
本文来自微信公众号: 硅星GenAI ,作者:大模型机动组
3月22日(周日),Claude.ai再次出现异常。根据StatusGator的监控记录,这次事件持续了约2小时,被标记为"响应延迟完成",属于Warning级别。听起来不严重——但如果你把日历往前翻三周,你会发现这只是这个月一长串故障里的最新一条。
仅3月17日到22日这六天内,StatusGator就记录了7次事故:3月17日宕机3小时56分钟、告警5小时54分钟;3月18日宕机9小时3分钟;3月19日Opus 4.6连续两次错误率飙升;3月21日错误率升高持续1小时35分钟;3月22日响应延迟约2小时。
六天,七次事故。这已经不是"偶发故障",而是一个关乎AI行业基础架构的系统性警报。
一、"史上最高需求"背后,是一张多米诺骨牌
3月2日,周一,UTC时间11:49。成千上万个用户打开Claude.ai,看到的不是对话框,而是一行字——"Claude will return soon.Claude is currently experiencing a temporary service disruption."
Anthropic通过WhatsApp发表声明称,claude.ai等"面向消费者的界面"已经下线,原因是过去一周遭遇了"史上最高需求(unprecedented demand)"。但"需求太高"从来都不是一个完整的解释。
从事故日志来看,整个过程呈现出一种"打地鼠"式的不稳定状态:登录路径刚刚稳定(UTC 15:47),Opus 4.6又出现新问题(UTC 17:09),随后Claude Haiku 4.5也跟着崩溃(UTC 17:56)。修了这里,那里又冒出来。
关键细节:Web界面崩溃期间,Claude的底层API在大多数时候保持稳定,因为两者运行在不同的认证路径上。这意味着通过API Key直接调用Claude的企业用户大多未受影响,而依赖claude.ai网页版的用户则完全失去访问入口。
二、3月完整宕机账单
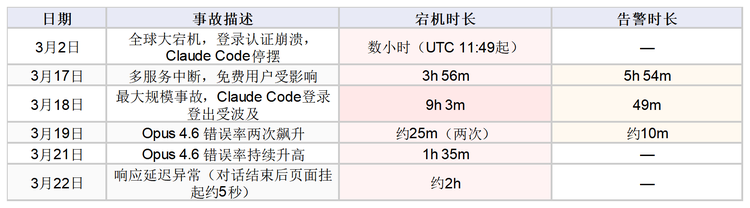
数据来源:Anthropic官方状态页+StatusGator监控记录

3月各次宕机事件时间轴
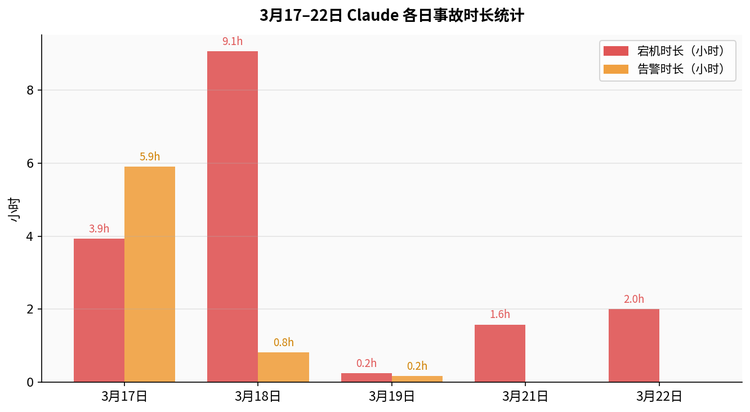
3月17–22日各日宕机与告警时长统计(小时)
根据Anthropic官方状态页和StatusGator的综合记录,整个3月的事故密度已经远超正常水平。在3月2日那次大宕机之前,Claude的90天正常运行率约为99.36%,在AI平台中属于较强水平。但3月的这份账单,正在重写这个数字。
三、"我们整个产品跑在Claude上"——那几个小时企业发生了什么
某AI初创公司创始人在宕机后发推:"我们整个产品都依赖Claude。那几个小时,我们损失了收入,也损失了客户的信任。"这句话不是个例,而是互联网上数千条控诉中最具代表性的一条。
Downdetector数据显示,3月2日那次宕机峰值时约有2000名用户提交了故障报告,报告在纽约时间早上6:40达到顶峰。AI客服系统集体下线,人工客服不得不接管;代码审查、文档生成、Debug工作流全部停摆;数据分析和决策支持系统失去响应。
更讽刺的是,很多公司甚至不知道自己对AI有多依赖,直到AI停止工作的那一刻才意识到。
一个不经意间的架构选择,决定了你在那几个小时里是"没事"还是"完全瘫痪"。
四、"依赖单一AI供应商",已经成为2026年最大的企业风险
3月2日的事件揭示了现代技术栈中一个关键漏洞:单点故障(Single Point of Failure)。当Anthropic努力解决问题时,宕机的滚动性质证明了一件事:对于重视正常运行时间的企业来说,"等它自己好"根本不是一个可行的策略。
技术风险:现代LLM服务商运行的是混合架构,横跨公有云和各种托管服务。用户看到的是Claude挂了,但真正的根源可能在三层之外的某个基础设施——DNS、认证服务、CDN中的任何一个出问题,都可能以"AI供应商故障"的形式暴露出来。
政策风险:AI服务不只是技术选型,也是政治选型。一道政策令,一个供应商就可能从采购名单上消失。把所有AI鸡蛋放在一个篮子里,风险不只来自技术层面。
那些将Claude深度嵌入工作流的企业,在宕机时发现切换到竞争对手并不容易——适配层、授权差异、行为差异都会产生摩擦。多模型策略在纸面上好看,但如果从未真正测试过故障转移逻辑,等于没有备案。
五、Anthropic的透明度:做到了多少?
