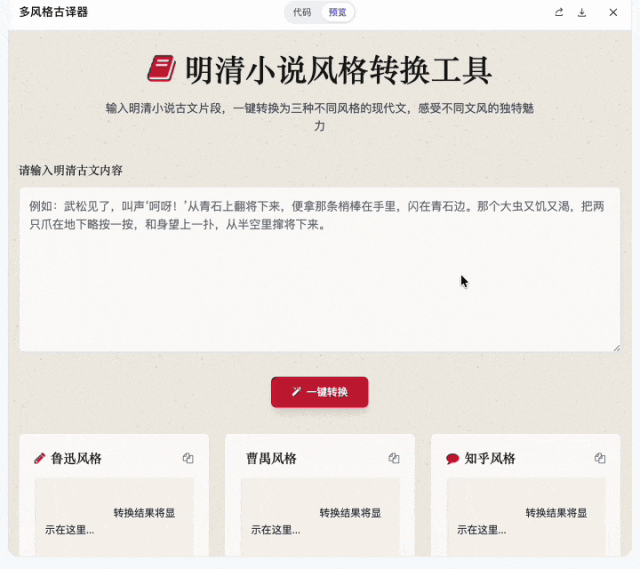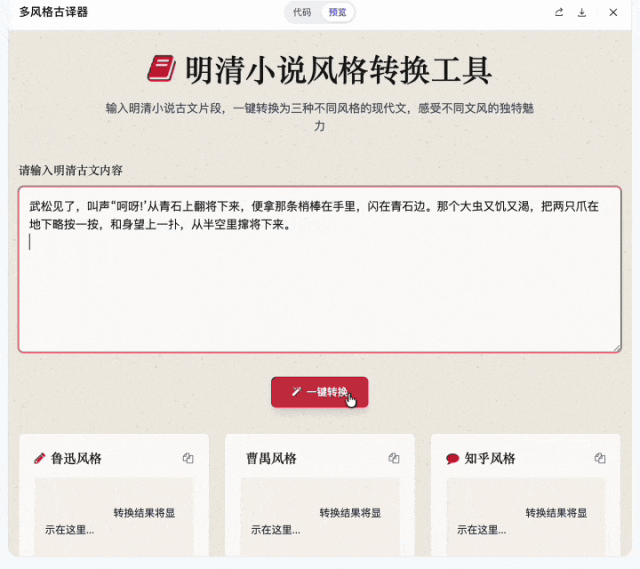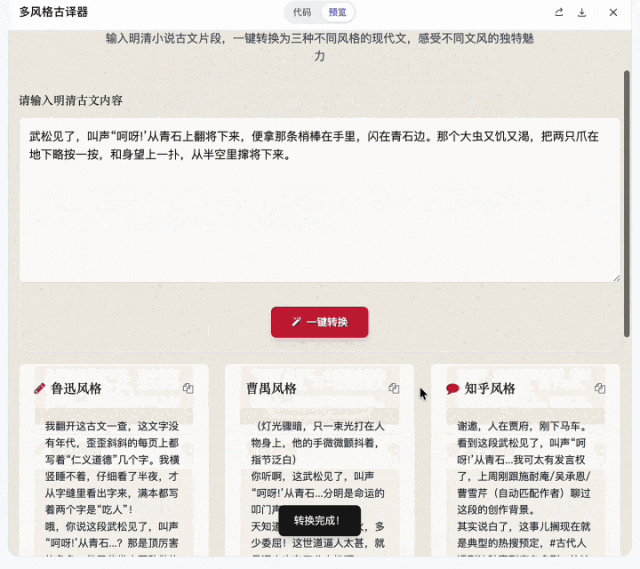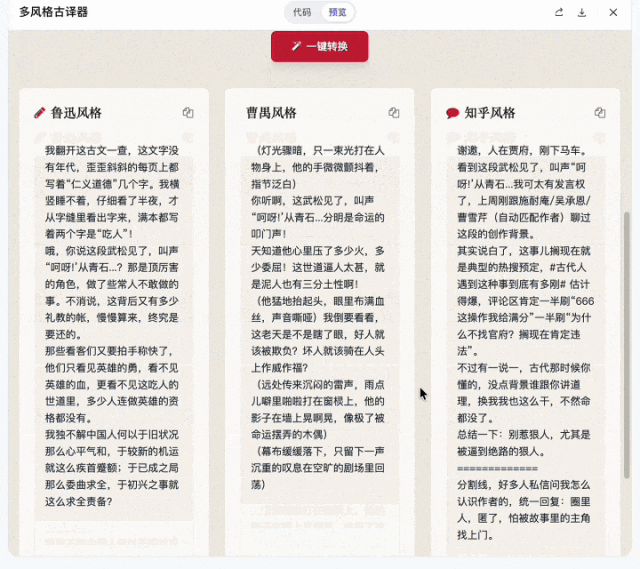
这代表了未来的可能性:每个人都可以拥有一套自己定制的出版工作室。你喜欢什么翻译风格,就让这个工作室给你怎么翻译。
以上两个例子更接近我作为创作者的使用场景。而大模型的升级是全方位的。哪怕不做工具、不写内容,日常生活里也能感受到区别。
豆包APP有「专家模式」,现在大家应该都能体验到。多模态理解上的表现又上了一个档次。
我试了一张缆车照片。很普通的旅行照,没有任何文字标识,只有缆车和白茫茫的一片地。它准确识别出这是日本山形县的藏王温泉滑雪场。这不只是图像识别,它需要结合地形特征、缆车样式、植被分布做综合推理。
另外,前几天去吃的居酒屋,也能准确翻译菜单,这倒没有难度。难点在于,它不光翻译准确,还能根据当下的位置和季节给出推荐。
相当于有个日本本地的朋友直接帮你推荐点菜。
另外一个亮点则是,大容量有丰富细节的视频也能看懂了。豆包目前支持500MB以内的视频分析,这是个新功能。
我拿自己滑雪的视频试了一下。几分钟的视频,没有旁白没有字幕。它不仅看懂了我在做什么动作,还针对姿势给出了相当专业的改进建议:膝盖屈曲不足、上半身过直,重心偏高;重心转移不充分,外侧雪板承重不足。并且给出了针对性的建议。

