
本文来自微信公众号: APPSO ,作者:发现明日产品的,原文标题:《谷歌用 AI「杀死」谷歌,这场发布会看得人缺氧》
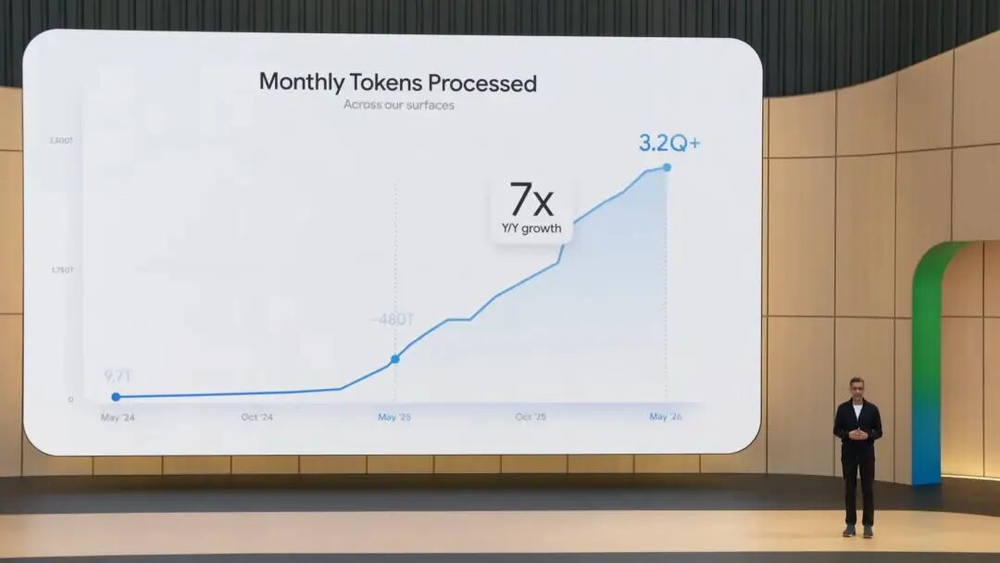
Gemini App月活超9亿,月Token处理量每月3200万亿,Nano Banana生成超过500亿张图片……
在今天凌晨刚刚结束的Google I/O大会上,Google CEO Demis Hassabis上来就抛出了这些数字。
过去一年,AI成了所有行业的主旋律,Gemini在Google的定位,也开始从一个独一的App,成了所有Google产品里的最重要的AI底层能力。
这次发布会也先从模型开始,进一步带到Coding和Agent产品。
Gemini Omni把Google的视频生成推向「世界模型」方向,Gemini 3.5 Flash则是和AI编程工具一起推向Agent开发平台。
这两个能力随后进入Google的完整生态,搜索、Gemini App、Flow、Spark、Chrome、XR眼镜和电商场景。
Gemini Omni登场,视频界的「Nano Banana」时刻来了
发布会最先被重点展开的是Gemini Omni。我们做了一组和Seedance 2.0的对比视频,看看两者的差别。
Google则是将Gemini Omni描述为一个能够「从任何输入创造任何内容」的新模型。
它把Gemini的推理能力与Google既有的生成式媒体模型结合起来,目标是提升模型对世界的理解、多模态生成能力和编辑能力。
Google强调,Veo、Nano Banana、Genie等模型已经能生成视频、图片和交互式模拟,但Gemini Omni更进一步,开始处理动能、重力等更接近物理世界的问题。
发布会现场展示的案例包括蛋白质折叠解释视频。用户只需要输入类似「生成一个关于蛋白质折叠的黏土动画解释」的提示,Omni就能把抽象科学概念转化成视频内容。
它还支持更自然的视频编辑。用户可以上传自己的视频,再用对话方式修改风格、加入元素、调整细节,甚至把一个普通圆形转成黑洞,把夜晚散步场景变成更具戏剧感的画面。
Google的说法是,Gemini Omni先从视频开始,之后会逐步走向「任意输入到任意输出」。这也是Google一直把Gemini设计成多模态模型的原因。
首个Omni家族模型Gemini Omni Flash已在上线到Google产品中,Omni Pro会在之后公布更多信息。Gemini App中的Omni功能也面向Google AI Plus、Pro和Ultra订阅用户开放。
