
本文来自微信公众号: 碳基智 ,作者:碳基智
前一阵写了篇《很多人误解了Harness这个概念》的文章,在跟评论区和身边朋友讨论的过程中发现,Harness这个概念还有挺多地方,是大家没想到或者以为很高大上,但剥开来看发现原来如此,不过如此的东西。
这一篇的主题和观点很直白,你以为Harness是AI圈涌现的又一个新的范式,实际上它的底层逻辑已经出来快80年了,理论根基就是Norbert Wiener和William Ross Ashby提出的「控制论」。
1
一年时间,AI范式换了三个,从Prompt Engineering到Context Engineering,再到今年的Harness Engineering。
之前的旧范式革新是By decade,现在的旧范式革新是By Quarter,难怪朋友们深陷AI FOMO不能自拔。
但在深入理解Harness的过程中,我发现其实很多所谓新东西的理论根基,并没有发生质的变化。
先画一张映射图,帮助大家理解,为什么我说Harness其实就是控制论:
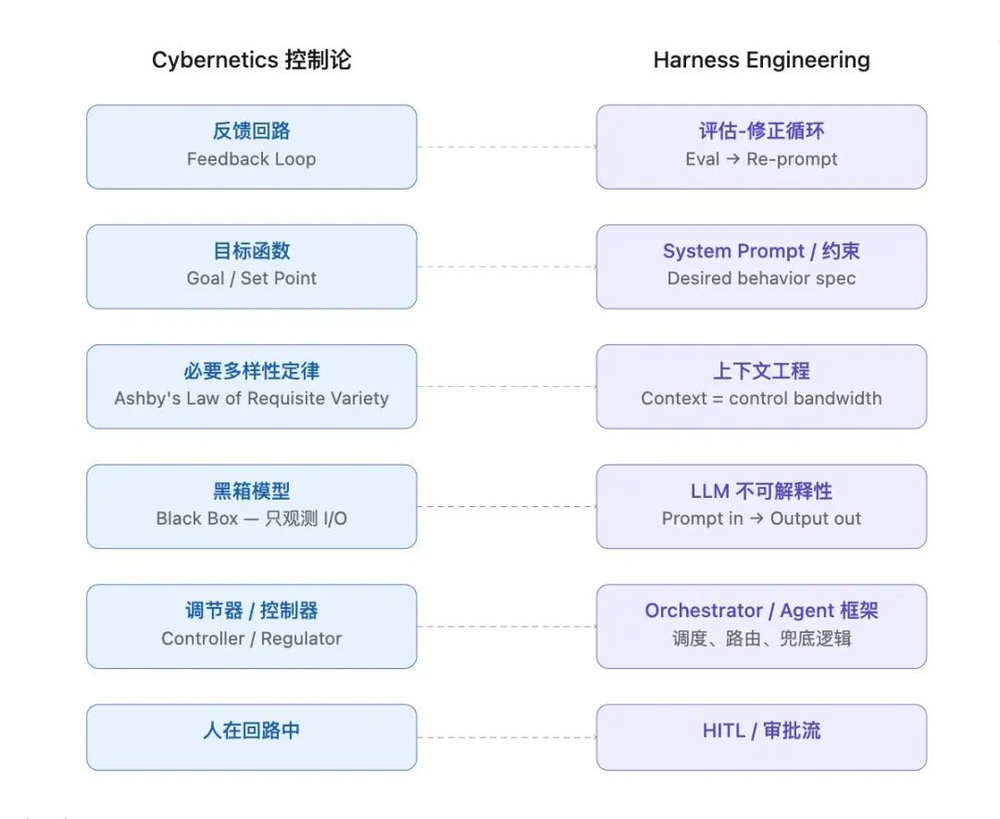
接下来,我们深入拆解。
2
控制论的核心命题只有一句话:
如何驾驭一个你无法完全理解其内部工作原理的复杂系统。
大模型就是人类有史以来,遇到的最纯粹的黑箱。几百亿到上万亿参数,没有任何人能解释某个token为什么出现在那里。你不能拆开它的引擎看零件,你只能从外部施加约束,观测输出,调整输入。
Harness Engineering的全部前提就是:接受这个事实,然后用工程手段去约束输出。
这也恰恰是控制论告诉我们的正确起点:对黑箱系统,放弃理解内部,转而经营输入-输出关系。
Ashby在1956年的《控制论导论》里说得很清楚:
当系统过于复杂或不可直接分析时,黑箱方法就是唯一合法的工程路径。
理解了这个前提,Harness Engineering的每一个组件都变得透明了。
System Prompt是方向盘,它定义了系统的期望行为边界。
Eval(自动化评估)是仪表盘,你看不见引擎/电机内部,但你能看见速度表和油温表/功率表,Eval测量的是输出与目标之间的偏差。
RAG和Context Window是控制带宽,你给模型喂什么信息,决定了你能在多大程度上约束它的输出空间。
Retry、Fallback、人工审批是纠偏执行器,当输出偏离预期时把它拉回来。
放一起看,就是个教科书般的负反馈控制回路,AI是黑盒没关系,给它套上这个马具,信马由缰的问题就得到了解决。
3
Only variety can absorb variety.(只有多样性才能吸收多样性。)
这是控制论里最牛的定律之一,也恰恰是对AI工程最有直接指导意义的一条。
什么意思呢?
