
本文来自微信公众号: AI Humanist by杉森楠 ,作者:杉森楠,原文标题:《我 Skill 化了耿同学的「学术打假方法论」,致敬》
我一直是耿同学B站的老粉了。除了他,我也是「来自星星的何教授」这类博主的忠实观众。
原因很简单,我对学术圈这件事真的一直很有执念。
老粉应该知道,我去年一直在准备申请日本某Top高校的AI+经营方向博士。中间经历了很多轮面试,反复改研究计划书,最后才算录取成功。硕士也在日本读,方向是经营,后来也发过相关论文。
所以论文这东西,对我来说不是一个很远的词。
我到现在还会想起硕士那段时间。每天读文献、改模型、做实验分析,整个人被数据和假设按在地上摩擦。痛苦是真的痛苦,但分析过程里突然出来的Aha moment,也是真的爽。
所以我对「学术造假」这件事一直很反感。
但我也知道,这个领域很Emmm,很复杂。很多东西外行看不出来,内行看出来也未必敢说。学术圈太熟人社会了,你要把一篇论文里的问题从图、表、正文、Source Data里一点点扒出来,再把证据摆上桌面,这件事是非常非常困难的。
耿同学让我佩服的地方也在这里。
他原本也是博士,后来退学,之后长期深耕学术造假识别。前段时间,他密集打假了不少知名学者的论文,里面还有Nature子刊相关内容。最近其中一件事有了正式处理结果,也被官媒报道。
我一直全程关注他打假的全过程,也一直有个想法:耿同学做的这些,能不能让AI分担一部分?
说干就干。
这几天我琢磨了很久,也Vibe Coding了很久,最后做出来一个初版的「学术打假Skill——research-integrity-auditor」。
项目已开源:
GitHub链接:
https://github.com/cylqwe7855-alt/research-integrity-auditor
便捷安装命令:
npx github:cylqwe7855-alt/research-integrity-auditor
先叠个甲:这个Skill还很初级,远远谈不上可以替代专家判断。它更像是一个工作流,把论文PDF、Source Data、图片、表格、异常数字和证据链先组织起来。