值得一提的是,在这一系列宕机事件中,Anthropic的信息披露相对透明——至少比行业平均水准要好。3月2日宕机发生后17分钟内,Anthropic就在官方状态页发布了公告。3月17日那次,公司甚至主动说明"目前只有免费用户受影响",帮助付费用户快速判断自己的情况。
但透明度不等于完整的技术复盘。截至目前,Anthropic尚未就3月的连续故障发布系统性的根本原因分析(RCA)报告。StatusGator的评级显示,Anthropic官方承认故障的平均延迟在15到30分钟之间——这意味着如果没有接入第三方监控,你将比官方状态页的用户晚知道至少一刻钟。
六、怎么办?三个今天就能开始做的事
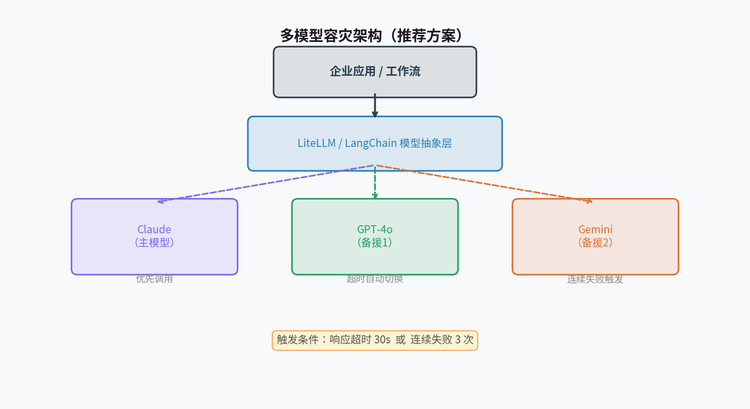
多模型容灾架构示意图:Claude为主,GPT-4o/Gemini为备援
这不是一篇劝你"抛弃Claude"的文章。Claude依然是目前市面上能力最强的通用模型之一,这一点毋庸置疑。但这一系列宕机,是一个清醒的信号:
把AI当公共基础设施用,就得用管理基础设施的方式来管理AI。
API优于Web界面。
Web界面有认证服务、CDN、UI渲染等额外的故障点。生产系统应该通过API Key而非Web登录来调用Claude,这样在Web崩溃时往往仍可正常工作。
部署多模型故障转移。
使用LiteLLM或LangChain这类模型抽象层,将Claude设为主模型,OpenAI或Gemini设为备援,设置超时阈值(如30秒)和连续失败次数触发切换(如3次)。这个架构改动一天内可以完成。
不要等官方状态页。
StatusGator等第三方监控工具能比官方提前15到30分钟检测到故障信号。接入主动监控,而非被动等待绿灯亮起。
写在最后

这个月,Claude宕机的频率已经高得让人麻木。
对个人用户来说,这是一次不便;对把Claude嵌入核心业务的公司来说,这是一场没有预警的真实危机演练。AI行业正在经历一场从"新技术"向"关键基础设施"的身份转变。而基础设施要求的是99.9%的稳定性,不是一条"我们正在努力恢复服务"的状态更新。
下一次大宕机,不是"会不会"的问题,而是"什么时候"。
真正的问题是:那时候你的系统,能撑住吗?
数据来源
•Anthropic官方状态页:status.anthropic.com
•StatusGator:statusgator.com/services/claude
•IsDown:isdown.app/status/claude-ai