
本文来自微信公众号: 歪睿老哥 ,作者:歪睿老哥
良率是决定先进制程芯片能不能卖、赚不赚钱的核心,从来不是制造端一个环节的事,从设计、光刻、架构到封装,全链路都是博弈。
摩尔定律走到下半场,拼的不是谁能做更小的晶体管,而是谁能把良率玩明白。
1.先搞懂:良率到底是怎么算出来的
先给良率一个人话定义:一片晶圆上能通过测试的合格芯片,除以总芯片数,这个比值就是良率。
良率损失本质上就三个来源:工艺偏差、设计限制、生产过程中的随机缺陷。
行业为了提前算清楚能出多少好芯片,开发了好几个数学预测模型,对应不同的生产场景。
最基础的是泊松模型,假设缺陷完全随机分布。
泊松模型中,良率的最基础驱动力是缺陷密度(Defect Density,)与芯片面积(Die Area,)。
代表晶圆单位面积内的平均关键缺陷数,而决定了单颗芯片捕获缺陷的统计概率。
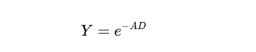
这一公式揭示了一个严酷的物理现实:随着芯片面积增加,良率在固定缺陷密度下呈指数级下降。
这个模型得出了一个很残酷的结论:固定缺陷密度下,芯片面积越大,良率呈指数级下降。
这就是为什么先进制程刚出来的时候,做不了太大的单片芯片。
大家明白可以思考一个问题。
为什么总是苹果首先占了台积先进制程产能。
除了苹果财大气粗之外,手机SOC芯片天然面积较小,是一个很重要的因素。
但泊松模型不准,因为实际生产里缺陷不是完全随机的,往往扎堆出现在某些区域,也就是缺陷集群效应。
针对这个问题,业界又做了修正,出了墨菲模型、指数模型、种子模型,还有现在先进制程常用的负二项式模型,不同模型对应不同芯片尺寸和工艺成熟度。
再往下说,缺陷密度本身也不是固定值,除了厂房洁净度,还和工艺复杂度、测试强度直接相关。
缺陷密度不仅受环境洁净度影响,还与工艺复杂度和测试强度高度相关。根据最新的技术专利研究,缺陷密度的计算正从静态统计转向多维修正模型。
缺陷密度因子N的计算公式中引入了设备测试项系数(B)、光刻系数(L)和工艺技术系数(T)。
其中,光刻系数受深紫外(DUV)层数和I-Line层数的影响显著。例如,每增加一层DUV曝光,光刻系数便增加1个单位,而I-Line仅增加0.5个单位。
这意味着工艺流程中使用的先进光刻步骤越多,累积缺陷密度越高,最终导致良率下降。
这个公式很重要,因为这就引出了第二个问题,多重曝光会显著导致良率下降。
2.光刻技术:多重曝光给良率挖了多少坑
在EUV光刻全面铺开之前,14nm到7nm这个区间,用的都是193nm DUV浸没式多重曝光技术,为了突破DUV的物理分辨率限制,把一个图案拆成好几次曝光。
但这个过程,直接给良率带来了一堆新问题。
因为缺陷密度因子会倍数的上涨,参考上面的公式。
下图是,双重曝光和双重刻蚀的示意图。
第一种方案叫LELE,也就是曝光刻蚀再曝光再刻蚀,把图案拆成两个掩模分两次做。这个方法简单,但良率完全看两次曝光的对准精度,也就是套刻误差。
只要偏一点点,导线间距就会变窄,轻了增加寄生电容,重了直接短路。要是拆成三次四次曝光,对准误差的容忍度直接指数级收缩,10nm节点控制起来难上天。
为了解决对准问题,业界又搞出了自对准工艺,也就是SADP和SAQP。