但我对它还挺满意。
因为它至少证明了一件事:AI现在已经可以把一部分学术打假的脏活、累活、初筛工作,变成一套可复核的流程。
我把整体思路拆成了3步。
第一步,识别PDF论文,并上传Source Data。
第二步,整理耿同学、PubPeer和其他资料里的「论文造假识别方法论」。
第三步,用Claude Code、Codex和多个Agent,按这套方法论审查所有材料。
先放一张整体思路图。
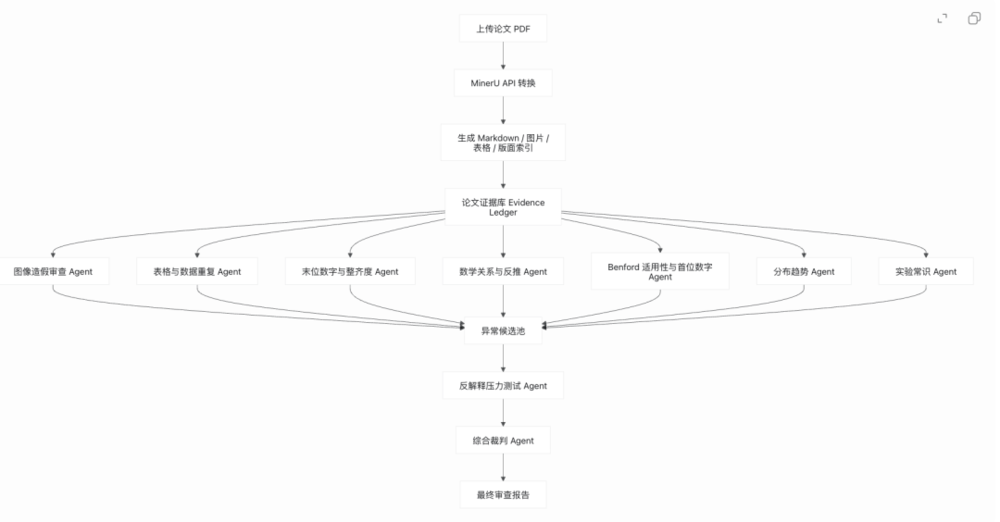
后来我又把流程继续拆细,从上传资料、PDF转换,到盲审、复核、证据整理和最终报告,一共拆成了十步。
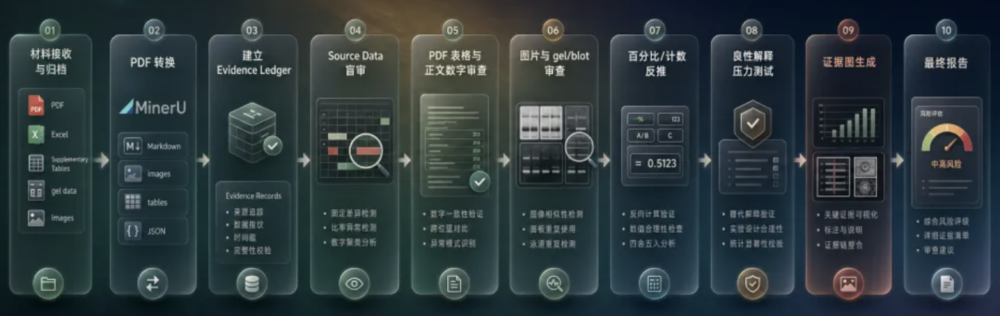
你可以先粗暴理解成三个阶段:材料输入、方法论确定、正式审查。
材料输入
第一步先说材料输入。
这一步看起来很基础,其实是整套流程里最容易被低估的地方。
论文PDF对人类很友好,但对AI来说,PDF读起来很费劲。它有正文,又有图表,还有各种跨页排版和脚注。你直接把一个PDF丢给模型,让它精细审查,效果通常不会太稳。
所以我一开始就在想,能不能先把论文拆成AI更擅长处理的格式。
现在比较稳的做法是:用PDF解析器输出Markdown和layout JSON,再按图表、表格的bbox从原PDF页面里裁图。
简单说,就是把一篇论文拆成几类材料:正文变成Markdown,表格变成结构化数据,图片单独切出来,Source Data另外上传。Markdown和CSV交给AI做文本和数字审查,图片交给视觉模型做相似性和篡改痕迹检查。
我对比了几个方案,适合英文论文的主要有Marker、MinerU、Docling。
最后我选了MinerU。原因也很简单:效果还不错,免费,而且它有API,可以嵌进我的Skill里。非广告,纯粹是这轮折腾下来它比较顺手。
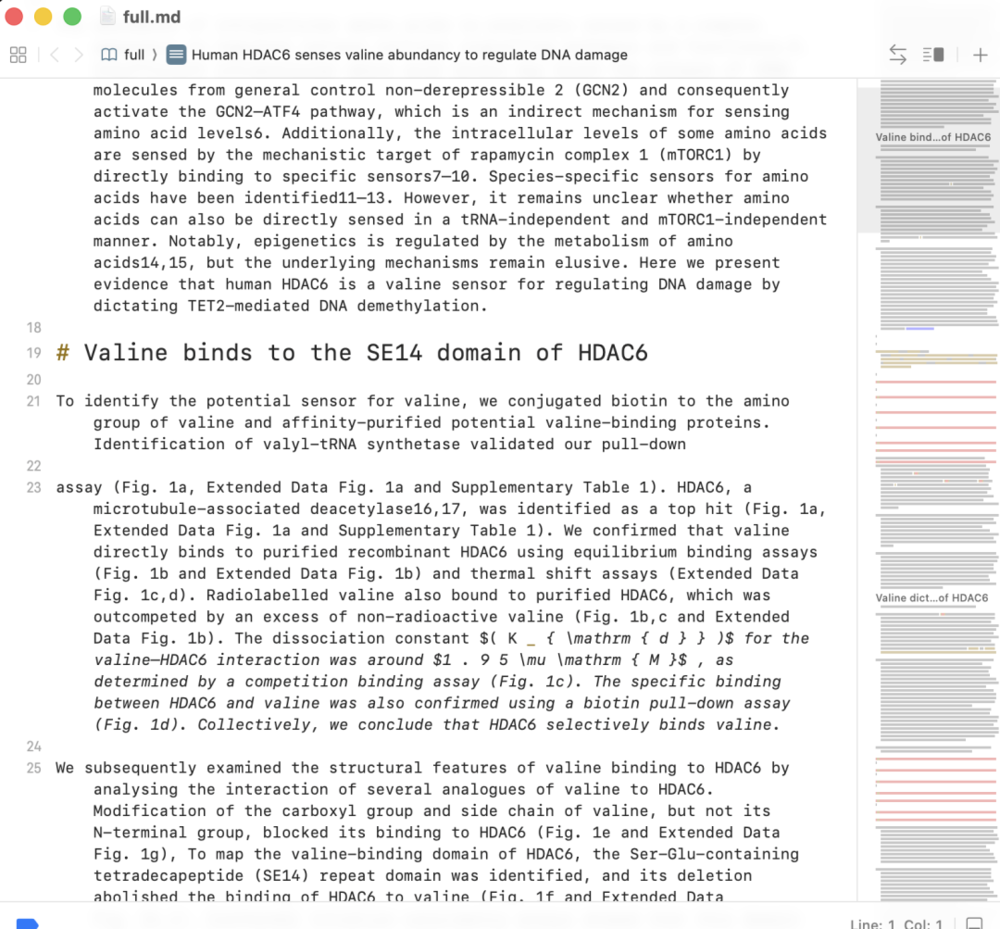
效果大概是这样。我上传了耿同学打假里提到的原论文PDF。

MinerU会先把论文整理成完整的MD文档。
同时,它也会切出大量论文图片(260张)。
