
本文来自微信公众号: 十字路口Crossing ,作者:Shirley Wu,原文标题:《英伟达科学家的20分钟演讲:机器人终局,2040 预言》
2026年这几个月,具身智能领域有一个清晰叙事正在成形。这场在红杉资本AI ascent活动上的20分钟演讲,目前是我们所看过的最清晰的行业全景图。
Jim Fan没有展示某款产品的性能曲线,而是用一条推理链把三件事串在了一起:过去十四年的历史脉络、当下模型与数据的整体格局,以及2040年的终局预测。
对任何试图理解具身智能全局走向的人来说,这是一份有时间坐标的思维框架。
嘉宾背景
范麟熙(Jim Fan)现任英伟达AI资深研究科学家,并共同领导通用具身智能体研究组(GEAR),被广泛视为具身智能领域的领军人物之一。
他曾亲历Jensen Huang将世界第一台DGX-1交付给OpenAI团队,如今他的工作是将英伟达的算力优势转化为机器人领域的系统性突破。
五个核心观点
1.Great Parallel:用LLM的剧本重写机器人
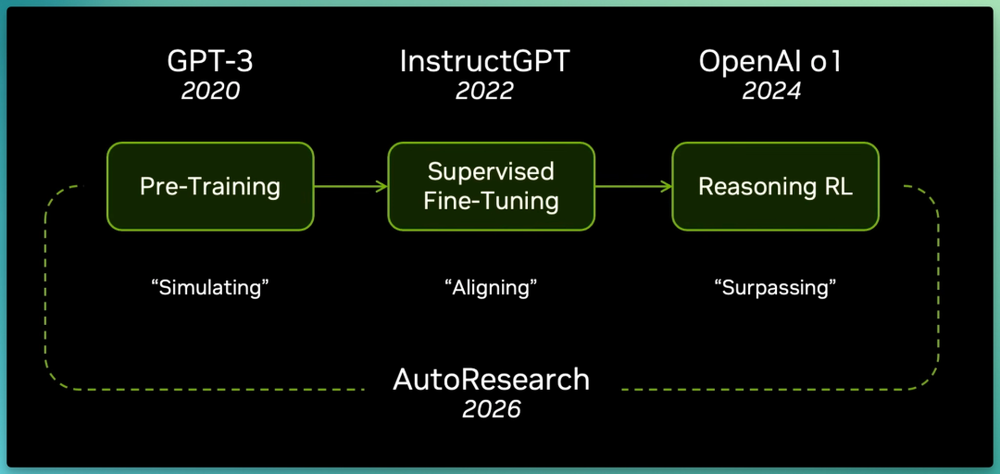
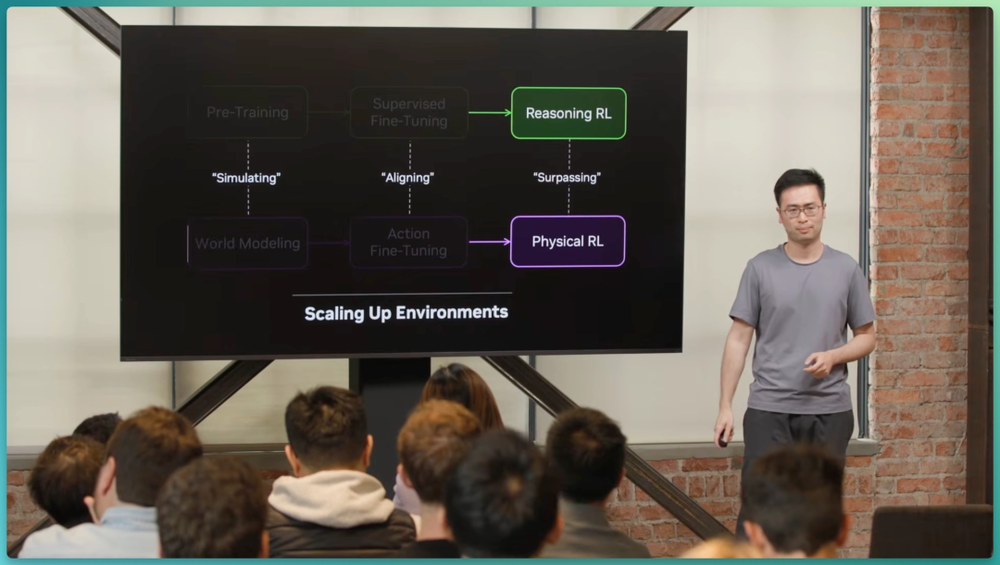
Jim Fan将LLM过去几年的成功路径概括为三步:大规模预训练→监督微调对齐→强化学习推理与自动研究。
他认为机器人正延续相同的路径,并将这套复制策略命名为"Great Parallel"(大平行):用世界模型预训练预测下一个物理世界状态,用动作微调对齐到真实机器人关心的仿真空间,用强化学习跑完最后一英里。
2.VLA时代终结,WAM是新范式
过去三年,主流的视觉语言动作模型(VLA)本质上是在视觉语言模型(VLM)顶部嫁接动作头,绝大多数参数在服务语言,视觉与动作排在最后,导致模型擅长名词却在物理规律和动词执行上严重不足,Jim Fan称之为"在错误的地方头重脚轻"。