这意味着,Gemini Omni不只是一个视频生成模型。Google想把它放进「世界模型」的叙事里:模型不仅生成画面,还要理解画面中的物理关系、运动关系和场景逻辑。
在进入Gemini App、Google Flow和YouTube Shorts这些应用之后,Omni也会让Google的生成式创作工具从图片编辑扩展到视频编辑。
Gemini 3.5 Flash上线,AI写代码进入极速模式
如果Gemini Omni对应的是生成和编辑,Gemini 3.5 Flash对应的就是速度、成本和执行能力。

Google在发布会上推出Gemini 3.5 Flash,称它是Gemini 3.5系列第一批模型之一,重点面向agentic coding、长周期任务和真实工作流。
相比3.1 Pro,3.5 Flash在几乎所有基准测试中提升明显,尤其是代码能力,以及GDPVal这类更接近真实经济任务的评测。
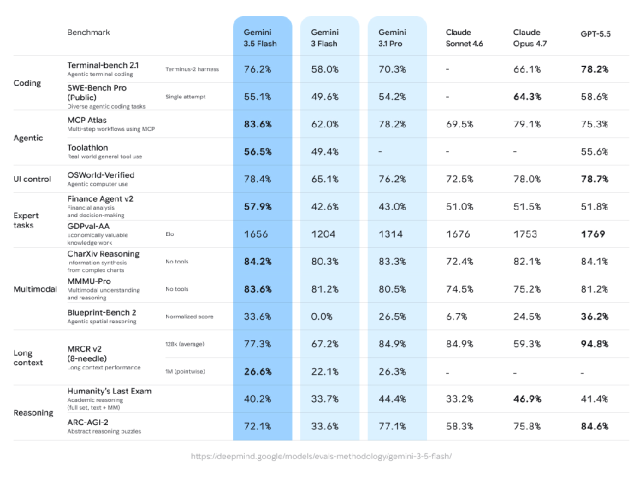
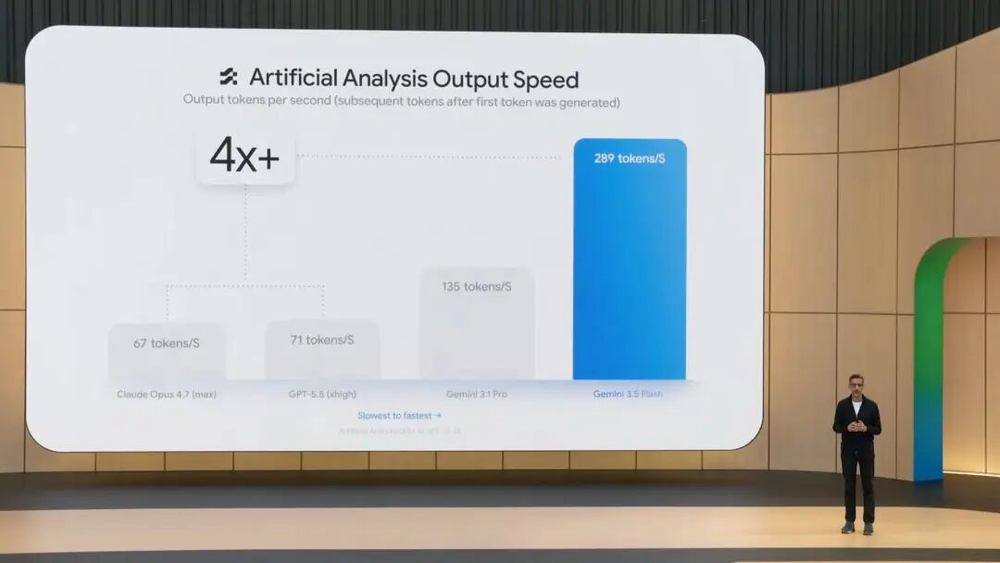
除了基准测试表现不错,3.5 Flash在输出tokens速度上比其他前沿模型快4倍,在Antigravity中经过专门优化后,速度可达到12倍。
值得一提的是,今年3月,Google内部开发相关任务每天处理约5000亿tokens,之后每隔几周翻倍,目前已经超过每天3万亿tokens。Google把这称为一个反馈循环,用大规模真实使用继续改进3.5 Flash。
与模型同步推出的是Antigravity 2.0。
它从原来的agent powered IDE,升级为一个独立桌面应用,重点转向agent first。用户不再只是让AI在编辑器里辅助写代码,而是通过Agent对话、Agent产物和多Agent协同来完成开发任务。
Antigravity 2.0加入完整CLI、Antigravity SDK、Gemini音频模型原生语音支持,并集成Android、Firebase、Google AI Studio等服务。Antigravity 2.0作为独立桌面应用,也已经面向全球用户开放。
Google在现场用一个高强度演示解释Antigravity 2.0的方向:让Agent从零构建一个可运行操作系统。这个任务由93个子Agent并行执行,持续12小时,发起超过1.5万次模型请求,处理26亿tokens,从空项目生成调度器、内存管理、文件系统等核心模块。
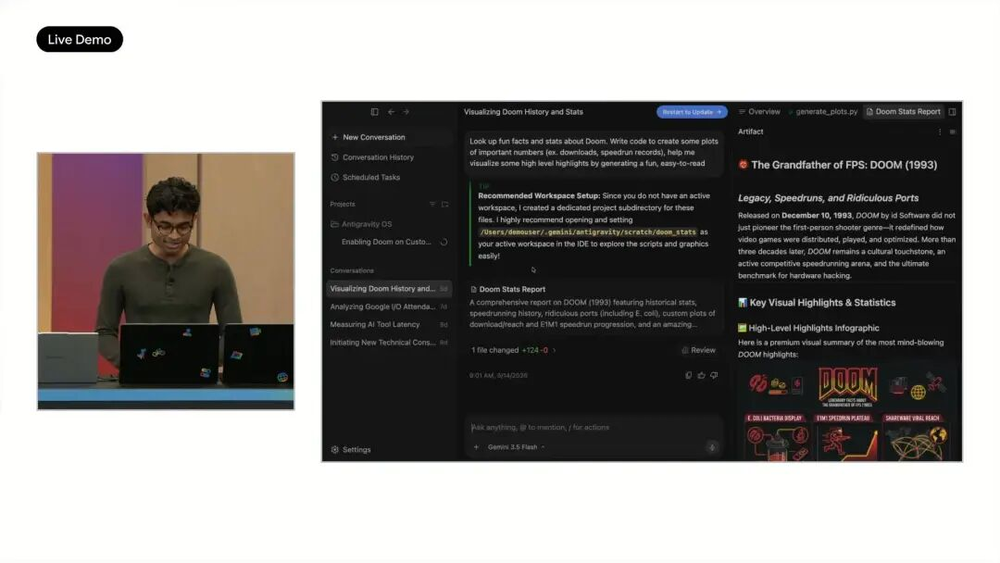
Google称,这件事在Gemini 3.1 Pro上无法完成,而使用Gemini 3.5 Flash消耗不到1000美元API credits。