整体看下来,PDF转换效果还算可以。至少正文、图表和图片都被拆出来了,后面才有继续审查的可能。
不过这里要说一句,真正的重头戏,往往不在PDF正文里,而在Source Data里。
以这篇生物方向论文为例,Source Data的体量非常大。只盯着PDF看,很容易漏掉真正关键的异常点,毕竟PDF论文是成果,是给大家看的,肯定会被认真处理。
好在Nature这种级别的期刊通常会提供Source Data下载。
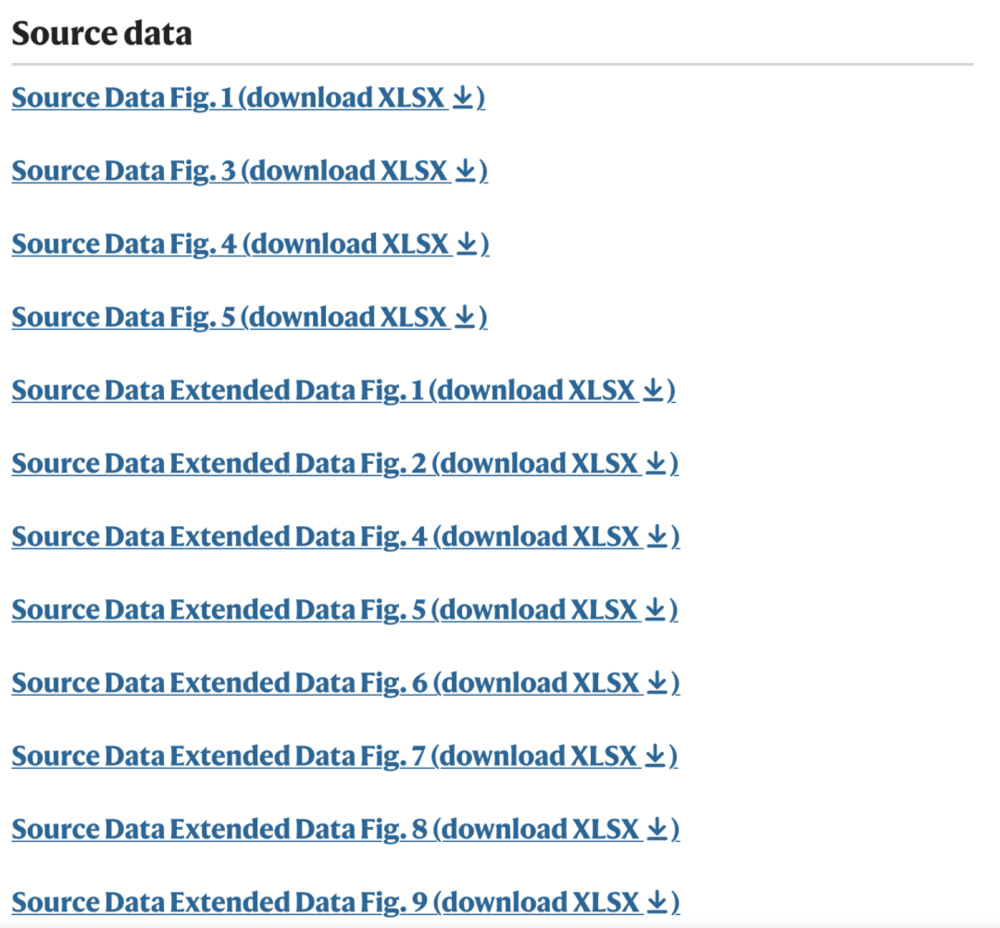
所以这个Skill的输入很简单:上传论文PDF,再上传对应的Source Data。后面的流程,基本都围绕这两类材料展开。
审查方法论的确定
材料准备好之后,第二步就是确定审查方法论。
这一步我想得非常久。
论文造假识别这件事,没法只靠一句「让AI看看有没有问题」。论文里面有正文、有实验设计、有统计方法、有图像、有原始数据。不同学科的水也很深,很多异常在一个领域里可能很奇怪,换个领域又可能有合理解释。
所以我把它做出了4步。
第一,是耿同学视频里的实战方法。
我把他几条打假短视频转成文字稿,再用Codex整理成可执行的识别方法论。

第二,是PubPeer。
PubPeer是一个学术纠错平台,很多论文里的图像复用、数据异常、统计问题,都会被研究者放到上面讨论。
我用last30Days这个调研Skill,看了一下相关平台里大家最常关注哪些问题。

第三,是几家AI的DeepResearch的补充调研。
这一步主要是为了避免我的方法论只来自几个视频。耿同学的实战视角很强,但如果要做成Skill,还是要把PubPeer、论文纠错社区、常见数据审计方法都揉进去。

第四,是本福特定律。
我最早听到本福特定律,是在马督工的B站频道里。后来在耿同学评论区,也经常看到大家讨论类似的数字规律。
本福特定律,英文是Benford’s Law,也叫首位数字定律。它经常被用来做一件事:判断一组看起来「真实」的数字,是否可能被人为编造、修饰或操纵。
它的核心很简单。
在很多真实世界的数据里,数字的第一位并不是平均分布。以1开头的数字通常最多,以9开头的数字通常最少。