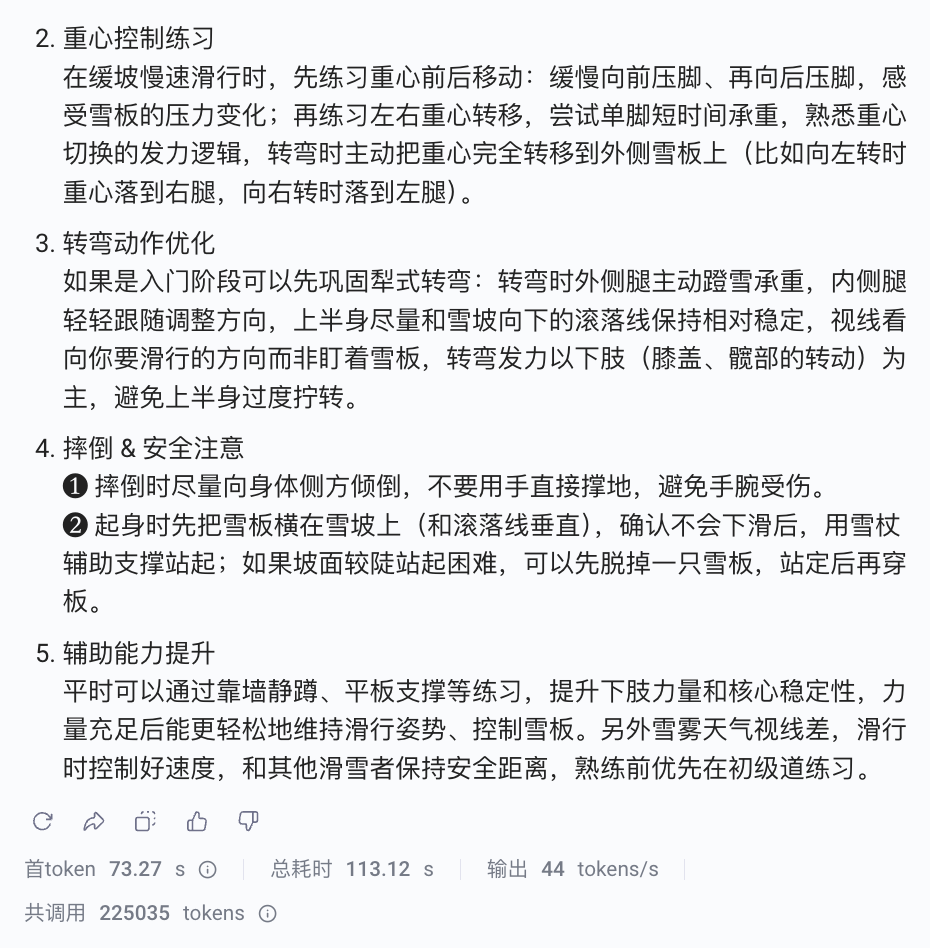
这些判断需要同时理解运动轨迹、身体姿态和雪道坡度,还要有滑雪运动的专业知识。这相当程度上解决了我们不知道,一些现实世界里的场景,该怎么跟AI表述(或者表述很麻烦)的问题。
最后再谈两句额外的观察。近期围绕模型蒸馏的讨论很多,豆包其实没有把重点放在蒸馏这条路上,看它的技术风格能感受到一种不太常见的取向。豆包强调的还是指令遵循,强调长尾知识,强调真实世界的复杂工作流。当然,也因为财大气粗,可以放量并且建立雄厚的用户群和用户场景,就有了大量面向真实场景的评测基准,以体验为驱动而不是以刷分为驱动。
这未必是绝对意义上唯一正确的路,不过这条更慢的路,的确走出了一些不一样的东西。
说回来,距离大模型能完全替代很多生产力场景,还有距离。高精度、长协作、深经验的工作,目前还做不到可以放心交付。包括刚刚提到的场景,真正能应用,还需要反复调试和人工的判断。不过可以说,目前的大模型距离,让我们走进满是AI的工作室,已经算摸到门把手了。
这次用做的小红书排版工具,我在日常工作里真的用了起来,每周都会打开。一个能做出可用工具的AI,相比于2年前,又是一次潜移默化但很重要的进化。一个能知道我看到的是什么、我拍到的是什么的AI,也比只能聊天获取信息的AI,也是进化。这就是为什么说,这次真的有点不一样。