真正的突破反而来自视频世界模型,即仅凭预测下一帧像素,模型自发涌现出对重力、浮力、光照的理解,无需任何手工编码的物理方程。
由此诞生新范式WAM(世界动作模型),英伟达提出的代表性WAM研究模型DreamZero联合解码下一个世界状态与下一步动作,实现了对训练中从未出现任务的零样本泛化。
3.Teleop将落幕,Sensorized Human Data是数据的未来
Teleop(遥操作数据采集)每台机器人每天有效产出约3小时,昂贵且侵入性强,难以支撑规模化扩展。
Jim Fan认为机器人数据采集需要走向类似特斯拉FSD的后台数据飞轮模式,以带手部追踪和密集语言标注的人类第一视角视频为核心,可扩展至千万小时,他称之为Sensorized Human Data(传感器化人类数据)。
英伟达EgoScale已验证用21,000小时野外第一视角数据预训练(零机器人数据),再用50小时高精度动作捕捉手套数据和4小时Teleop进行动作微调,即可实现22自由度机器人手的端到端控制。
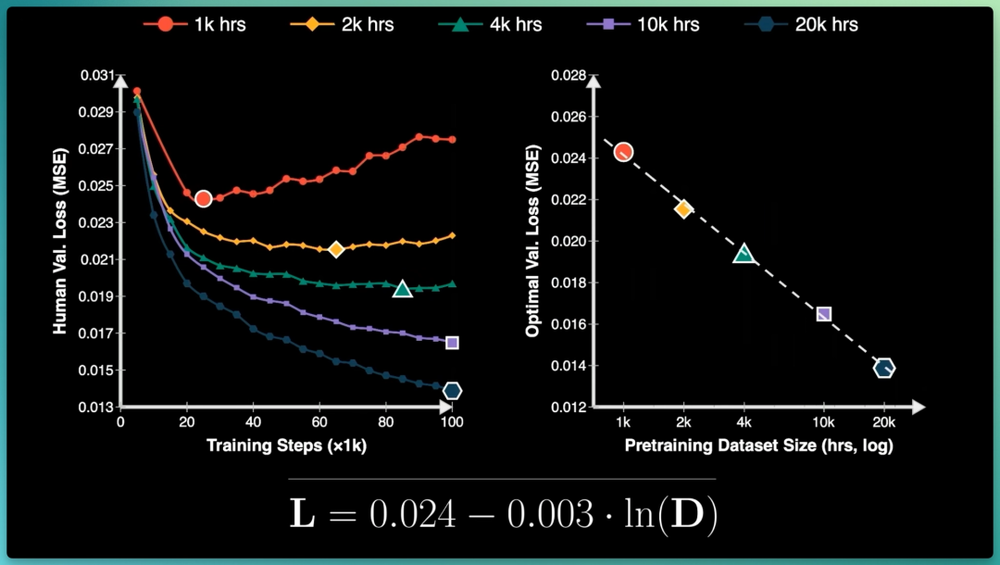
最关键的发现是,灵巧度也有缩放律,预训练数据量与验证损失呈清晰对数线性关系。
4.从Real-to-Sim-to-Real到Dream Dojo:算力即环境即数据
前沿LLM实验室用于强化学习的编程环境已达百万级,机器人需要同等规模的训练环境。
英伟达的解法分为两步:
第一步是Real-to-Sim-to-Real,用iPhone拍摄场景,3D扫描提取物体,在物理仿真器中重建并无限生成形态相近但属性随机化的变体(digital cousins),iPhone就此变成一台口袋世界扫描仪。
第二步是Dream Dojo,不依赖传统物理方程和图形引擎,转为纯数据驱动的神经模拟器:输入连续动作信号,实时输出下一帧RGB画面和传感器状态,画面像素由神经网络实时生成,机器人力学通过数据自动学习。
两步合在一起,形成一套战略方程式:算力=环境=数据。
5.三阶段终局预言:2040年,迎来终局
Jim Fan将机器人终局定义为三关:
物理图灵测试(按他的判断约2-3年内达到,即人类无法区分任务由机器人还是人类完成)。
Physical API(整个机器人机群可被API编排,实现类似"原子打印机"的无人工厂)
Physical Auto-Research(机器人自主设计下一代自己)。从2012年AlexNet到2026年AI Ascent用了14年,他有95%的把握将在2040年抵达这场终局的终点。
以下是完整逐字稿
一台DGX-1和一个开始相信深度学习的夏天
2016年的一个夏天,就在我们现在坐的这栋楼里,一个穿着闪亮皮夹克、肌肉发达的人扛着一块巨大的金属托盘走了进来。
托盘上刻着字:"献给Elon和OpenAI团队,为计算和人类的未来,我送上全球第一台DGX-1。"那是我第一次见到Jensen Huang。
和所有实习生一样,我赶紧排队在上面签下了自己的名字。能认出来吗?我的名字在这里。你还能认出另一个名字吗?Andrej也在这里。看来我们都快进计算机历史博物馆了,我感觉自己像个老古董。
那个时候,我完全不知道自己在参与什么。但没有人比Ilya本人更能描述接下来发生的事:"如果你相信深度学习,深度学习也会相信你。"
深度学习真的狠狠回馈了我们,远远超出任何人的预期。从2020年到2026年,只用了三步、六年,LLM走完了一段被后人称为"奔向终局"的旅程:
GPT-3的next-token prediction教会了模型语言的形态;InstructGPT的监督微调让这个仿真引擎对齐到有用的工作中;o1式推理用强化学习超越模仿学习,自动研究则进一步把整个循环加速到超越人类能力的边界。
就像Andrej说的,所有实验室都在逼近终极Boss。搞LLM的人正在经历他们人生中最精彩的派对,骑着一只叫做Mythos的“神话生物”疯狂跑通AGI。老实说,我非常嫉妒。
那么,机器人为什么不能分得一杯羹呢?
Great Parallel:机器人要走同一条路
作为一个有自尊心的科学家,我抄了作业,然后给它换了个名字,我叫它"Great Parallel"(大平行):
我们不再模拟字符串,而是模拟下一个物理世界状态;然后通过动作微调对齐到真实机器人关心的那一小片仿真空间;最后让强化学习跑完最后一英里。
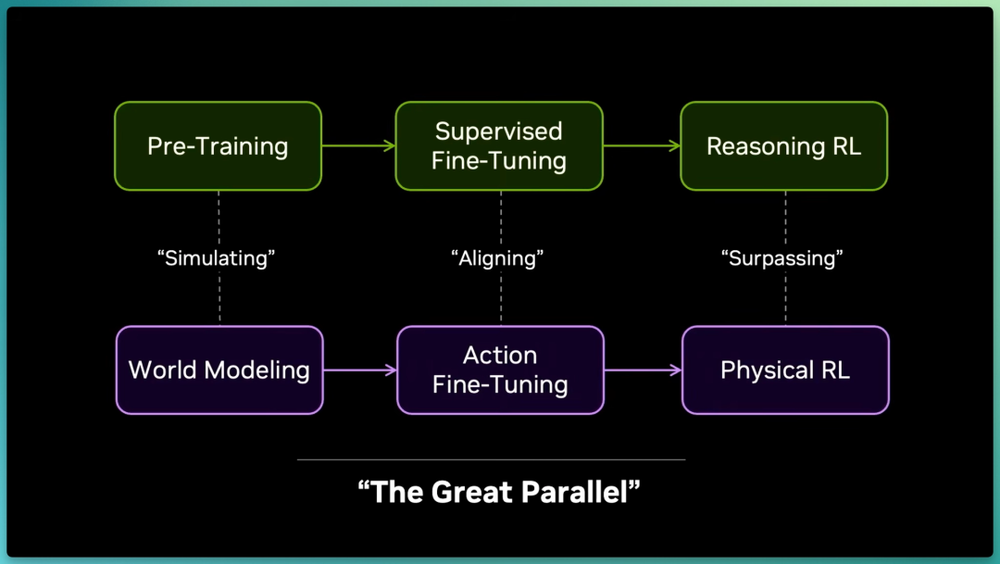
就这样,Great Parallel,复制LLM的成功路径,打不过他们,就加入他们。
终局如何打?归结为两件事:模型策略和数据策略,先看模型。
VLA的根本错误与视频世界模型的崛起
过去三年由VLA(视觉语言动作模型)主导,π0和GR00T都属于这一类。VLA的基本逻辑是:VLM的预训练已经做得足够强,直接在上面嫁接一个动作头(action head)就行了。
但仔细想想,这些模型其实应该叫LVA(Language-Vision-Action),因为绝大部分参数都分配给了语言处理,语言是第一优先级,其次才是视觉和动作。
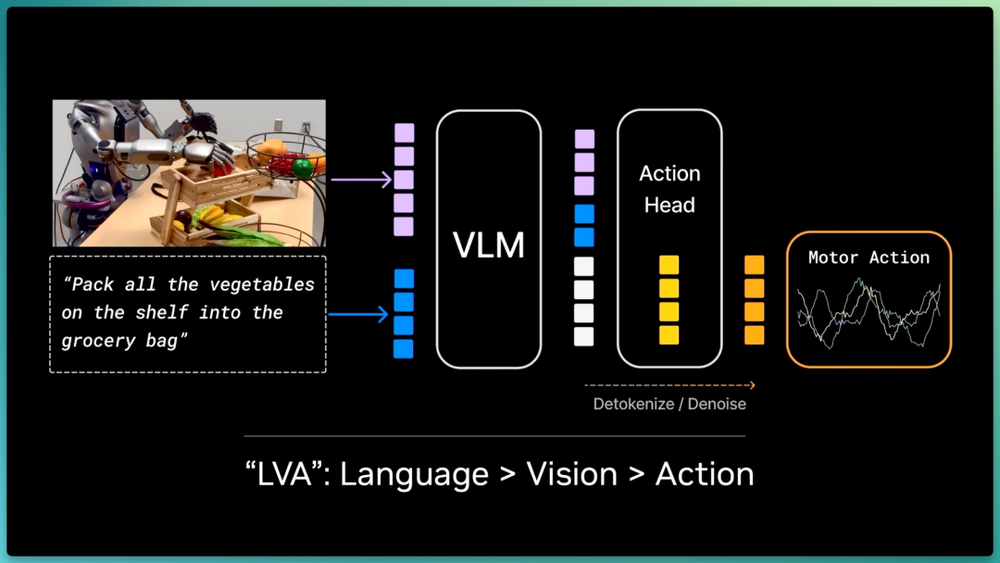
其结果就是VLA极其擅长编码知识和理解名词,但在物理规律和执行动词方面就差远了,可以说是在错误的地方头重脚轻。
比如说,把可乐罐移动到Taylor Swift的照片旁边,模型在机器人训练任务中此前没有见过Taylor Swift这个目标,却仍然完成了泛化,但这种泛化依赖的是语言概念的迁移,而不是真正的物理理解能力。
那么,第二种预训练范式是什么?拜托,我一直以为它会是某种宏大的东西。结果,它是我们口中的"AI视频垃圾"。比如安防摄像头里猫在弹班卓琴,我能看一整天,这大概就是互联网的巅峰吧。
但认真看,没有人能一开始认真对待这些,直到我们意识到,这些视频模型正在内部学习模拟下一个世界状态。
这是Veo 3生成的一些画面。你可以看到,模型自己捕捉到了重力、浮力、光照、反射、折射,没有预编码进去,物理规律是通过大规模预测下一个像素块而自发涌现的。
甚至视觉规划也随之涌现。注意看Veo 3是怎么解迷宫的,它通过在像素空间里向前推演模拟来求解,特别注意右下角那个例子,不要眨眼。它真的非常聪明,Veo 3发现如果你不看,几何形状是可选的,我把这称之为物理垃圾(Physics Slop)。

DreamZero:WAM范式的代表性研究模型
那么,如何让这些世界模型变得有用?我们做动作微调,对所有可能未来状态的叠加态进行对齐,然后把它压缩到一个薄薄的切片上,也就是真实机器人真正需要的部分。
DreamZero,这是一种能对未来几秒进行模拟、并据此采取行动的新型策略模型。
要知道,电机动作信号是高维连续信号,数值形式上看起来就像像素,我们可以在渲染视频的同时渲染它。因此,DreamZero能够联合解码下一个世界状态和下一步动作,最终它能零样本解决训练中从未出现过的任务和动词类别。
当机器人在执行任务时,我们可以可视化它在"梦到"的内容,并且这种相关性非常紧密:
如果视频预测成功,动作也就有效;如果视频产生幻觉,动作就会失败。
于是,视觉和动作重新成为了一等公民。
我们用DreamZero玩了很多花样,比如推着机器人在实验室里到处跑,然后输入随机prompt。当然DreamZero无法百分百稳健地完成所有任务,但它就像GPT-2,试图在每个案例中捕捉运动的正确形态。
因此,DreamZero是我们迈向机器人领域开放词汇提示的第一步。我们把这种新型模型叫做世界动作模型(World Action Models,WAM)。
让我们为老朋友VLA默哀片刻,你很好地服务过我们,安息吧,WAM万岁!
数据战争:从Teleop到Sensorized Human Data
模型策略讲完,接下来看数据策略。
这是英伟达首席科学家Bill Dally在我们实验室进行遥操作。考虑到他的薪水,这条遥操作轨迹可能是我们数据集里迄今为止最贵的一条。
过去三年一直是遥操作的黄金时代,VR头显、超低延迟的串流系统,以及形如中世纪刑具的复杂装置,行业投入巨大,过程也十分痛苦。
然而,Teleop的物理上限是每台机器人每天24小时,说实话更像是每天3小时,还得看机器人心情好不好,因为它们经常"发脾气"。
那我们该如何做才更好呢?答案是:直接把机械手戴在自己手上。
这叫UMI(通用操控接口),看似平淡,实则深刻。把机器人执行器戴在手上,直接由人来采集数据,同时将机器人身体其余部位排除在操作循环之外。
UMI可能是机器人数据领域有史以来最伟大的论文之一,它直接催生了两家独角兽公司——左边是Generalist(改进了夹爪设计),右边是Sunday(制作了三指数据手套)。
去年,我们在此基础上更进一步,设计了能与五指灵巧机械手形成1:1映射的外骨骼DexUMI。

让我们看看它的实际运作:画面最左侧是人直接采集数据,速度最快;最右侧是传统遥操作,即便是最熟练的博士生也需要非常仔细地对齐,速度很慢,成功率也低;中间是直接穿戴外骨骼采集。
接着我们用这套数据训练了机器人策略,这里你看到的,是一个用零遥操作数据训练出来的策略在完全自主运行。我们打破了每台机器人每天24小时数据采集上限,看看这些机器人有多高兴,它们再也不用被绑在数据采集循环里了。
那么,问题解决了吗?机器人的规模化已经被搞定了吗?