如果用很粗糙的话讲,就是人手编数据的时候,常常会留下心理惯性。你以为自己写得很随机,其实手会有习惯,脑子也会有习惯。
当然,本福特定律不能单独拿来定性。它只能提示一件事:这组数字值得继续查。
所以我最后把方法论整理成几类:耿同学视频里的实战线索,PubPeer社区常见问题,DeepResearch补出来的审计维度,还有本福特定律这类数字异常检测。
这套东西现在肯定还很初级。
尤其是Nature级别的论文,背后往往涉及非常具体的专业知识。人类专家都要反复核,AI更不可能一锤定音。
但问题也在这里。
很多学术造假并没有大家想得那么高级。耿同学这次打假的一些Source Data问题,就很粗糙,很草台。面对这种草台式异常,一套工程化的初筛流程,确实有可能先把问题筛出来。
我做这个Skill的心态也很简单:先搭一个能跑通的框架,后面再让更多专业的人往里加规则、加模块、加经验。
方法论定下来之后,接下来就是正式审查。
正式审查
这一步的思路其实不复杂:Markdown文档和CSV数据交给Codex做多轮审查,图片则拆给多个子Agent并行看。
Evidence Ledger证据账本
我做的第一件事,是把所有解析好的材料做成Evidence Ledger,也就是证据账本。
每一个发现都必须写成结构化记录。它来自哪个文件,哪一页,哪一列,哪一张图,异常类型是什么,风险等级是什么,有没有可能是解析错误,这些都要记下来。
原因很简单,AI审查最危险的地方,就是它会很自信地说一些没法复核的话。
没有证据账本的AI打假,本质上还是嘴炮。

证据账本之后,才开始真正跑审查。
审查内容
数值部分会看很多东西,比如正文数字、表格列之间的固定差值、固定比例、重复小数、末位数字分布、本福特定律等等。
这里举两个很典型的例子。
第一个是末位数字。
耿同学在打假时经常会关注这个点,因为很多人在模拟数据的时候,会有非常明显的心理惯性。比如某一列有40个数据,其中35个都以同一个数字结尾,这种情况就值得看一眼。
但在这个Skill里,我没有让它单纯粗暴地查「某个数字出现了多少次」。它会结合样本量、集中比例、字段类型和风险阈值一起看。

