本文来自微信公众号: 一个生物狗的科普小园 ,作者:Y博的科普园
前段时间,我的朋友圈被一条AI看病误诊率80%的新闻刷屏了,说不定你也看到过这条消息:
可后来,我的新闻推送又给了另一条消息,AI在复杂医疗诊断里表现出色,比急诊室医生还厉害:
两个新闻都是基于顶级学术期刊上发表的研究,“误诊80%”是4月16日发表在JAMA上:

“比急诊医生强”是4月30日发表在《科学》上:

两篇论文相隔正好两周,而且都是哈佛医学院的研究人员,不过是不同研究组。
不知道你看到这两个似乎完全矛盾的研究是什么感觉?
有一个解释可以让两篇论文不矛盾:急诊医生水平太差,说不定误诊率90%,就算AI误诊率80%也吊打。
显然这是开玩笑。
下面我们还是正经分析一下,两项研究里为什么一个看上去很不靠谱,一个看上去很靠谱。
最关键的地方,或许是两项研究测试的内容与评判标准都不一样。
JAMA上的研究,也就是AI一趟糊涂的那篇论文,研究人员给AI出的考题是默沙东诊疗手册里的29个病例情景,这与《科学》上侧重急诊室诊断不同,病例范围更广。
更重要的是,JAMA论文里,评判是AI从拿到病例那一刻起就开始,初步鉴别诊断,再到实验检查,最终诊断,以及治疗方案,每一步的表现都“考”。在这个评判体系里,即便AI给出的最终诊断对了,但在最初的鉴别诊断里有失误,也会被记录扣分。
其实,误诊超过80%是在初步鉴别诊断这一步,可在最终诊断方面,失败率不到40%——不同模型失败率是9-39%。
而《科学》上打败急诊室医生的研究,侧重的恰恰是最终诊断。从某种程度上看,实际上两个研究都暗示AI在最终诊断判断上做得还不错。
此外,必须注意JAMA论文里初步鉴别诊断失败率高,建立在病例情景里,患者的信息是一点点输入给AI,比如先是患者年龄、病症表现,再加上实验检查结果,每输入一点,研究人员问一部分问题,而每一步里AI给出的答案,都会与标准答案对比,不准确就被归入失败。
这是非常严苛的标准。但这个设计很重要,因为它更接近真实的临床工作方式。医生在门诊或急诊里,永远是从一个不完整的画面开始:先听主诉,再做体检,再等化验结果回来。每一步都要在信息不全的情况下做判断,并随时准备推翻自己的初步猜测。JAMA的测试捕捉到的,正是这种在不确定性下持续推论的能力,而这目前看来,恰恰是AI最薄弱的环节。
相比之下,《科学》论文里即便是真实病例,也是把完整的电子病历一次性输入。这更像是让AI做"事后诸葛":所有线索已经摆在桌上,任务是从中归纳出答案,而不是在信息残缺时就要开始押注。两种测试场景,对应的其实是医生工作流程里完全不同的两个时刻:一个是诊断的起点,另一个更接近终点。
考虑到JAMA研究里,到最后诊断阶段,随着输入信息变多,成功率上升,再结合《科学》论文里的测试方法,可能都在暗示,有较多信息时,AI的表现会更好。
那AI看病到底行不行呢?它是那个误诊80%,还是比现实世界的医生强呢?
个人认为这其实都不是现在AI医疗需要关注的问题。
因为当下AI在医疗领域的应用,尤其是用大语言模型做诊疗,还在非常早期的阶段。
好比我们问一个读中学的孩子,啥时候能成为科学家,拿诺奖。这不光是做不做的到的问题,而是问这样的问题,对孩子没什么帮助,不会有助于他成长,去接近我们期望的结果。
最值得关注的,未必是当下的AI在医疗场景下做得有多好或多差,而是做得好的地方,为什么好;做得差的地方,原因是什么,有没有办法改进。可这恰恰是两篇论文都没有深入回答的地方:
下一步,我们怎么做,才能让模型的表现更好。
比如,AI在逐步获取信息时鉴别诊断能力差,是因为训练数据里缺乏这类"渐进式推理"的样本?还是模型本身在处理不确定性时存在结构性缺陷?如果是前者,针对性地用模拟临床对话的数据做训练或许有帮助;如果是后者,换一个更新的模型未必能解决问题,需要的可能是完全不同的架构思路。
这才是AI医疗研究下一步真正该啃的硬骨头——不是再做一个"AI能不能打败医生"的对比实验,而是设计能够定位失败根源的研究:在哪一步出错,为什么出错,改变哪个变量之后,可能有好转。没有这类研究,我们只能在"AI很厉害"和"AI很烂"之间反复横跳,却对如何推进毫无头绪。
读了这两篇论文后,其实我做了一件事,把两篇论文都传到ChatGPT与Claude上,问同一个问题,为什么都是做AI诊疗,这两篇论文得出了完全相反的结论。
ChatGPT和Claude都很聪明地抓住了两篇论文在方法学、评判标准上的差别。可也都犯了让我感到不可思议的错误,或者说是误解。
例如,ChatGPT在分析为什么AI在一个研究里看上去很成功,另一个很失败时,提出最关键的差别是,一项研究——JAMA那项,用了没有噪音的干净数据,大语言模型在这种环境下更出色:

