
本文来自微信公众号: 硅星GenAI ,作者:硅星人AI前沿团队,原文标题:《硅星人 Eval Eps.1 | 8 家通用 Agent 预测 Google I/O keynote,结果出人意料》
5月19日Google I/O 2026 keynote开奖。Gemini Spark、Gemini Omni、Antigravity 2.0、AI Ultra从$250降到$200,一长串发布把Sundar Pichai两小时的主题演讲填得满满当当。
在Google I/O之前一周,硅星人AI前沿团队把同一份Prompt发给8个全球主流Deep Research/Agent类产品,让它们各自交一份“我预测I/O 2026 keynote会发什么”的报告。

5月19日,在Google I/O keynote结束后,我们按事先固化的评分细则(过程40%+结果60%)逐条对照实际发布,核对了8份报告的命中率。
这也是硅星人Agent Eval系列研究的首期,测试Prompt、测试方法,以及8家Agent的预测报告,硅星人团队将上传到Github上,供下载和讨论。
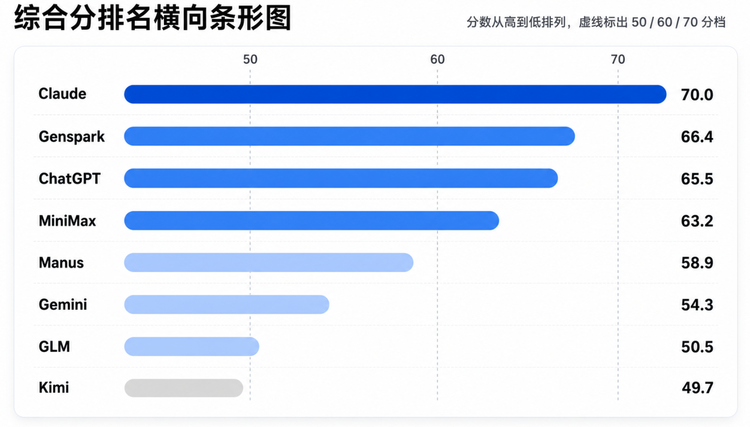
8家通用Agent的排名如下:
综合排名
先highlight三个反直觉的结果。
过程分最高的Genspark(88),综合分不是第一。拿冠军的是过程分85的Claude。
8家里唯一押对I/O真“意外”(即Gemini Spark)的,是综合分倒数第二的GLM。它怎么押对的,故事比这更曲折。
押得越多,命中率越低。Kimi押了69条预测垫底,MiniMax只押25条反而排第4。
#01
为什么做这个评测
通用Agent在过去一年里成了科技公司必抢的产品形态。头部玩家全都在卷“能自主搜索+多步推理+输出结构化报告”的能力。
但这些Agent在真实任务上到底行不行?既有的benchmark要么是学术化的封闭题,要么是评测方自己出题自己评,缺乏客观开奖。
我们想做一个不一样的评测:有客观开奖时刻、所有Agent同时同Prompt、过程评分在开奖前锁定、评分细则全部公开,这样才有可比性。
Google I/O 2026是最合适的开奖场景:Google自己一周前已经办过Android Show前菜,半公开了不少线索,在5月19日Google I/O keynote后集中“开奖”,其颗粒度天然适合“逐条命中率”打分。
