
本文来自微信公众号: 硅星GenAI ,作者:董道力
3月25日,首尔证券交易所开盘不到两小时,SK Hynix跌近6%,三星跌4.8%,KOSPI指数单日大跌3%。同一天,美股的Micron跌7%,SanDisk跌6.8%,Lam Research跌5%。
全球的内存公司迎来黑色的一天,堪比DeepSeek在春节引发的核爆。
而引发这波跌停潮的,是谷歌研究院发布的一篇博客文章。博客介绍了一个叫TurboQuant的压缩算法,说它能把AI的KV Cache存储需求降低6倍。
市场逻辑是,过去两年,内存芯片厂商的股价涨了300%,靠的是一个共识:AI越来越能干,就需要越来越多的内存,需求没有天花板。

现在Google的新算法既然是解决了“存储”的问题,那必然就打破了内存需求的逻辑。而市场也有点苦内存久已。
于是,华尔街一致认定这就是类似DeepSeek的时刻,内存股应声大跌。
这样的阵仗也迅速传递到中文世界,大家也在讨论Google又带来了一个DeepSeek时刻。
然而,这一切其实都是一场乌龙。
不止是这篇引发血案的论文都不是今天新的成果——TurboQuant论文最早于2025年4月28日上传到arXiv(编号arXiv:2504.19874),至今已经11个月。这期间,无人谈论。

而且更荒诞的是,如果你仔细阅读这个研究,会发现它跟引发内存股暴跌的逻辑毫无关系,谈不上什么DeepSeek时刻。
是的,又一场FOMO之下的诡异全民狂欢。
谷歌论文说了什么?
要理解TurboQuant,先要理解一件事:大模型跑推理时,真正的内存大头不是模型本身,而是对话过程中产生的缓存。
每当模型处理一段对话,它需要"记住"所有历史token的信息。这些信息被存成Key-Value键值对,叫做KV Cache,实时写入显存。上下文越长,KV Cache越大。一个128K context的会话,单次推理的KV Cache就可以轻松超过几十GB,对于同时服务512个用户的70B参数模型,KV Cache消耗的显存可以是模型权重的4倍。
这就是为什么大模型服务商对长上下文收取额外费用,也是"Prompt Caching"作为独立计费项出现的原因。KV Cache不是算力问题,是内存带宽和容量问题。
TurboQuant解决的,正是这个问题。
传统压缩方法有一个隐藏成本:每压缩一块数据,就需要额外存储"量化常数"(用来还原的元数据),每个数字额外付出1到2 bit的代价。压缩越多,这个overhead越不可忽视——就像买了个小行李箱,但行李箱本身就重10斤。
TurboQuant用两步解决了这个问题。
第一步是随机旋转量化(TURBOQUANTmse):对向量施加随机旋转矩阵,使每个坐标无论原始分布如何,都服从集中的Beta分布。Transformer注意力机制依赖的是向量之间的内积,不是每个数字的绝对值。旋转之后,坐标分布变得集中且可预测,可以用一套预计算好的最优标量量化表(Lloyd-Max算法)逐坐标压缩,完全不需要存储per-block的量化常数。overhead归零。
第二步叫QJL(量化Johnson-Lindenstrauss变换):第一步之后还有一点残差误差。直接扔掉会导致内积估计产生系统性偏差,影响注意力计算的准确性。QJL用1 bit处理这点残差,利用Johnson-Lindenstrauss变换保证估计无偏。
结果就是,KV Cache被压缩到3.5 bit,质量完全无损,2.5 bit时只有轻微下降。A100上,4-bit TurboQuant的注意力计算速度比PyTorch基线快约8倍。
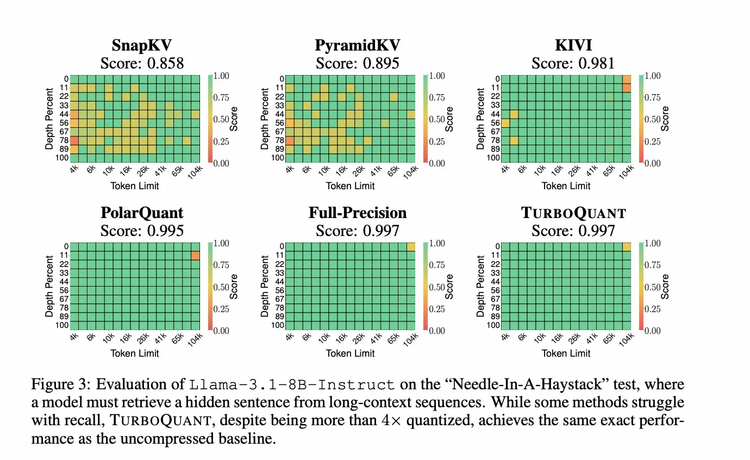