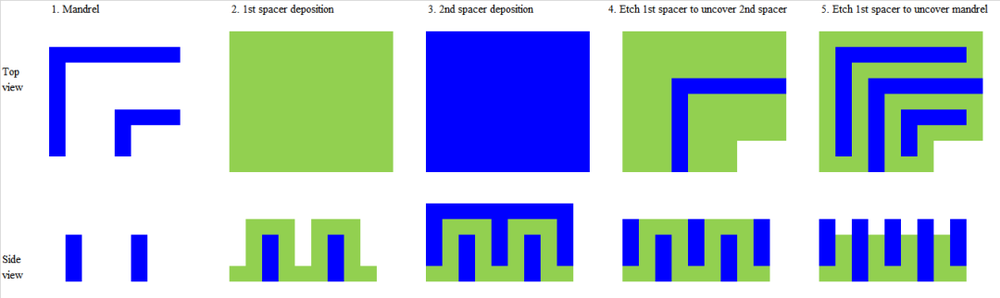
不用第二次光刻对准,靠侧壁沉积来定义尺寸,套刻误差的风险一下子降了很多,线条均匀度也更好,对关键尺寸控制很友好。
但问题也来了,SADP/SAQP多了好多非光刻步骤,牺牲层刻蚀、侧壁沉积、化学机械抛光,每多一步就多一分引入缺陷的概率,还会影响时序良率。
| 技术类型 | 对准敏感性 | 工艺复杂度 | 典型良率挑战 | 适用场景 |
| LELE | 极高 | 较低 | 严重的套刻误差导致短路 | 逻辑电路随机图案 |
| SADP | 较低 | 高 | 侧壁厚度波动影响CD均匀性 | 规律性高的金属层/内存 |
| SAQP | 极低 | 极高 | 多步刻蚀累积的物理损伤 | 先进节点的鳍片(Fin)定义 |
三种DUV多重曝光技术良率影响对比
除此之外,多重曝光还有绕不开的随机效应,哪怕加了EUV,36nm间距的缺陷率也很难降到合格线以下。
图案末端容易变圆,导线尖端回缩,要么电阻变大,要么直接断连。
要修这个问题,就得加额外的剪裁掩模,又多了缺陷风险,工艺复杂度再升一级。
3.芯片架构:不同设计对缺陷的敏感度天差地别
那么针对良率,从架构方面如何进行提升。
芯片面积是良率损失的物理基础,但不同架构,抗缺陷能力完全不是一个级别。
我们拿最常见的手机SoC和高性能GPU对比就能看明白。
手机SoC:小个子的低容错
手机SoC就是把CPU、GPU、NPU、基带全都集成在一块硅片上,为了省功耗省空间,面积一般控制在100到150平方毫米,比大GPU小很多。
小面积本身在成熟工艺下良率更高,但问题是容错性极低。
因为空间不够,几乎做不了大规模硬件冗余,CPU核心或者内存控制器那块出个关键缺陷,整颗芯片直接报废,没得救。
而且手机SoC对功耗时序要求极高,哪怕没有物理缺陷,漏电流大一点或者速度不够,不满足功耗目标,也直接当成不合格品。
| 芯片型号 | 制造工艺 | 裸片面积(mm2) | 物理特性与市场定位 |
| 麒麟8000 | SMIC N+2 | 69.99 | 中端主流,麒麟985的制程优化版 |
| 麒麟9000S | SMIC N+2 | 107.0 | 国产旗舰基准,Mate 60系列搭载 |
| 麒麟9010 | SMIC N+2 | 118.4 | 旗舰迭代,Pura 70系列搭载 |
| 麒麟9020 | SMIC N+2 | 136.6 | 顶配旗舰,Mate 70系列搭载,15%面积增长 |
对比中可以看出,麒麟9020的面积几乎是麒麟8000的两倍(比例约为1.95:1)。
最新的麒麟8000的面积只有不到70mm2,这种面积下,其良率可以做的很高。
而麒麟9020的面积则是136mm2,所以良率比麒麟8000要降低不少,仅仅从面积看,其缺陷率应该翻倍(良率=100%-缺陷率)。
高性能GPU:大个子靠架构对冲风险
高端GPU核心面积动不动就400到800平方毫米,接近光刻机的视场极限,按照泊松模型,随机缺陷抓到的概率极高,工艺初期能出多少完美核心非常低。
但GPU天生不怕缺陷,因为它是几千个重复的流处理器堆出来的,设计的时候就会多加冗余单元。