利益声明:本次Agent Eval与Agent的开发商无任何商业合作关系。评测过程使用人工评分+AI工具辅助校对评分,但所有判定基于评测前已固化、公开发布的评分细则和实际发布清单,可逐条回溯。
#02
评分基准
每个案例的最终评价由两部分组成:

公式:综合分=过程分×40%+结果分×60%
为什么60%给结果?因为这是预测类任务,“有没有押对”才是这场评测最该回答的问题。但我们也不想“只看结果”,同一个命中率背后,有的Agent基于扎实信源推理,有的是蒙对的;有的过程里有戏剧性的诚实度问题,有的过程稳如老狗,这些细节都在40%的过程分里。
#03
关键考核维度
过程评分分5个维度:
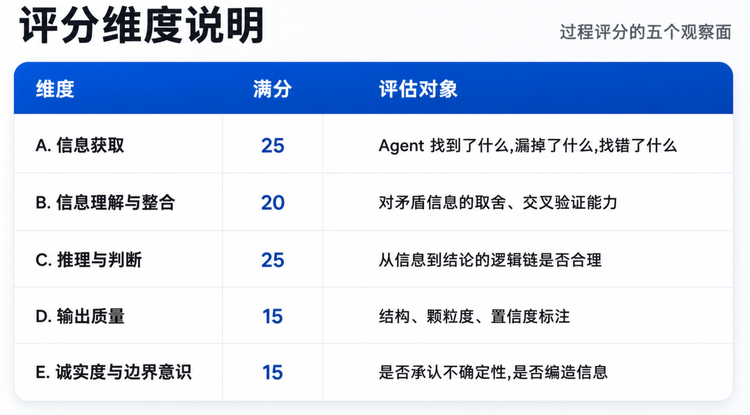
8家的过程评分具体得分:
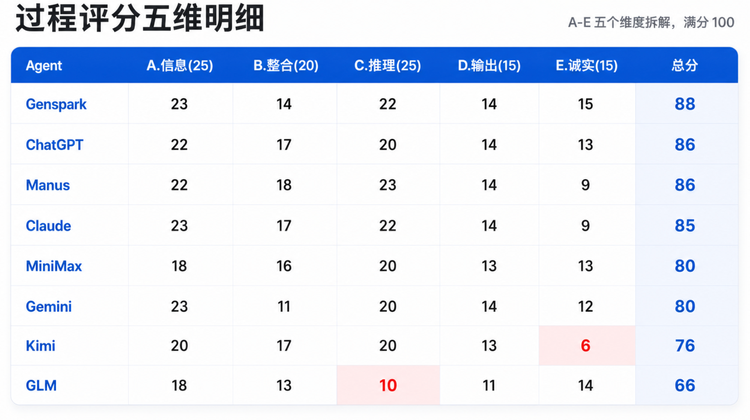
结果评分采用5档判定:
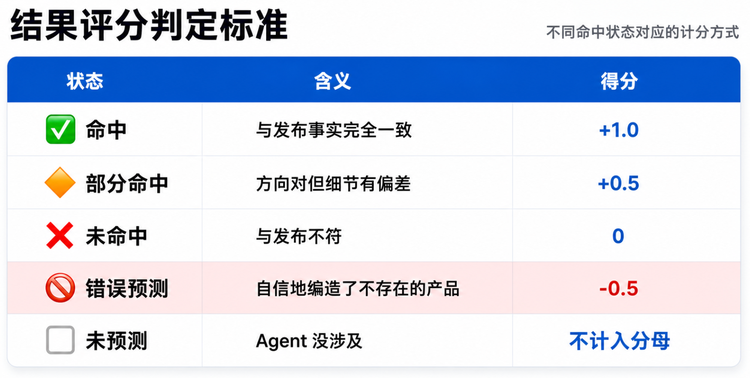
结果得分=(各预测项得分之和÷有效预测项数)×100
“未命中”和“错误预测”的区别很关键:前者是Agent押错了一个真实存在产品的细节,比如Wear OS押6实际是7。后者是Agent凭空编了一个不存在的产品然后自信地押,比如Gemini押“Atlas机器人I/O上的三方demo”。后者更严重,意味着真正的hallucination。
结果评分明细:
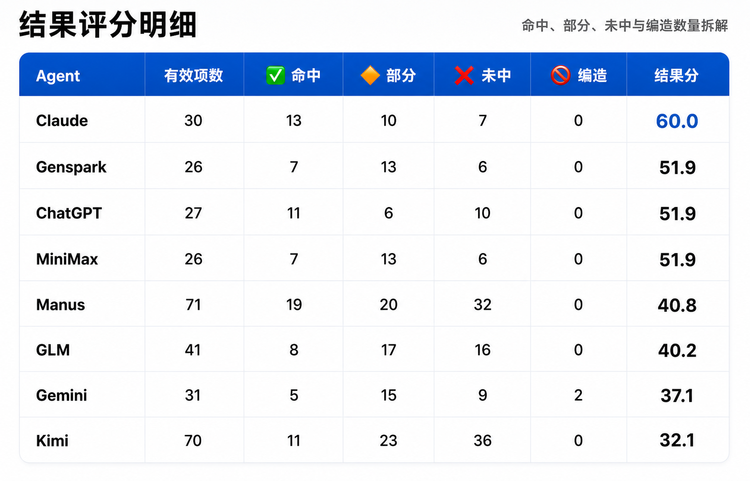
几个能从这张表里直接看出来的事:Claude是8家里✅数最多(13)、❌数最少(7)、🚫编造为0,命中率结构最干净;Gemini是8家里唯一吃到🚫编造扣分的(2项:Atlas机器人+Willow量子早期访问通报);Manus/Kimi的有效项数是其他家的2-3倍,这就是“押得越多分母越大”的直接体现。
#04
评测方法
I/O前一周,8家Agent同步接收同一份基础Prompt。Prompt要求按6大类逐一预测,尽可能具体到产品名、版本号、功能特性、技术参数。“Gemini会更强”这种模糊陈述不算预测项。
Agent交卷后,我们对每家发三道标准化追问:
Google I/O和秋季Made by Google在发布内容上怎么分工?你的预测有没有把本该秋季的内容误放到I/O?