一个系统能够产生N种可能的输出状态,那你的控制器必须能识别并应对至少N种情况。否则,必然存在你控制不了的失败模式。
映射到LLM场景就变得非常具体。大语言模型的输出空间几乎是无限的,它会编造事实、跑偏格式、误解意图、过度发挥、拒绝执行。你每忽略一种失败模式,就少了一道防线,AI就越容易气到你吐血。
很多人总是在纳闷,明明prompt写得很完善了,模型还是跑偏。这恰恰是控制多样性做得不到位的地方,一条prompt无法覆盖十种失败模式,墨菲定律在这里同样成立:当AI存在失败可能时,它肯定会失败。
所以从这个角度看,上下文工程的本质其实也是去精确匹配必要的控制带宽,反而跟大家下意识以为的给到足够信息量关系不大。
模型可能跑偏的每一个方向,你都需要一个对应的约束机制。
RAG约束事实幻觉,JSON Schema约束格式跑偏,Few-shot约束意图误解,Temperature/Token limit约束过度发挥,Fallback逻辑兜住拒绝执行。
4
继续用控制论的理论来看这个问题:Agent为什么越跑越蠢?
控制论对反馈有非常清晰的二分法:
负反馈:检测偏差→减小偏差→趋于稳定。恒温器就是典型的负反馈逻辑,温度高了就关掉加热,低了再打开。
正反馈:检测偏差→放大偏差→失控。麦克风啸叫就是正反馈逻辑:声音进麦克风→音箱放大→更大的声音进麦克风→持续放大直到刺耳。
Agent系统里最致命的问题,用控制论的术语来说就是:正反馈闭环导致的螺旋失控。
这个场景我相信每个人都见到过:
模型在第一轮输出就给了一个错误信息,这个错误信息被写入上下文(工作记忆),下一轮模型基于这个错误信息继续推理,产出更大的错误,错误继续积累进上下文,模型看起来越跑越蠢。
这就是控制论的正反馈逻辑,错误信号在系统内部自我放大,没有任何机制来衰减它。
修复方案同样是控制论给的:加入外部传感器(独立eval),打断正反馈回路。
具体说就是每一轮Agent执行后,必须有一个独立于模型本身的校验机制来判断这一步输出是否合理。不能让模型自己判断自己对不对,因为它已经在正反馈里了,它会用自己之前的错误来佐证当前的错误。
你无法叫醒一个装睡的人,更无法叫醒一个真以为自己睡着了的AI。
5
理论的东西虽然有意思,但讲起来还是太干了,最后给大家分享一些我自己实践下来觉得有用的工程规则吧,也是从控制论里演化的。
规则一:永远不要让模型自评。
让模型判断自己的输出质量,等于让已经进入正反馈的系统自己纠偏,做不到。Eval必须是模型之外的独立组件。可以是规则引擎,可以是另一个专门的评估模型,可以是人,但不能是产出答案的那个模型本身。
规则二:每种失败模式配一个约束手段。
列出你的模型可能出错的所有方式(幻觉、格式错、拒绝、过长、跑题……),然后确保每种失败模式都有至少一个对应的防御机制。如果你只有一条system prompt,那你的控制多样性就只有1。
规则三:微小偏差不值得re-prompt,设容忍阈值。
工业控制里,当偏差小于某个阈值时,控制器是不会动作的,因为频繁的微小修正反而可能引入噪声。如果模型输出95%满足要求但有一个措辞你不太满意,别改prompt,直接在后处理里调整。
规则四:Prompt修改单次不超过20%,必须做A/B。
每次prompt只改一个变量,对比改前改后的效果,确认偏差在收敛而非发散。不要因为一次负面case就把prompt推倒重来。
规则五:约束要分层,至少四层。
第一层是System Prompt(宪法层,定义不可逾越的边界);第二层是Context Window的信息布局(策略层,决定模型看见什么);第三层是Few-shot和Output Schema(执行层,精确约束格式和风格);第四层是后处理校验和人工审批(兜底层,兜住前三层漏掉的)。
规则六:看不见就控不了,structured output就是加传感器。
你没法控制一个你看不到状态的系统。Chain-of-thought、structured output、中间步骤的logging,这些都是在给你的黑箱加传感器。模型的推理过程对你越透明,你的控制精度就越高。
试一下吧,朋友们。