论文中做了一个测试"大模型在超长文章里找一句话的能力"。颜色越绿越好。TurboQuant压缩了4倍,颜色和不压缩完全一样。
更硬的是理论部分。
作者用香农信息论等基本原理证明,任何向量量化算法能达到的理论最优是一个确定的下界,TurboQuant距离这个下界只差约2.7倍的常数因子。这不是"我们实验上效果好",而是"理论上我们已经接近不可能更好的极限了"。
在它所涉及到的技术领域,这确实是一篇有分量的论文,它也入选了ICLR 2026主会场。
但即便在同领域里,这一篇论文之后的关注度也并不突出。
论文很硬,但和内存关系不大
直到一年后的今天。
谷歌3月25日发布博客时,推特上的传播链是这样的:科技博主截图转发,"谷歌革命性算法让内存需求降低6倍",媒体跟进报道"AI内存需求见顶",韩国财经媒体把SK Hynix、三星和TurboQuant放进同一个标题,开盘跌停。
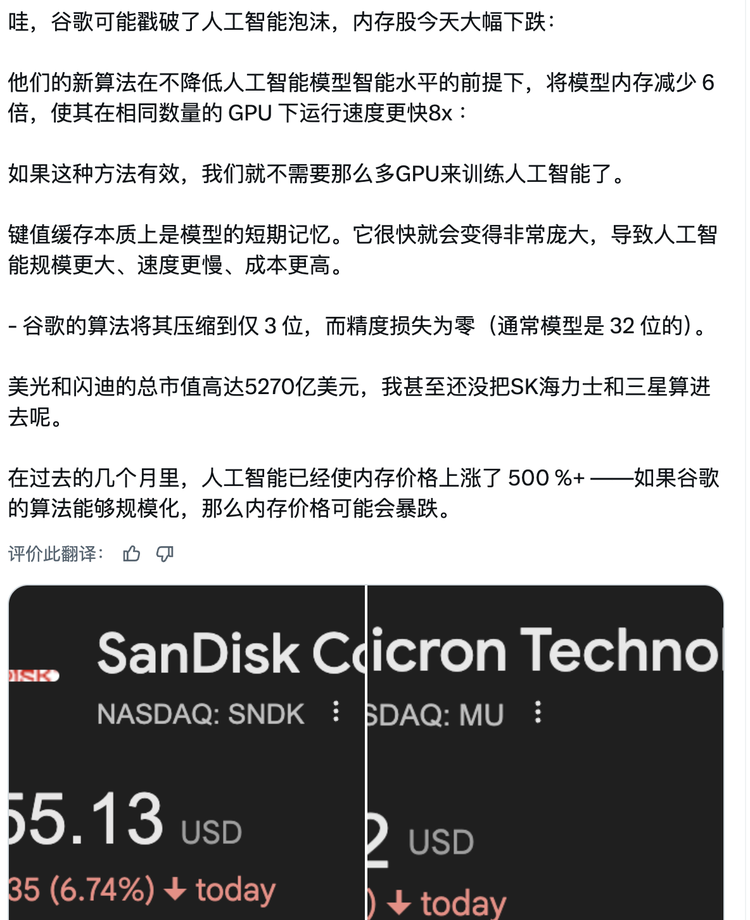
但这个推导链在第一步就断了。
TurboQuant压缩的是推理时GPU显存里的KV Cache,这是一个软件层的算法优化。
AI对内存芯片的需求来自三块:模型权重、训练时的激活值和梯度、推理时的KV Cache。TurboQuant只碰第三项,前两项完全没动。
更关键的是,AI内存需求的核心矛盾从来不是"存不够",而是"带宽不够"。HBM(高速缓存)之所以是AI基础设施的核心,是因为GPU计算核心等不及数据从内存传输过来。HBM的价值在于它每秒能传多少数据,而不只是能存多少。KV Cache被压缩到6分之一,意味着传输量也降了,这实际上是在把算力和带宽解放出来,而不是在让内存变得不重要。
还有一个问题。TurboQuant目前没有官方代码。现有的PyTorch和llama.cpp实现,都是社区开发者自己从论文里扒出来写的。vLLM、Ollama、TensorRT-LLM等主流推理框架均未集成。实验只在Gemma、Mistral等小模型上验证过。70B以上模型、MoE架构、1M token上下文
——这些AI内存需求真正爆炸的场景,论文里一个数据都没有。
这次内存股暴跌显然又是一个乌龙,市场对一篇范围有限的算法论文,经过一番诡异的折腾,最终做出了一个关于整个产业周期的判断,并直接真金白银冲击了二级市场。
你能从中看到市场今天对于AI的态度:极度FOMO,越发迷茫。
在AI不停用震惊体刺激每个人后,人们面对一个研究成果,第一时间反应已经不再是关心研究本身。比如,在这一次的闹剧里,市场真正在定价的,不是TurboQuant本身,而是一个叙事:AI内存需求可能已经见顶。
这个叙事有它的背景。美光在3月18日公布了Q2财报,营收239亿美元,远超预期,但股价在随后一周连跌四天。
市场担心的不是现在,是未来:美光Q1资本支出同比增长68%,达到53.9亿美元,这是一个押注内存需求持续增长的巨大赌注。TurboQuant的出现,给了市场一个"需求可能没那么多"的理由,两个担忧叠加,触发了这波卖出。
但这个推导链,在技术层面就已经断了。TurboQuant压缩的是推理时的KV Cache,只是AI内存需求的三个来源之一。
经济学里有个概念叫杰文斯悖论:煤炭蒸汽机效率提升之后,煤炭消耗总量反而增加了,因为更多人开始用蒸汽机。
TurboQuant如果真的落地,最可能的结果是:服务商用节省下来的显存把context window从128K做到1M,并发数从512做到5000,总内存需求持平甚至上升。
这些逻辑可能会在未来被市场理解,但此刻整个社会和市场对于AI的讨论最大需求就是情绪价值,一个长链路的技术和产业逻辑显然提供不了情绪,只有“突破性算法”和“DeepSeek时刻”可以。
所以,我们可以期待的就是,这种乌龙只会越来越多,继续频繁的发生。