
本文来自微信公众号: 未尽研究 ,作者:未尽研究
过去两年,围绕大模型商业模式的讨论,常常被压缩成一个看似简单的问题:每百万token究竟多少钱。于是,行业里最常见的比较方式,变成了谁更便宜,谁更省,谁更适合大规模调用。
但是,当智能体开始变成长时运行、分工协作、反复评估的系统之后,token的价值单位正在发生“漂移”。衡量一个模型,除了看它生成一段文本要花多少钱,还要看它把一个任务可靠做完,最终要花多少钱,而且后者越来越重要。
Anthropic最近用一篇工程文章,探讨了如何为长时间应用开发设计智能体。把单智能体和全套harness放在同一任务上正面比较,如用Claude Opus 4.5做一个2D复古游戏制作器时,solo版本运行20分钟,成本9美元;全套harness运行6小时,成本200美元,表面上贵了二十多倍。
但二者的差别并不只是“一个更贵,一个更慢”,而是结果层级完全不同。单智能体虽然做出了界面,但真正试玩时核心游戏逻辑是坏的,实体不响应输入;全套harness则把一句话需求扩展成16个功能点、10个迭代周期(sprint)的完整规格,并且做出了更多真正可用的功能,包括动画、行为模板、音效、AI辅助生成和导出分享。
这个对比揭示出一个新的经济学事实:在智能体时代,token的主要用途不再只是“把东西生成出来”,而是把一个看似完成的演示,变得真正能用。

也就是说,harness正在迫使我们从token单价转向结果单价。在旧范式里,一次调用往往对应一轮问答,token成本和输出长度大体挂钩,所以价格越低越有优势。可一旦任务变成长时软件开发、复杂工具调用和多轮自我修正,成本的决定因素就不再只是模型输出了多少字,而是系统为了得到一个可靠结果,要经历多少轮规划、执行、测试、返工和重新生成。具体而言,上下文重置虽然能缓解长任务中的一致性崩塌和“上下文焦虑”,但代价是额外的调度复杂性、token开销和延迟。换句话说,harness不是免费的工程包装,而是一种明确增加token消耗的结构性投资。
这就引出了harness改变token经济学的第一重机制:它把token从内容成本变成了控制成本。
在Anthropic的前端设计实验里,生成器和评估器形成了一个循环,评估器用Playwright MCP实际操作页面、截图、打分,再把批评反馈给生成器。这样的循环通常会跑5到15轮,完整一次可持续四小时。这里消耗的大量token,并不是为了让模型多写几段HTML,而是为了让模型在一个可验证的反馈回路里不断偏离默认答案,逼近更好的答案。token的作用从一次性生成,转向了长程控制、外部校验和方向修正;它买到的不是文本,而是路径。
更深一步看,harness还重排了token在整个工作流中的分布。数字音乐站(DAW)的实验给出了一组很有启发性的账单。也就是说,在一个复杂智能体式编码系统里,真正吞噬预算的并不是思考和审核,而是做出;但决定这笔大额生成支出是否有效的,恰恰又是那笔相对小得多的规划和验证开销。便宜的规划器与评估器,在某种意义上成了昂贵的构建器的资本监督者。token经济学因此需要用少量监督token,约束大量生成token,避免浪费。
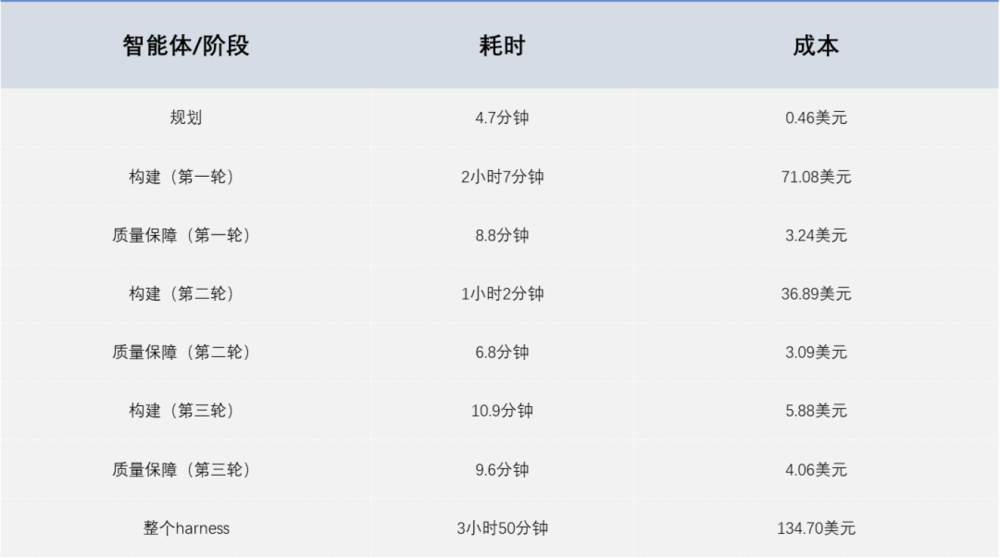
这正是harness改写成本结构的关键所在。过去人们习惯把质量保障(QA)、规划、代码审查看成模型之外的附属环节,现在它们本身成了token消费的一部分,也成了产出质量的一部分。而且评估器发现的,都不是表面瑕疵,而是能直接导致功能失效的深层bug,例如拖拽填充未真正触发、删除条件判断错误、API路由顺序导致422返回。