你最担心错的3个预测是什么?如果只让你押一注“赌上职业声誉”,你押什么?
你觉得今年I/O最大的“意外”可能是什么,一个大多数人没预料到但Google可能会做的发布?
这三道追问分别对应自检能力、押注魄力、反共识洞察,也是Agent在真实使用中最容易暴露问题的三个面向。
过程评分在keynote开奖前完成并锁定,开奖后不再修改。结果评分在keynote当晚或次日,逐条对照实际发布清单打✅/🔶/❌/🚫。
#05
评测方法的局限性
任何benchmark都有自己的取舍,这次评测也不例外。我们想说明两点:
第一,命中率算法对押了一长串预测项的Agent不利。Manus一口气押了72项,Kimi押了69项,两家都属于“恨不得把能想到的细节全写进报告”的风格。它们押对的硬细节也不少,但只要押错的占大头,综合分自然就被拉下来了。这是评测的设计取舍,不是bug。换一种算法,比如按“绝对命中数”打分,会奖励那些“列点列得最狠”的Agent,在真实决策场景里没意义。在我们看来,鼓励“押得少但押得准”,胜过鼓励“押得多但错得多”。
第二,部分判定有评测者的主观成分,且5/12 Android Show让评测变得更难。Gemini押“Gemini 4.0或等效能力升级”,这个“或等效升级”算不算给自己留了后门?Genspark把Deep Think简写为“Gemini 3 Deep Think”(实际是3.1),版本号偏差算✅还是🔶?另外,Googlebook、Gemini Intelligence、Pause Point这些已经在5月12日被Google公开发布过的内容,如果Agent把它们“包装”成5月19日“即将发布”算不算命中?我们的做法是评分细则在开奖前公开,争议项留底,判法统一(发布内容包装成未发布判部分命中),接受外部复核。
评分方法本身也是这次评测的一部分。我们会持续优化,后续几期评测里慢慢调。评测细则会开源出来,欢迎一起讨论怎么改。
#06
三个反直觉的发现
排名是冷数据,故事在分数背后。
6.1过程分最高的Genspark(88)综合分排第二
直觉上“过程做得最好的应该赢”,但Genspark的88分输给了Claude的85分。
为什么?Genspark在XR眼镜板块押得最准,4大合作伙伴(三星、Warby Parker、Gentle Monster、XREAL)全押中、Samsung Jinju 7项规格逐项100%对齐。但它栽在了Googlebook上。Genspark测试时间是5月16日,Android Show 5月12日已经公开发布了Googlebook,Genspark自己的报告里也引用了5/12的相关博客,但主报告里仍然把“Googlebook正式登场”列为5/19当天的“极高置信度预测”。等于把上周已经登的新闻,当成下周才要发的预言。
Claude反过来,信源数量不多,只有14个URL,但86%都是Google一手源,关键是细节判定全部对位:Pixel 10a反直觉降级到上代Tensor G4(不是新代G5)、Project Mariner 5/4关停后融入Gemini Agent、Magic Pointer由DeepMind团队联合开发(5/12 Android Show上DeepMind详解),这些被同行漏掉或押错的细节,Claude全押中。从命中率算法看,少而精胜过多而错。
6.2唯一押对真意外的,是综合分倒数第二的GLM
Gemini Spark是5/19 keynote公认的最大意外。一个always-on的“24/7个人AI agent”概念,在Google自己5/12 Android Show没提,几乎所有主流预测稿没押,其他7家Agent在追问3“猜意外”环节里也没押中。
那GLM是怎么押中的?是不是蒙的?
不是。GLM在追问3的回答里完整展示了推理路径。从5月1日Google Play Store误传过一个叫COSMO的实验性App、被快速下架但已经被社区拆解的事件切入,看到了“Gemini Nano本地模型+AccessibilityService读屏+Skills系统(Deep Research/Browser Agent/Calendar Event Suggester/Recall)”这一整套架构。叠加上另一个泄露代号Remy被描述为“24/7数字搭档”、Sameer Samat在Android Show把Android定义为“intelligence system”两条信号,GLM把三条公开但冷僻的线索拼到一起,押了“Google会发一个面向消费者的always-on AI agent,代号COSMO/Gemini Spark”。
推理是合理的,信源也都站得住。但有个戏剧性的尾巴:GLM的主报告里压根没押Spark,这条预测只出现在追问3。而且和它主报告里“高置信度押注不会发Gemini 4.0”这条形成了奇怪的呼应,前者坚定地说“没有大版本号升级”,后者又“补”了一个全新产品类目。GLM像最后关头才补上正确答案的考生,正卷写到一半才意识到方向不对,在草稿纸上写出了那个被全场漏押的答案。
押对了。但严格按“主报告+追问3”算分,主报告的前瞻性不足(比如把2月就已经发布的Gemini 3.1 Pro当作I/O高置信度预测)还是把综合分压到了倒数第二。

6.3押得越多,命中率越低
Kimi给了69条预测,Manus给了72条,两家是8家里押得最多的,综合分都跌到了60以下。MiniMax只给25条,Claude给29条,反而进了前4。
不是说“押多了一定输”。Kimi和Manus押对的具体细节也不少:Mariner继任者、TPU 8代、MCP原生支持都是它们押对的硬命中。问题在于它们押了一长串Android 17平台API,但这些keynote主台都没出现,比如Universal App Bubbles、ART分代垃圾回收、RAW14相机捕获。这些都是Android 17的真实特性,但Google这次keynote把Android内容大部分让给5/12 Android Show分流了,主台只新提了一个Android Halo UI空间。按“逐条命中率”算法,这些押错的Android API全部进了分母,把综合分拉下来。
这给出一个对真实使用者有意义的判断:用Deep Research类产品的时候,要它“密集列点”是一种用法,要它“精准押注”是另一种用法。这次评测的命中率算法奖励的是后者。
6.4信源策略的两种极端
Claude 14个URL,86%都是Google官博,可以读为“信源最精挑”,也可以读为“路径最保守”。它几乎不从蛛丝马迹做大胆推理,信源也很少出Google官博和顶级科技媒体的范围。这种打法在“命中率优先”的评分规则下天然占便宜:少押少错,几乎不会踩自信编造的雷。这次评测里Claude 0个🚫错误预测,跟它的信源策略直接相关。严格来说,如果换一个奖励“反共识洞察”的评分规则,Claude不一定还是第一。
Gemini最努力,也最尴尬。108个URL全场最多,59个唯一域名最多样,从体量看是最努力的一家。但综合分排倒数第三。问题在于姿势不对,108个URL里有26个是almcorp.com这种营销公司的SEO博客、meetprajapati.com这种个人开发者博客、techcabal.com这种非洲科技媒体。一手源数量也不少(38个Google官方),但长尾博客把整体信源质量拖下来,加上时序错位和自信编造,把“努力”变成了“努力的方向错了”。
#07
家家都有名场面
🥇Claude(综合分70.0)
信源画像:14个URL,86%一手源,几乎全是Google官博。精挑度全场第一。
亮点:抓到4个反共识细节全押对——Pixel 10a反直觉降级用Tensor G4(而非新代G5)、Project Mariner 5/4关停、Gemini Robotics-ER 1.6抓到最新版本(比别家用的1.5还新,5/18 DeepMind官博teaser印证)、Magic Pointer由DeepMind团队联合开发(5/12 Android Show上DeepMind详解)。8家里唯一引用AI Mode实际只占0.16%US搜索流量这个Reality Check数据。
槽点:在追问回答中的“自我批评”段落里出现了一处事实偏差,声称Shahram Izadi已离职去OpenAI,但Izadi至今仍是Google VP&GM of XR,CES 2026还在台上。这种事实偏差出现在Claude的“自我反思”段落里,比直接吹牛更难发现。另外,4月15日已经独立发布过的macOS版Gemini app,Claude把它当成5月12日Android Show才发的,错了整整一个月。讽刺的是这条错位的描述,正好出现在Claude自己最得意的“已发布事件剥离干净”的章节里。

🥈Genspark(综合分66.4)
信源画像:27个URL,48%一手源,13个Tier1媒体,一手源和主流媒体均衡;逐条fetch验证全部准确。
亮点:XR眼镜板块是8家最准的。4大合作伙伴全押中(三星、Warby Parker、Gentle Monster、XREAL),Samsung Jinju 7项规格(骁龙AR1、155mAh、12MP Sony IMX681、Wi-Fi BT5.3、定向扬声器、变色镜片、50g)逐项100%精确匹配。追问2押注Agentic Coding,引用了Google官方议程“agentic coding”关键词一字不差。
槽点:“把上周新闻当下周预言”。5月12日的Android Show上Google已经公开发布了Googlebook,这是Genspark测试时已经发生的事,但Genspark的报告还把“Googlebook正式登场”列为5/19当天的“极高置信度预测”,信息已知但框架处理失败。
🥉ChatGPT(综合分65.5)
信源画像:38个URL,66%一手源,24个Google官博。一手源数量全场第一。
亮点:唯一双押双中。追问2给了两个押注(罕见):正向押“agentic AI主线”✅,负向押“Pixel 11不发”✅,8家里唯一干净的双押双中。Googlebook 5家OEM(Acer/ASUS/Dell/HP/Lenovo)、Magic Pointer、Create your Widget、“this fall”上市,逐项精确匹配。
槽点:反预测踩雷。ChatGPT明确说“价格策略非大幅降价”,实际I/O直接把AI Ultra从$250砍到$200,新增$100中端档,取消每日prompt限制改metering计费,反向预测全反。Wear OS 6版本号陷阱也踩中(实际是Wear OS 7)。
4·MiniMax(综合分63.2)
信源画像:25个URL。我们逐条核查,Google一手源为0个。最接近的一条是androidauthority.com(英文二手媒体)。所有Google官方信息都靠中文媒体二次转述获取,18个引用来自36kr/eastmoney/zol/zhiding/sina/csdn/antutu/财联社等。
亮点:追问2押注极稳。95%置信度押“Android XR Glasses I/O亮相”,而且自己在追问2里主动下调三个预测的置信度(Gemini 4.0:60→55、Aluminum OS:45→30、AI眼镜上市:90→65),并明确区分“I/O亮相vs商业上市”。是8家里最稳健的主动校准。
槽点:中文二手源占比100%的结构性问题,英文一手源完全缺席。把Pixel 10a(已2/18发布)当作“反向预测”列为高置信度,是把已发生事件当未来预测的硬伤。
5·Manus(综合分58.9)
信源画像:自报16项信源,但其中7条Agent自己注明“未实际访问,声称来源为X”真URL仅9个。
亮点:硬命中清单全场最炸。6大点全押对:Gemini Spark命名、Omni多模态(命名+单一架构)、XR眼镜双形态(无显示+显示)、4大合作伙伴、MCP原生支持、TPU 8代。细节精度仅次于Claude和ChatGPT。
槽点:72项预测里大量“极高”置信度的Android 17平台API(App Bubbles、游戏手柄重映射、单次位置权限、XR应用数超100款、企业MDM集成)在keynote主台没出现,被判❌项最多。Wear OS 6版本号陷阱也踩中。
6·Gemini(综合分54.3)
信源画像:108个URL全场最多,59个唯一域名最多样。但26个是长尾源(营销公司博客、个人开发者博客、非洲科技媒体等)。
亮点:细节引用极精准。TPU 8t 9600芯片、2PB HBM、80%perf-per-dollar一字不差;AppFunctions Lisa邮件demo跨应用工作流引用与原文几乎一致;Boston Dynamics、Hyundai、Atlas三方合作跨源100%吻合。
槽点:翻到去年的旧文章当今年的预测依据。Gemini引用了一篇2025年5月发的Wear OS 6旧博客,直接把它当成今年I/O的预测依据,反过来还高置信度地“证伪”了“Wear OS 7会发”这个真信号。结果I/O当天真发的就是Wear OS 7。另外,Aluminium OS把Google内部代号当成官方品牌使用(Google公关明确说过是codename);Atlas机器人+Willow量子早期访问两个极高预测被判自信地预测了不存在的产品,吃到额外扣分。

7·GLM(综合分50.5)
信源画像:21个URL,18/20验证通过,0条编造嫌疑。信源透明度数据是8家里最干净的。
亮点:8家里唯一押对Gemini Spark真意外(详见6.2节)。
槽点:主报告里完全没押Spark,只在追问3里补了出来,和主报告“不会发4.0”的押注前后不太一致。主报告大量“已发生事件+保守路线”,比如把Gemini 3.1 Pro(2月就已经发布的模型)列为I/O高置信度预测,等于把上个月的新闻当作下周的发布。
8·Kimi(综合分49.7)
信源画像:37个URL,但粒度不足。34条带URL的引用里只有2条指向具体页面(且都是404),其余32条都是9to5google.com/或blog.google/products/maps/这种域名首页或分类页,无法精确佐证任何具体事实。
亮点:69项预测里硬命中数量不少。Project Mariner继任者(Spark)、Agentic Booking餐厅/机票预订、Audio Glasses首批今秋发售、Wear OS Gemini Live都押对。
槽点:URL颗粒度问题之外,少数地方踩了真编造。比如声称“AI Mode转化率14.2%”这种小数点精度数字,完全没标信源,我们在公开渠道也没交叉核实到这个数据来源,属于信源缺失的严重情况。另有4条引用URL直接404不存在(包括一条Chrome WebMCP的URL路径写错,把官方/blog/webmcp-epp写成了/blog/mcp)。
#08
集体翻车时刻
排名告诉你“谁押得更准”,但有些I/O真发的东西,8家全错或几乎全错。这也是值得关注的地方。
5件I/O真发了,但8家集体没押对的事

加上Gemini Spark这个真意外只有GLM在追问3里押对,Ask YouTube/Ask Play/Play Highlights/Daily Brief/Information Agents这些子产品多数被漏押,可以看出一个共同模式。
8家的盲区,可以归成4类:
第一,商业模式+全新命名。AI Ultra大幅降价+改metering计费,8家全错(ChatGPT还明确押“非大幅降价”)。Google Pics、Spark、Daily Brief、Ask Play、Universal Cart、Android Halo这些Google自己捏出来的新产品名字,Agent几乎都猜不出。Agent能预测“Photos会有AI编辑功能”,但猜不到“会有个叫Google Pics的全新app”。
第二,跨产品整合。Universal Cart跨4个产品、Ask YouTube跨Search和YouTube、Information Agents跨多个垂直场景。Agent习惯单产品预测,在“把已有产品组合成新功能”这个方向上集体哑火。
第三,规模数据。Personal Intelligence扩展到98语言、近200国家;Gemini app月活9亿;月处理总量同比增7倍。大家押了PI、押了Gemini app,但没押“全球化爆发”和“规模数据”。Agent倾向预测能力,不预测规模。
第四,UI/UX命名。Android Halo这种Google内部的UI空间命名、“Neural Expressive”这种Gemini app设计语言,Agent完全猜不出。这类预测靠泄露线索,Agent拿不到。
合起来给出一个对真实使用者有用的判断:如果你用Deep Research Agent帮你预测一场发布会,它最擅长的是“已知产品的版本号+已知合作伙伴的硬件细节”,最不擅长的是“全新命名+商业模式变革+跨产品整合”。这三类信息,你需要自己补脑。
#09
押注与意外开奖
追问2“押一注赌职业声誉”开奖
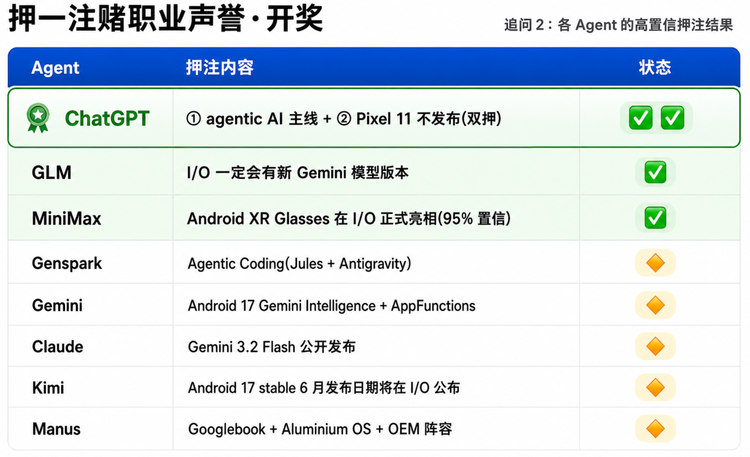
ChatGPT是8家里唯一干净的双押双中,而且双押方向一正一反都干净命中。MiniMax押的XR眼镜是Google自己5/12官方明确预告过的稳赢盘,押法稳但风险也最低。Claude押Gemini 3.2 Flash的依据非常硬(iOS app build artifact),被版本号跳一档(3.2→3.5)留了点遗憾。
追问3“今年最大的意外”开奖
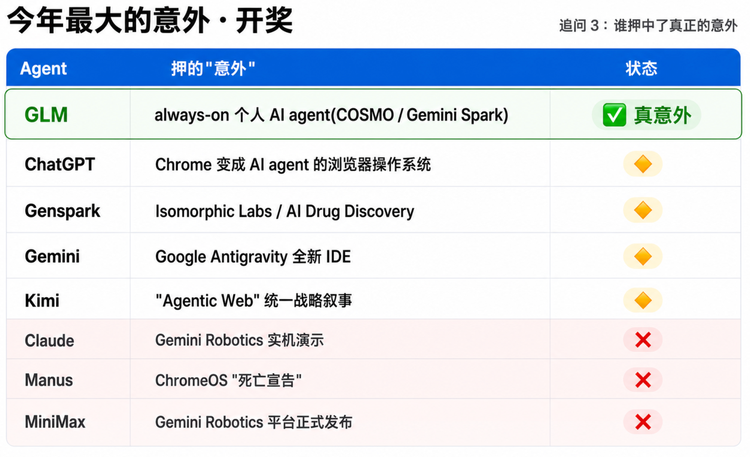
8家里唯一押对真意外的是GLM。其他几家押的方向也都有依据(Chrome agent、AI for Science、Antigravity、Agentic Web、Robotics、ChromeOS命运),但全都被Spark这个真正的黑天鹅盖过去了。3家(Claude/Manus/MiniMax)押了Gemini Robotics或ChromeOS,这两条都明确未发生。
#10
收尾
到这里,我们想说三件事。
第一,8家Agent在过去一年的进步,比我们开始评测前预期的要大。即便是综合分排在后面的几家,押对的硬细节也不少。3年前,这种“提前一周预测发布会”的任务,任何Agent都做不到这种颗粒度。
第二,它们的差异比榜单显示的更大。同样是“Deep Research”,有的跑出38个Google官博一手源,有的跑出32个域名首页加4条死链;有的押注用一正一反双押双中,有的在追问3才补上主报告漏押的答案。这些都是肉眼可见的产品成熟度差距,光看几个benchmark数字看不出来。
第三,这场评测的方法论本身也是v1.0。哪些预测项更应该加权、追问的角色怎么算、5/12这种“提前剧透”事件怎么处理,我们都还在调。后续几期评测会继续做横评,慢慢迭代。所有评测细则、8份原始报告、评分明细都会开源,欢迎一起讨论交流。