现场还演示了这个系统运行SL小火车程序和Doom。由于系统最初缺少视频和键盘驱动,Antigravity又继续生成相关代码并修复,让Doom能够运行。Google还称,类似方式已经测试过照片编辑套件、实时消息应用、多用户协作平台等项目,原本需要多天的工程工作被压缩到数小时甚至更短。
Gemini 3.5 Flash已面向所有用户开放,覆盖Google产品和API。Gemini 3.5 Pro仍在内部使用和改进中,预计下个月开放。
从搜索框到信息Agent,Google重做AI搜索
模型和开发工具之后,Google把重点转向搜索。Google搜索也就是AI搜索。
Google表示,AI Mode已经超过10亿月活,查询量自推出以来每季度翻倍。
今天起,AI Mode升级到Gemini 3.5。新的智能搜索框也从当天开始推送。它支持文本、图片、文件和视频输入,并在用户输入问题时给出AI建议。
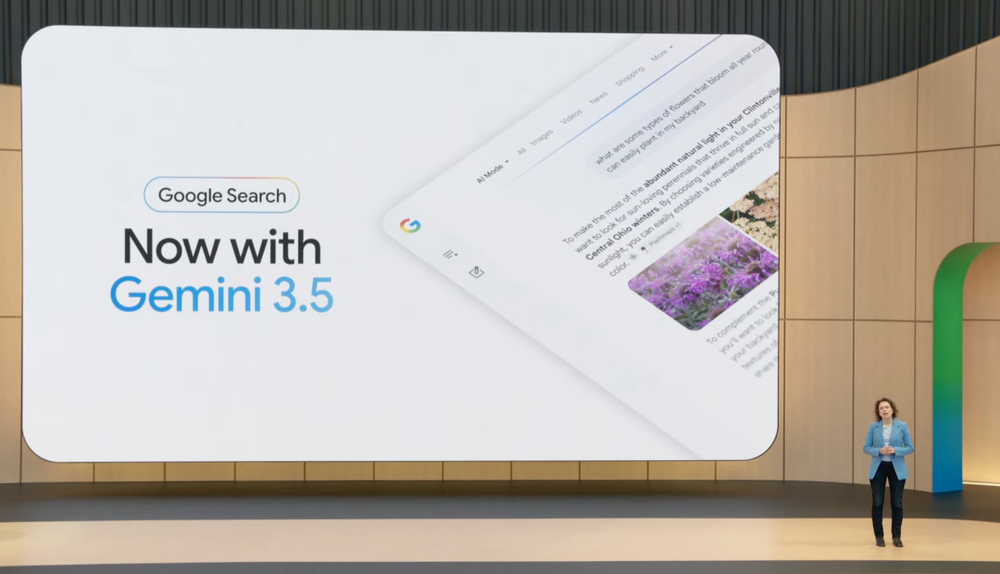
AI Overviews和AI Mode也被合并成更连续的AI搜索体验。用户可以先在主搜索结果页看到AI回答,再进入AI Mode继续追问,上下文会被保留。这个新搜索体验已在发布会当天面向全球桌面端和移动端上线。
更大的变化是搜索Agent。用户今年夏天将可以在Search中创建信息Agent,让它持续跟踪某类信息。
例如,用户可以让它监控市盈率低于15、现金流为正、负债较低的大型生物科技股票;也可以让它长期跟踪租房信息、球鞋联名和商品上新。当条件变化时,Agent会给用户发送综合更新。
Google还把Antigravity的agentic coding能力带入搜索。
之后搜索不只返回网页、摘要或卡片,也能为具体问题生成交互界面。比如用户问「黑洞如何影响时空」,Search可以生成一个交互式视觉组件;继续追问「双黑洞如何产生引力波」,Search会重新生成一个可调参数的动态界面。Generative UI with Antigravity将在今年夏天面向所有用户免费推出。

更复杂的自定义体验也在路上。
Google现场展示了一个周末计划器,Search会结合天气、地图、用户偏好、Gmail、Calendar等信息,生成一个可以继续修改、分享和同步日历的小型工具。这类自定义体验将在未来几个月先面向订阅用户开放。
关机也能跑,Gemini Spark把Agent能力搬进个人生活
消费端最重要的新产品是Gemini Spark。

Gemini Spark是一个个人AI Agent,运行在Google Cloud的专用虚拟机上,可以全天候执行任务。它由Gemini 3.5和Antigravity harness驱动,支持长时间后台任务。