单智能体最大的问题,不是风格不够好看,而是会生成看起来像成功、实际上并未打通逻辑的伪成品。harness的作用,就是用额外token把这种“伪完成”打碎,让系统从演示性产出走向可验证产出。于是,token的边际价值也改变了:最贵的token未必最重要,最能减少返工和幻觉的token才最值钱。
harness的价值不是固定的。随着Claude Opus 4.6发布,作者开始主动拆除原先在4.5时期十分关键的脚手架。Opus 4.6更会规划、更能维持长时间智能体任务、更能在大代码库中稳定工作,也更擅长代码审核和消除bug。于是,原先依赖迭代拆解和频繁评估器介入的结构,被明显简化了。对那些已经落入Opus 4.6自身能力边界之内的任务,评估器会变成不必的开销。这说明harness并不是越多越好,而是只在模型能力边界附近最有经济价值。模型一旦内生地学会了某些能力,原先承担补偿功能的harness组件就会从“投资”变成“税负”。
因此,harness改变token经济学的第二重机制,是让成本结构变成动态的、边界驱动的。
每一个harness组件,本质上都编码了一个假设:模型单独做不好这件事,所以要用外部结构来补。每个harness组件都体现了关于模型自己做不到什么的判断,而这些判断需要不断压力测试,因为模型进步很快,旧假设会迅速过时。于是,今天值得花的token,明天可能就不值得花了。token经济学不再是一个固定价目表,而更像一张随模型能力移动的边际收益曲线。
放到商业背景里看,变化会更清楚。Anthropic当前官方定价已经开始对低延迟、合规性和高能力单独收费。Claude Opus 4.6的快速模式是标准价的6倍,输入和输出分别是每百万token 30美元和150美元;如果要求美国境内推理,还要在所有token类别上加收1.1倍。OpenAI也在走类似方向。
再看OpenAI。GPT-5.4标准短上下文输入为每百万token 2.50美元,输出为15美元,而一些区域处理还要加收10%;同时,内建工具所消耗的token也是按所选模型的token费率计费。这里隐含的商业逻辑是:在智能体时代,用户买的已经不只是“文本生成”,而是速度、验证、工具调用、地域处理和长时执行这些系统能力。harness越成为主流,token就越像生产流程中的通用燃料,而不是聊天接口里的字数费用。
所以,harness正在如何改变token经济学?它把token从一个静态的计量单位,变成了一个动态的组织资源。以前它是关于一次调用用了多少token;现在是关于这些token分别花在了规划、生成、验证、返工和工具调用的哪个环节,它们有没有减少失败、有没有提升完成率、有没有把一个像样的结果推到真正可交付的结果。
在这个意义上,未来最重要的价格指标,可能不再是每百万token单价,而是每完成一个真实任务的总成本,每减少一次返工所节省的预算,以及每提高一个成功率百分点所需要付出的边际token。行业真正在意的,并不是harness比单智能体更贵,而是智能体时代真正昂贵的,从来不是token本身,而是失败、返工和伪完成。harness之所以重要,不是因为它让token变多了,而是因为它开始决定哪些token值得花,哪些token只是白白燃烧。
最后,弄懂了harness/token经济学,你还去争论大模型和harness哪个重要吗?
--
参考:
https://www.anthropic.com/engineering/harness-design-long-running-apps
https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents