
本文来自微信公众号: 特大号 ,作者:特大明白,原文标题:《小龙虾引发了Token荒!》
上周,来自大模型第一股智谱的一则退款公告,在圈里引起热议。
因为算力紧张、体验不佳,智谱选择给Coding Plan用户限时退款。

有小伙伴开始吐槽智谱不靠谱,其实智谱这个情况不是个案。
最近各大模型服务商都在悄悄调整自家的Coding Plan策略:
有人限购,有人停售,有人直接不开,还有人悄悄更改了套餐配额。
这究竟是为啥?
只因以小龙虾为代表的智能体,烧tokens太凶引发算力荒,服务费们卖包月卖不起了。
小龙虾们有多凶?甚至,你早上只是跟小龙虾说句「你好」,它就烧了大把Tokens。
为啥小龙虾们
烧起tokens来这么凶
按人类思维来讲,我说一句:How r u?小龙虾回一句:I'm fine。最多再来个:thank you,and you?
整个过程,就应该这么简单和直接,看着也就十几个字节。
但是,小龙虾这类智能体的工作原理非常不同,它们干起活来极度内耗。

01/固定「起步价」就很高
普通AI聊天工具起步价基本是0️⃣,小龙虾起步就10块。
你发给它的只有“你好”两个字,但它发给底层模型的,远远不止两个字。
小龙虾要先给大模型发的是本轮system prompt,好比是小龙虾的岗位说明书。

这岗位说明书,就是第一笔基础开销,起手先吃掉一大截tokens。
02/工具本身也要占Tokens
OpenClaw不仅要把「可用工具名称」告诉模型,还要把工具的JSON schema一起发过去,这样模型才能知道怎么调用。
所以,工具有两层成本:工具列表文本+工具schema,而且schema也计入上下文。
03/Skills列表也有额外开销
即便还没真正调用某个skill,系统提示词里也会先带一份紧凑版技能清单,告诉模型「有哪些技能,各自干什么」。
这又是一笔tokens开销。
工具箱已经不轻了,再背一本员工上岗手册,token不高才怪。
04/历史对话会反复重带
早上起来问了一句你好,但模型模型看到却是“你好+昨天你和我整段聊天历史”。
会话越长,每次新消息就越贵,大多数情况下,模型每次处理新消息,都要把前面的对话历史重新带一遍。
即便你做了压缩和剪裁,仍然要付出相当大的成本。
当你偶尔为小龙虾优秀的举一反三点赞,其实也在为tokens买单。
05/前序工具输出还会占据窗口
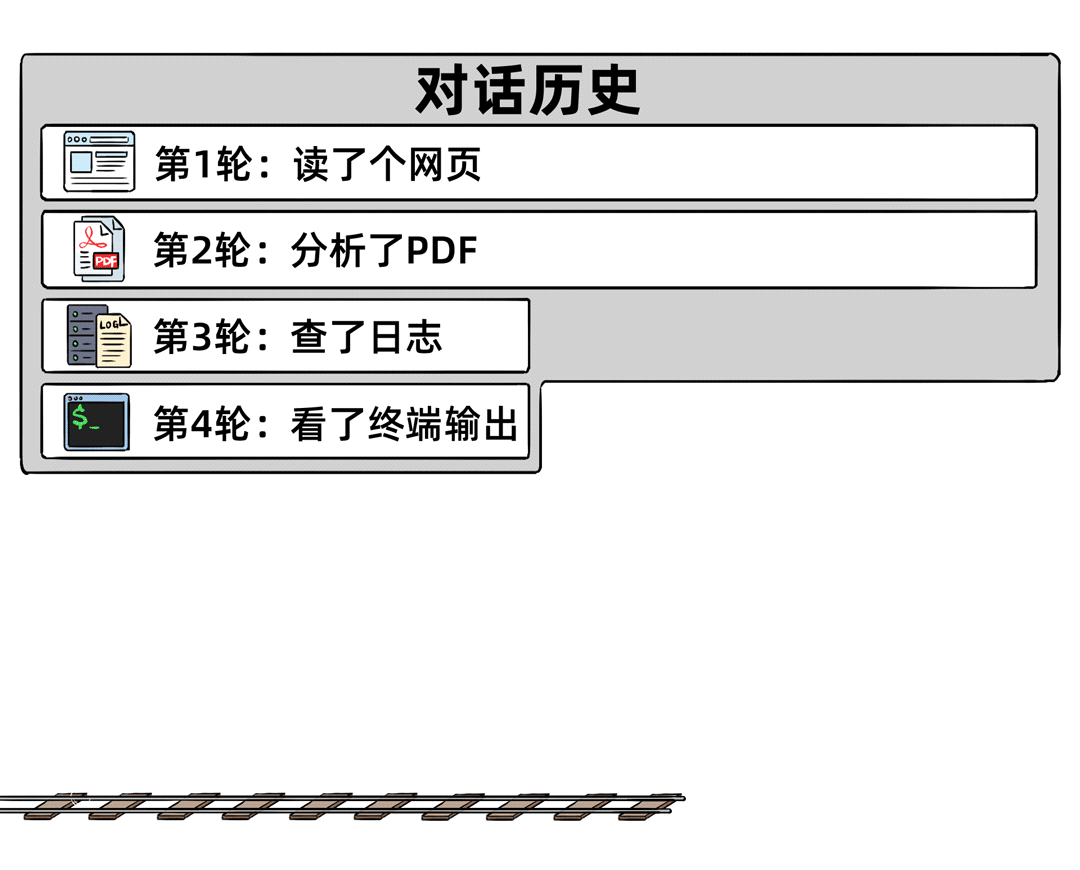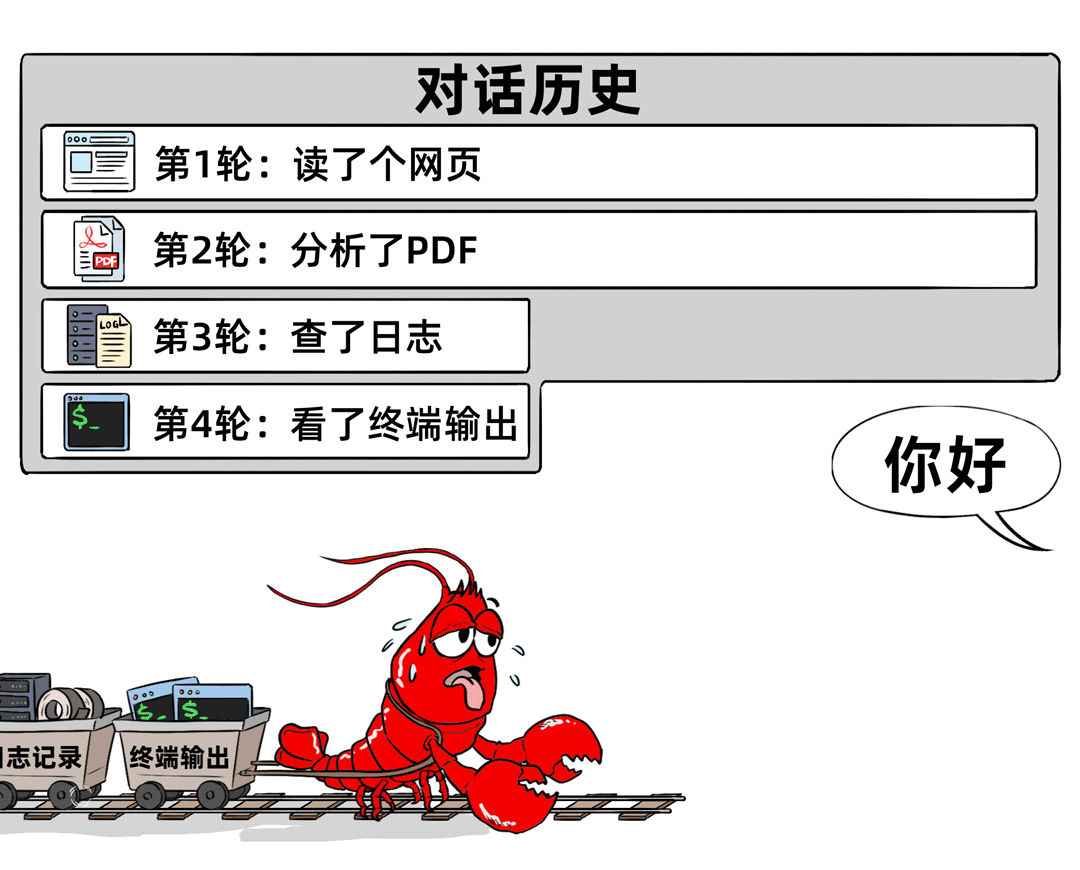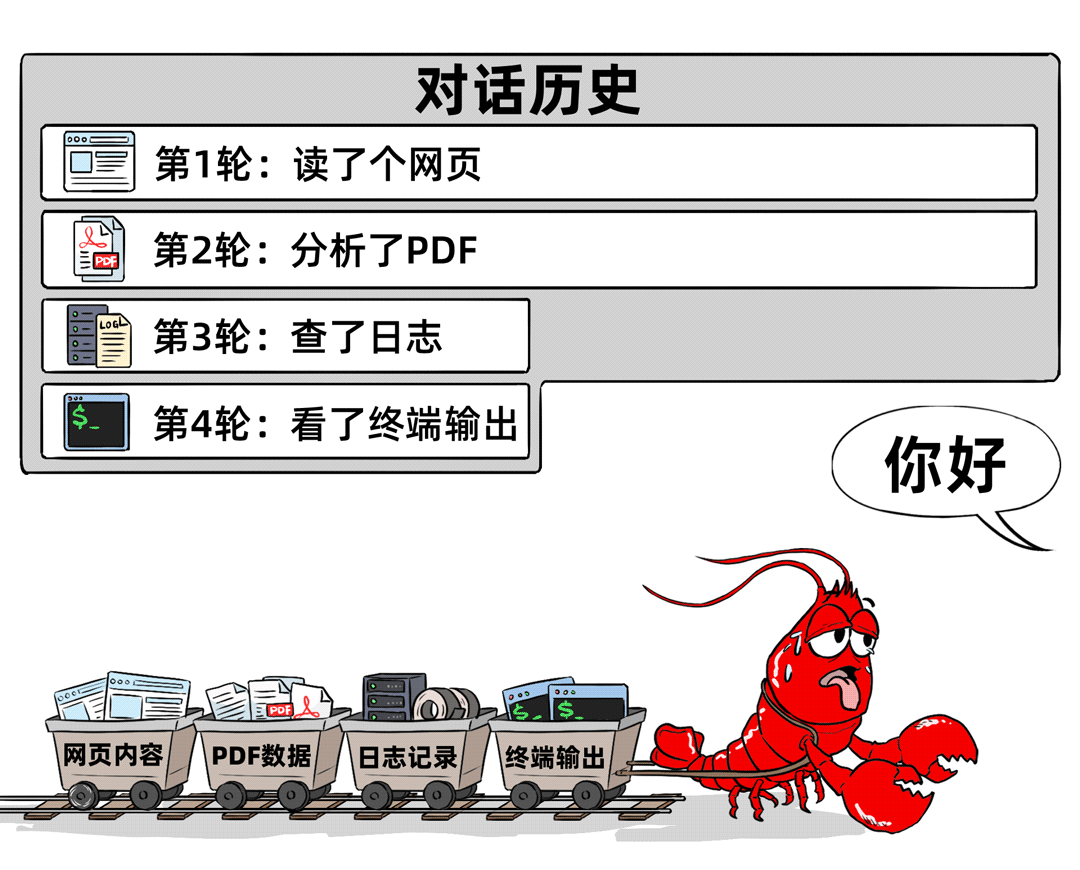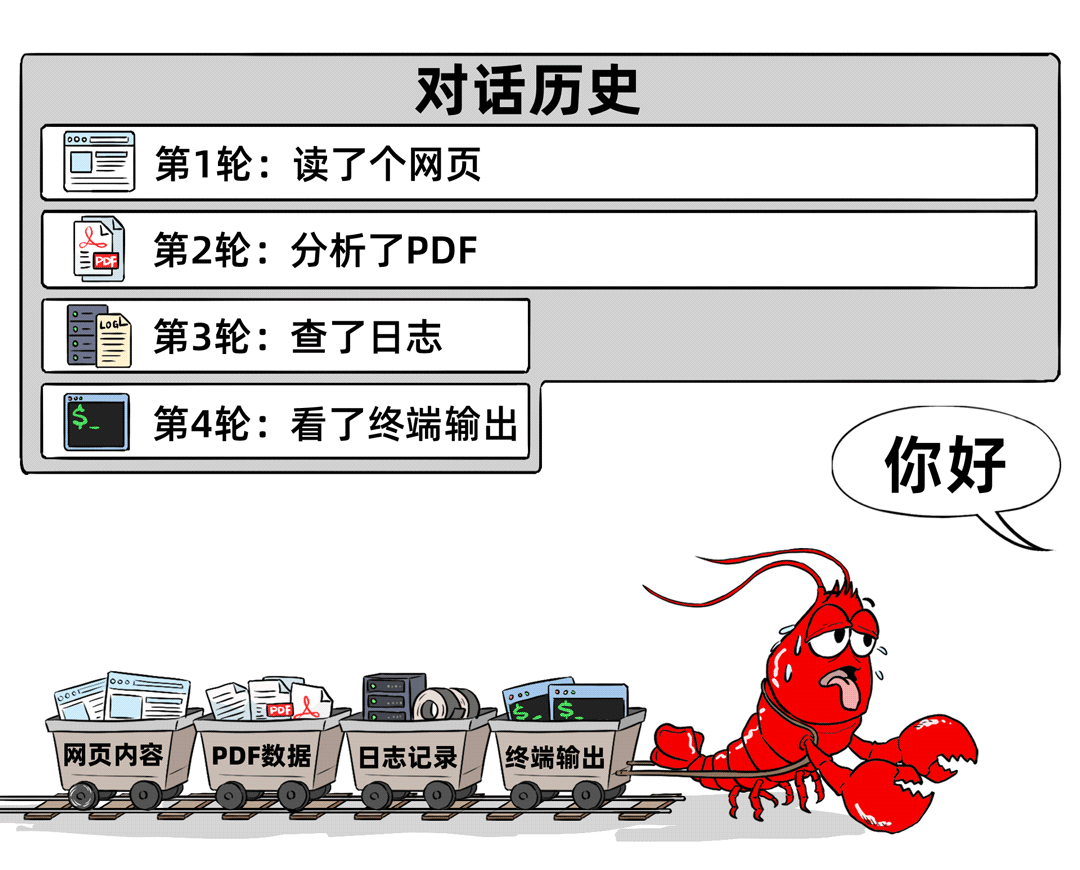
第五笔大头,是旧资料的输出可能一直挂在窗口里,这是隐形大胃王。
如果前面读过网页、文件、日志、终端输出,这些工具调用的结果和附件也都算上下文。
05/加载记忆文件,也要付出代价
你可能经常为小龙虾失忆烦恼,会在MEMORY.md文件上大费周章。
Memory不是免费外挂,它平时可以存在磁盘里,但只要本轮需要把记忆重新加载进模型窗口,它就会重新占用你的tokens。
除此之外,还有比如智能体会调用多个子智能体组团烧Token,或者你选的模型不够聪明,走弯路额外多烧Token,还有很多Skills还要调用额外的模型API等等。
智能体的工作流就是这种套路,大力出奇迹,肝就一个字,哪怕用户输入很短,系统内部也可能触发多步思考和多次模型调用。
它先把你的消息标准化、路由到当前session。
然后拼一份系统提示,把工具、技能、工作区文件、身份、时间、运行元数据都塞进去。
再把整个会话历史、之前的工具结果、附件和摘要一起带上。
接下来所有工具schema一起发给模型。
模型收到后,还要先判断这句“你好”到底只是寒暄,还是一个任务开始信号。
如果你之前有很长的会话,它还可能读到缓存里的整段大上下文。
所以,你发一句“Thank you”,它会摆开架势,大马金刀的走完整套运行链路。
等他一顿操作猛如虎的🔥完tokens,慢吞吞的回复你:谢谢夸奖,主人。
不要以为只有小龙虾这么肝,刚刚新蹿红的Hermes也一样。
所以,当我们使用这类智能体,应该养成一些好的习惯↓
①少跟龙虾寒暄,培养感情没用,把它当成喂不熟的狗,直接下命令。
②尽量精准完整的提示词,一次把任务说清楚。
③大日志、大代码库、大文档别图省事整个投喂。
④控制输出长度,明确回复的篇幅,减少废话。
⑤不要在一个Session里干到天荒地老,注意不同任务切换会话。
⑥没用的工具和Skills别整太多,不好用的测完及时删除。
⑦尽量选择更聪明的模型,少跑弯路,有些时候,便宜就是贵。
⑧有些免费AI聊天助手就能干的活(比如单步任务:P个图、翻译个文档),就别麻烦小龙虾了,浪费了Tokens效果还不好。