哪个单元出了问题,直接用电子熔断器把它屏蔽,然后把这颗大芯片降级卖,比如从4090降到4080。
本来要报废的芯片,照样能卖钱,把废品变成了有效产出。
这种操作就是所谓的“收割策略”,这种策略,老黄玩得最溜。
除此之外,GPU还能消化时序波动,频率降一点就能卖,不像手机SoC对时序功耗卡得那么死。
| 维度 | 手机SoC(Mobile SoC) | 高性能GPU(HPC GPU) |
| 典型芯片面积 | 100-160 | 400-800+ |
| 冗余设计能力 | 较低(空间受限) | 极高(高度重复计算单元) |
| 缺陷敏感度 | 关键逻辑失效即报废 | 支持屏蔽部分单元降级销售 |
| 性能瓶颈 | 功耗与时序波动 | 随机物理缺陷与导线电阻 |
| 主要应用策略 | 追求高全功能产出率 | 追求分级销售(Binning) |
手机SoC和GPU良率特征对比表
4.先进封装:芯粒把良率逻辑彻底改写了
除了架构方面,先进封装也是提升良率的利器。
单片集成碰到了面积墙和成本墙之后,行业都开始转先进封装芯粒架构,良率的逻辑也变了,从单片良率变成了系统级良率。
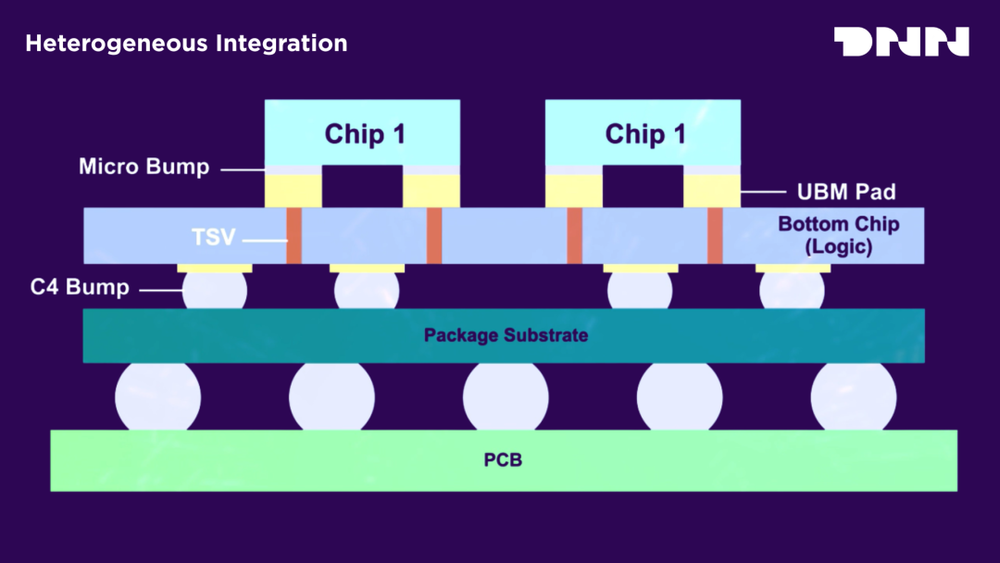
芯粒的核心逻辑就是分而治之,把一个800平方毫米的大芯片,拆成四个200平方毫米的计算芯粒加一个成熟工艺的I/O芯粒,总的合格产出比做单片高很多。
第一个好处是缺陷隔离,一个芯粒有问题,只扔这一个200平方毫米的,不用扔整个800平方毫米的大硅片,3nm初期良率不稳定的时候,这个成本优势太明显了。
第二个好处是异构优化,I/O和模拟电路在先进制程没什么收益,扔到12nm或者28nm这种高良率成熟工艺,只把核心计算放3nm,整个系统的复合良率直接涨很多。
但先进封装也不是没成本,它把良率压力从晶圆制造转到了封装环节。
比如2.5D封装用的硅中介层和硅通孔TSV,对准错一点、里面有空洞或者热应力出问题,整个好几万的模块直接报废。
还有多芯片良率的乘法法则,八个芯粒每个良率90%,整个系统良率就只有43%,所以封装之前必须把每个芯粒都测透,保证进来的都是已知合格芯片,不然全白给。
现在高端芯片已经到了3.5D时代,既有3D堆栈显存又有2.5D中介层,结构越来越复。
目前的高端AI大芯片(几百mm2那种)都是考虑多die的chiplet,来提升良率。
设计公司必须和代工厂封装厂从设计阶段就开始合作,把封装应力、散热对长期良率的影响都考虑进去,不是画完版图扔给代工厂就完事了
5.技术要点总结
最后,我们把整个芯片良率逻辑梳理一遍,核心要点就这几个:
1.良率是半导体行业的核心经济指标,决定了先进技术能不能商业化落地,不是只有制造端的事,是全链路的系统工程
2.DUV浸没式多重曝光技术,为了突破DUV的物理分辨率限制,把一个图案拆成好几次曝光。但这个过程,直接给良率带来了一堆新问题。
3.芯片面积越大良率越低,架构设计直接决定了缺陷容错能力,重复并行架构比高耦合单片架构更能扛缺陷
4.3nm时代传统降缺陷的方法已经碰到瓶颈,未来良率提升要靠架构容错、芯粒异构和预测性测试三个方向
所以,我们看到:即使多重曝光对良率有影响,但是,通过架构设计和chiplet等等手段,仍然可以做到比较有竞争力的良率水平。