第二个是固定差值和固定比例。
耿同学之前也提到过,有些Source Data里的两列数据,每一行之间都保持同一个差值,或者固定乘上某个比例。这种机械关系非常敏感,因为它很像人工用规则批量造出来的数据。
所以我在Skill里加了几类检查:A列和B列的差值是否恒定,比例是否恒定,加数、乘数关系是否异常稳定。

整体上,Source Data里的元数据都会被比较细地扫一遍。PDF转出来的Markdown也会审,但老实说,PDF正文的审查价值没有Source Data大。
因为正文和图表通常是第一眼就会被看的地方,真正容易藏东西的,反而是那些没人愿意一行行翻的原始数据。
接下来是图片审查。
这段时间模型的视觉识别能力确实进步很快。我自己用下来也能感觉到,很多主流模型看图的稳定性已经比前两年好不少。
我把图片审查拆成多个子Agent并行跑:

分别看裁剪、翻转、旋转、亮度修改、相似图片候选这些问题。
它会给出疑似相似图片的排名,也会尽量附上页码、图注和相似度分析。
当然,图片审查仍然很难。很多论文PDF里的图本来清晰度就不高。
所以我让AI做的主要是辅助判断。比如它会计算normalized correlation,可以粗略理解成:把两张图片统一缩放、灰度化、归一化之后,看它们的像素结构到底有多像。
范围大致是这样。

跑完这些检查之后,还有一步我觉得很重要,叫良性解释压力测试。
每个异常被发现之后,都要先问:这会不会是MinerU解析造成的?会不会是PDF切图带来的?会不会是CSV格式转换出错?会不会是实验设计本来就会导致这种固定差值?
真正严肃的打假,第一步应该是先怀疑自己的工具。
如果一个良性解释能解释全部现象,风险就下降。
如果解释只能覆盖一小部分,甚至越解释越别扭,风险就上升。
最后风险会被分成四档。

所有这些流程跑完之后,Skill会输出一份完整的Markdown报告。
我还单独加了一个可视化流程。
当系统在某个CSV文件里发现异常,比如固定差值0.3,它会把对应两列数据抽出来,再调用AI生图模型生成一张标注图,把问题直接画出来。