这个解释等于是完全误解了两篇论文的结果。JAMA是用了“干净”的情景病例,可恰恰是在这项研究里,AI的成功率不高。
《科学》的论文是用了真实病例,存在潜在的“噪音干扰”,但AI在那篇论文里的表现并不差。
至于Claude,它没有犯ChatGPT的错,但它的解释里强调JAMA用了普通的大语言模型,《科学》用了OpenAI的o1推理模型,推理模型在回答诊疗这种复杂问题时更强大:

和ChatGPT一样,看似有道理,可惜不符合事实。JAMA的论文里除了用普通模型,也用了o1这样的推理模型。
《科学》那篇论文,其实也同时用了GPT4与o1,在有些检验上二者没有显著差别。
这些错误涉及的是对两篇论文最基础事实的了解,我完全没料到两个模型能出现这样的低级失误。
这或许也是当下AI用于医疗的风险:它们可以既“理解”复杂问题(两篇看似矛盾的论文,是方法与研究目的上有差异),给出看上去很好的答案,可又在一些基础事实上出错。
最后,同样值得指出的是,ChatGPT与Claude指出的“数据干净”,“推理模型”(更强更新的模型),是很多人回应AI不够好时的口头禅。似乎只要输入内容噪音小,或者用了下一代模型,之前做不到的都能实现。
这背后与其说是基于证据的合理推测,倒不如说是近乎信仰崇拜,甚至可能在干扰我们,人,做出正确的判断。
例如在《科学》这篇论文发表后,NPR做了报道,里面提到“过去的模型”表现不佳,《科学》论文展示了过去几年技术的巨大进步:

这篇报道里的“过去表现不佳的模型”,直接链接到JAMA那篇论文,也就是在记者看来,JAMA论文里的“矬”,是用了比《科学》论文里更老的模型。
这是NPR报道里极为罕见的事实错误,真相是:JAMA里用的模型比《科学》里更新。
《科学》用的是2024年9月发布的o1-preview,JAMA不仅用了o1,还一直跟踪到25年底的各个主流大语言模型:
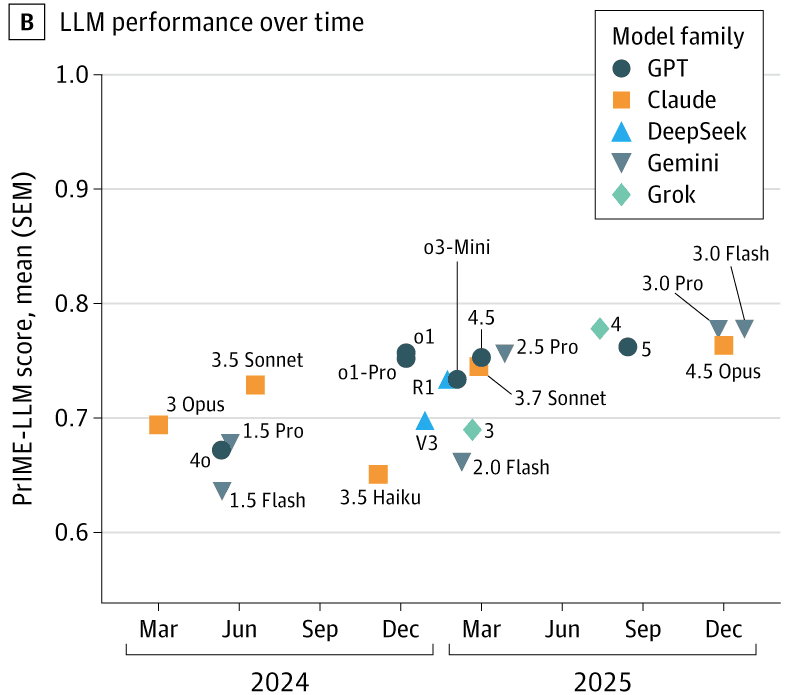
就像我们不该默认AI会给出正确的答案,我们或许也不该默认,下一个AI会给出更准确的答案。
订阅关注防失联
前沿医药,请关注
参考资料
https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2847679
https://www.science.org/doi/10.1126/science.adz4433