用户关掉电脑后,Spark仍能继续工作。它先接入Google自家工具,未来几周会通过MCP接入第三方工具。
发布会展示了Spark的几个典型场景。
用户可以让它汇总过去一周Gemini Live的发布和进展,从Docs、Gmail和聊天记录里提取信息,再用个人写作风格生成团队邮件。
也可以让它管理街区派对,维护Google Sheets RSVP表格,跟踪谁带了什么东西,给没报名的邻居生成提醒邮件草稿,并自动生成Google Slides宣传页。
Spark还支持手机端语音输入。
用户可以一次说出多项任务,比如把所有与Sundar的会标成亮粉色,给新邻居写邀请信,创建孩子学年结束前待办文档。Spark会把这些内容分成多个独立任务,并在后台执行,结果可以在手机和电脑之间同步。
Gemini Spark本周面向部分测试者开放,下周以beta形式面向美国Google AI Ultra订阅用户推出。

Google同时推出每月100美元的新Ultra计划,并把最高档Ultra计划从每月250美元降至200美元。
今年夏天晚些时候,Spark将进入Chrome,成为能在网页中执行任务的智能体浏览器。
Gemini App大改版,还有Google版「AI晨报」
Gemini App本身也迎来了一次脱胎换骨的大改版。
Google引入了全新的设计语言Neural Expressive,加入流体动画、鲜艳色彩、新字体和触觉反馈。
新版Gemini App不再把回答呈现为大段文字,而是会根据内容实时生成更适合阅读和操作的布局,包括交互图片、时间线、嵌入式视频等。Neural Expressive现在已经在Android、iOS和网页端全球推送。
Gemini Live也被重做,打开后可以直接进入实时对话。区域口音选择将在未来几周推出。
Gemini App还加入Daily Brief。这是一个面向早晨使用的个性化摘要Agent,会综合Gmail、Calendar、Tasks等信息,整理用户当天需要关注的事项,并给出下一步行动入口。
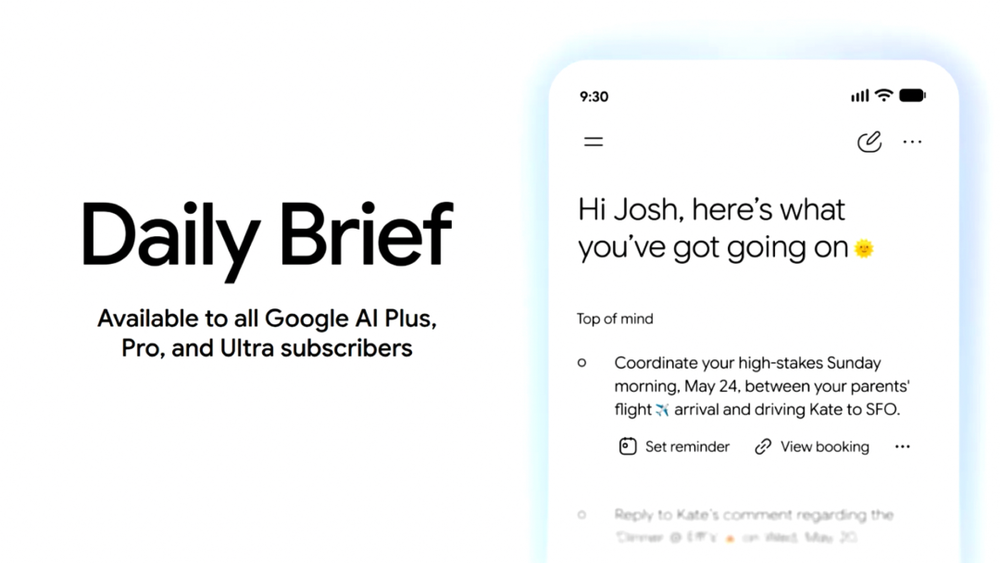
Daily Brief今天起面向美国Google AI Plus、Pro和Ultra订阅用户推出。
在更大的Gemini叙事之外,Google也更新了几个日常产品。
Google Maps最近完成十年来最大升级,并加入Ask Maps。它允许用户提出更长、更复杂的问题。例如,发布会举了一个场景:孩子掉进鸭塘,婚礼30分钟后开始,用户想知道哪里可以步行买到新裙子。
Docs也获得新的语音创建能力。用户不需要输入精确提示词,可以直接用语音把想法说出来,让Gemini从Drive调取简历,从Gmail找到活动信息,再生成Google Docs草稿。这个能力将在今年夏天面向Pro和Ultra订阅用户推出,同类语音能力也会进入Gmail。
生成能力升级后,内容来源识别也变得愈发重要。
Google称,SynthID推出三年来,已为超过1000亿张图片和视频,以及相当于6万年时长的音频加上不可见水印。接下来,SynthID和内容凭证验证会扩展到Search和Chrome。
用户可以通过圈选搜索,或者在Chrome中右键询问内容是否由AI生成,系统会显示内容来自AI、相机,还是曾被生成式AI工具编辑。
Google还宣布,OpenAI、Kakao和ElevenLabs将采用SynthID 2。此前英伟达已经加入SynthID体系。对Google来说,SynthID不只是安全功能,也是争取AI内容透明标准的一部分。
Google创作全家桶,开始围攻图片、设计和视频
在创意工具领域,Google密集发布了多款重磅产品。
Google Pics是Google Workspace中的新图片创建和编辑产品,面向派对海报、信息图、宣传图等场景。用户可以从一张基础图开始,删除元素、调整对象大小、编辑文字和翻译文字。Pics生成内容会带有SynthID水印。Google Pics将在今年夏天推出。
设计产品Stitch也迎来更新。用户可以通过一句prompt生成网站或应用界面,再通过文字或语音继续修改,比如放大标题、调整菜单、突出更多披萨选项。Stitch支持把设计导出为代码,或直接发布网站,相关更新现已发布。
Google Flow的更新尤为关注。Gemini Omni进入Flow后,用户可以基于原始视频改变环境、添加视觉效果、加入新角色,同时尽量保留原有表演。
Flow还加入新Agent,支持一次执行多个动作。比如从单张图片生成16个不同机位的视频,或把一组清晨场景批量改成深夜场景。
Flow Tools则允许用户在Flow中创建自己的创意工具,比如视频特效、手绘动画和文字分层工具,并支持分享和remix。
Google Flow Music可以把一段钢琴riff扩展成带风格方向的音乐demo。Google Flow和Google Flow Music的这些新功能已上线。
押注智能眼镜,Google再闯下一代入口
硬件部分,Google也把Android XR这个操作系统级平台,从头显、XR设备,进一步扩展到智能眼镜形态。
Android XR是Google与三星合作,并针对Qualcomm Snapdragon优化的平台。