这一步我推荐用GPT Image 2。我实际用下来,生成这类数据解释图还挺稳的,至少目前没有遇到明显幻觉。
实测结果
下面直接看实测结果。
我用这个Skill跑了一遍耿同学打假过程中提到的那篇论文。
先看PDF审查。
这篇论文总共42页。MinerU把它解析出了249张图片和13个表格,其中学术图大概235个。
完整跑完一轮之后,PDF这边没有发现特别明确的高风险问题,整体偏低风险。

这其实也在我的预期里。
PDF正文和论文图片本来就是最容易被人第一眼盯上的地方,真正要在这里发现问题,难度会很高。不过这套流程还是跑完了本福特定律、图片相似性、表格重复、末位数字、整齐度这些检查。
它也会给出一些近似候选,比如部分化学结构图相似度比较高。
重头戏在Source Data。
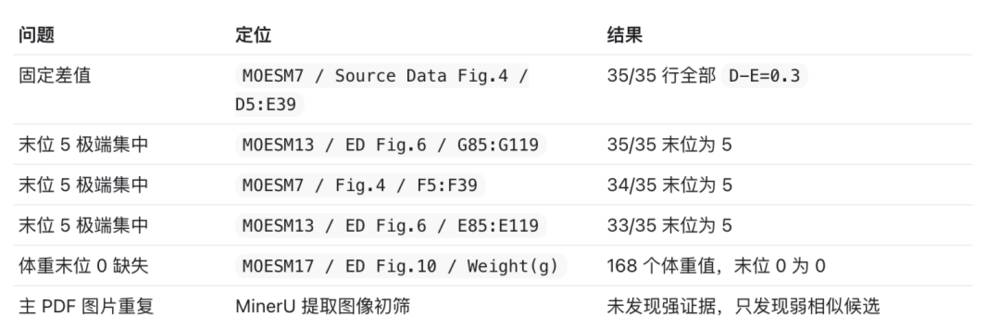
这篇论文的Source Data我下载下来有几十个CSV文件,里面有上千行数据。这里面,Skill找到了一些非常明确的异常。
比如固定相差0.3。
在某个CSV文件里,它发现D列和E列几乎每一行都精准相差0.3。这种机械关系风险很高,因为它不像自然实验数据,更像按规则批量生成出来的结果。
它还发现了多列末位数字高度集中。这个点也很敏感,尤其当集中程度高到离谱的时候,就需要继续追踪下去。
这是Skill审查出来的主要问题汇总。
我也上传了耿同学在视频里给出的部分结论,做了一个对比。
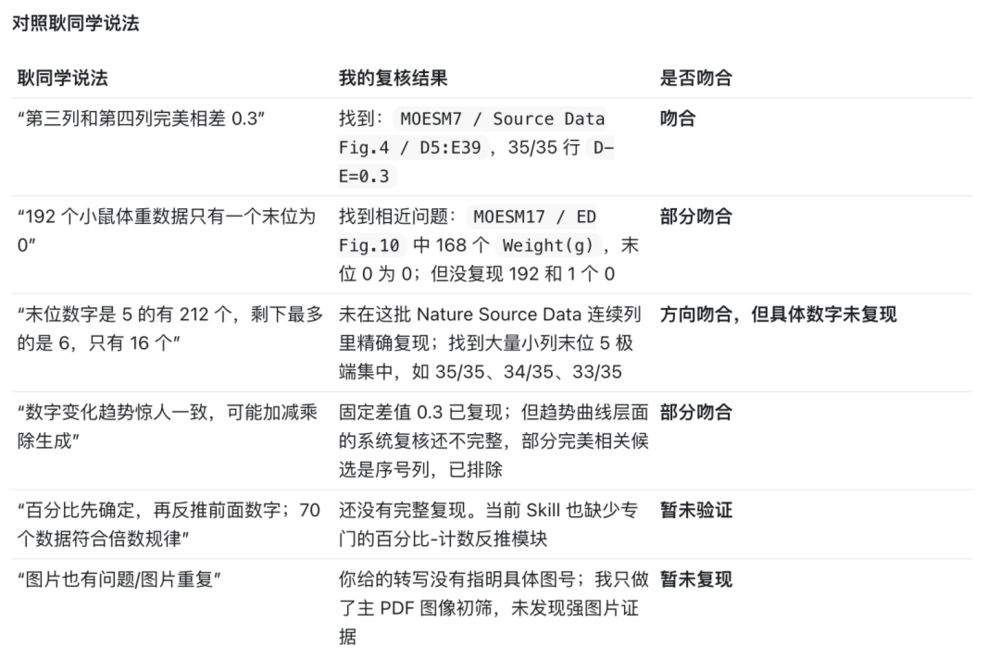
能看出来,这个Skill至少在一些关键异常上,和耿同学人工审查的方向对齐了。
不过,这并不代表AI可以直接判定论文造假。
但它说明一件事:如果材料输入足够完整,方法论足够清楚,AI确实可以把异常筛得很细。
前面提到的AI生图可视化,这里也可以直接看效果。
逻辑很简单。系统在CSV里发现固定差值0.3之后,会把相关两列数据提取出来,再生成一张带标注的解释图。
效果是这样的。
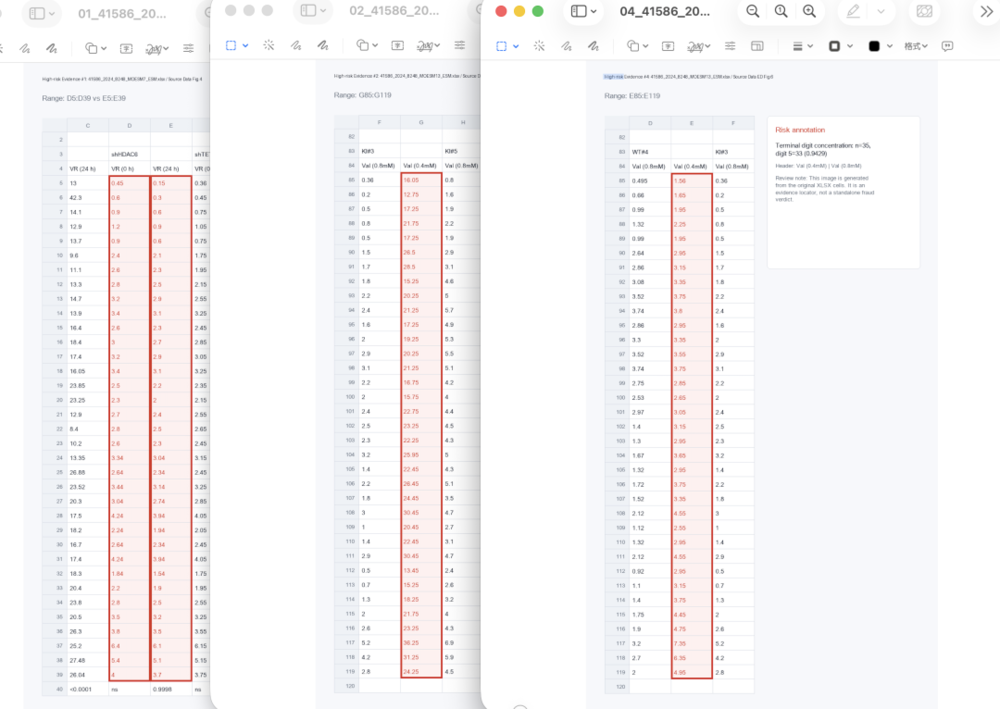
这个点我自己还挺喜欢。
因为学术打假最后很容易变成一堆表格、数字和文字。懂的人看得懂,不懂的人看两眼就划走了,不适合「打假同学」的社会性传播,懂我意思吧。
但如果异常可以被画出来,门槛会低很多。至少读者能一眼看到,问题大概出在什么地方。
到这里,整个Skill的流程和方法论就差不多说完了。
我还是要再强调一次,它现在很初级⚠️。
它的「论文造假方法论」主要来自耿同学的视频、PubPeer、DeepResearch、本福特定律和一些基础数据审计规则。放在真正复杂的垂直学科里,肯定还远远不够。
尤其是Nature级别的论文,很多判断需要非常深的专业知识。AI现在做不到独立裁决,人类专家都要反复核对,模型更得谨慎。
但我仍然觉得这个Skill有意义。
它还到不了替专家下结论的程度。它更适合做一件前置工作:把PDF拆开,把Source Data跑一遍,把异常筛出来,把证据链整理好,把每一个发现都放进证据账本。
这已经能省下很多时间了。
我会把这个Skill开源到GitHub上。懂相关领域的朋友可以随便拿去改,往里面加规则、加模块、加自己的审查经验。只要标注一下来源就行,随便造。
我也很想看看,真正做科研、做统计、做图像审查、做学术纠错的朋友,能把这套东西继续改成什么样。
学术打假最难的地方,从来不是喊一句「有问题」。
难的是把每一个「为什么有问题」,都摆到桌面上。
当然,我也知道,这类东西一旦放出来,很容易被误解。
有人可能会觉得,这是在做一个「自动判案包青天」。把论文扔进去,跑一遍,AI告诉你谁造假,谁没造假。
这肯定不行。
我做这个Skill的边界很清楚:它只负责发现异常、整理证据、降低初筛成本,不负责替任何人下最终结论。
这可能没有那种「一锤定音」的爽感,但我觉得这是做这件事最基本的诚实。
如果你只是像我一样,对学术世界还抱着一点点朴素的信任,也可以拿它去试试,看看它能不能帮你更快读懂一篇论文背后的材料。
最后还是那句话。
学术打假最难的地方,从来不是愤怒。
愤怒太容易了。
难的是在愤怒之后,还愿意一行一行看数据,一张一张比图片,一条一条写证据。
谨以此小小的「贡献」,向广大有勇气的人前进的每一步,致敬。
看到这里,辛苦啦。
感谢你的阅读和「在场」!