Google表示,AI眼镜会分成两类:一类是带小型镜片的显示眼镜,另一类是音频眼镜。显示眼镜去年已在I/O展示,今年首批开发者已经开始创建显示体验,可信测试者计划将在今年晚些时候扩大。
更早上市的是音频眼镜。
首批音频眼镜将在今年秋季推出,由三星参与硬件和体验构建,Warby Parker与Gentle Monster负责眼镜设计。这些眼镜连接手机,支持Android和iOS。Gemini的回答通过耳机私密播放,而不是显示在镜片上。
发布会上,演示者可以通过眼镜让Gemini导航到上周和朋友见面的地方,中途加入咖啡店;也可以让Gemini打开DoorDash自动下单咖啡,等待用户确认;
还可以让它总结静音消息,并把家庭晚餐写入日历。眼镜还可以与手表配合,让用户拍摄现场照片,并用Nano Banana生成卡通图像,再在手表上预览。
发布会最后,Gemini的使用场景也延伸到了网络安全场景。
Google介绍了CodeMender。它是一个代码安全Agent,能够自动寻找和修复关键软件漏洞。Google将邀请一批专家测试CodeMender API,之后会更广泛推出。

整场发布会看下来,信息量大到让人有些缺氧。只是当这些AI功能真正开放给几千万、几亿人使用时,一个最现实的算账问题就直接摆在了面前:这笔庞大的算力开销,Google要怎么挣回来?
过去二十多年,Google代表的是一种典型的免费互联网模式。用户用注意力和数据换服务,Google用广告和分发赚钱。这套模式让Google成为互联网时代最强的基础设施公司。
但大模型推理的成本,和查询一次搜索结果完全不在一个量级。
长上下文记忆、多模态生成、跨应用Agent、企业级自动化,这些能力背后都是持续运行的算力消耗。AI越深入,Google越难继续用「免费功能升级」的方式来消化成本。
这就是为什么整场发布会下来,Google I/O看似讲的是体验升级,背后指向的却是订阅、企业合同、算力账单和长期服务费。
免费入口当然不会消失,因为那仍然是Google获取用户、数据和生态位置的基础。但在这些入口之上,Google正在叠加一个新的智能服务层:更强的模型、更长的记忆、更深的系统权限、更复杂的任务执行,以及更稳定的企业级服务。
换言之,Google正在从免费互联网服务公司,进一步变成AI订阅基础设施公司。
只是,问题也随之而来,用户愿意为搜索付费吗?通常情况下,不会。
可是,如果这是一个能替你全天候处理邮件、统筹任务、分析报表、接管智能家居,甚至还能帮你写代码开发App的「超级全能助理」呢?你愿意为它每月掏出几十上百美元吗?
这,正是今年Google I/O迫切想要验证的核心商业命题。而环顾如今狂热的市场,答案似乎早已不言而喻。