在座有没有人开特斯拉或Waymo的?你们知道吗,当你开车时,你实际上正在为最大的物理数据飞轮做贡献。而且你完全感知不到,在全自动驾驶(FSD)期间,数据上传是一个后台运行的过程。
然而,穿戴UMI依然很麻烦、很有侵入感,不像开车上班那样无缝自然。我们需要一个类似FSD的等价物,数据采集必须退居幕后。
所以,我们全面押注带有手部位置追踪和密集语言标注的人类第一视角视频。
EgoScale:零机器人数据的灵巧度预训练
EgoScale就是这条押注的第一个落地成果。
我们用21,000小时的野外第一视角人类数据预训练EgoScale,其中99.9%的训练数据基于人类第一视角视频,从摄像头像素直接映射到22自由度的高灵巧机器人手,最终形成端到端策略,全程完全自主。
在预训练阶段,我们预测手部关节和腕部姿态;随后的动作微调阶段,我们只收集了50小时高精度动作捕捉手套数据,加上4小时遥操作(不到训练总量的0.1%)。
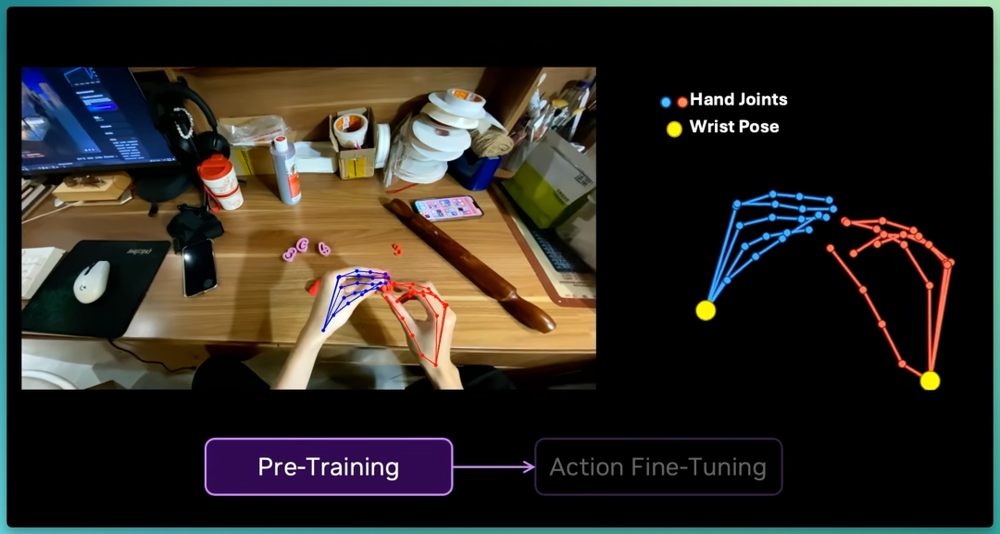

凭借这一点,EgoScale能泛化到非常精细的任务中去,如拣选扑克牌、操作注射器转移液体,以及在测试时只需一次示范就能学会不同的衬衫折叠方式。


论文中最有意思的发现是关于灵巧操作的神经缩放律,我们在预训练中投入的小时数与最优验证损失之间存在着非常清晰的关系,实际上就是一个简洁的对数线性数学方程。
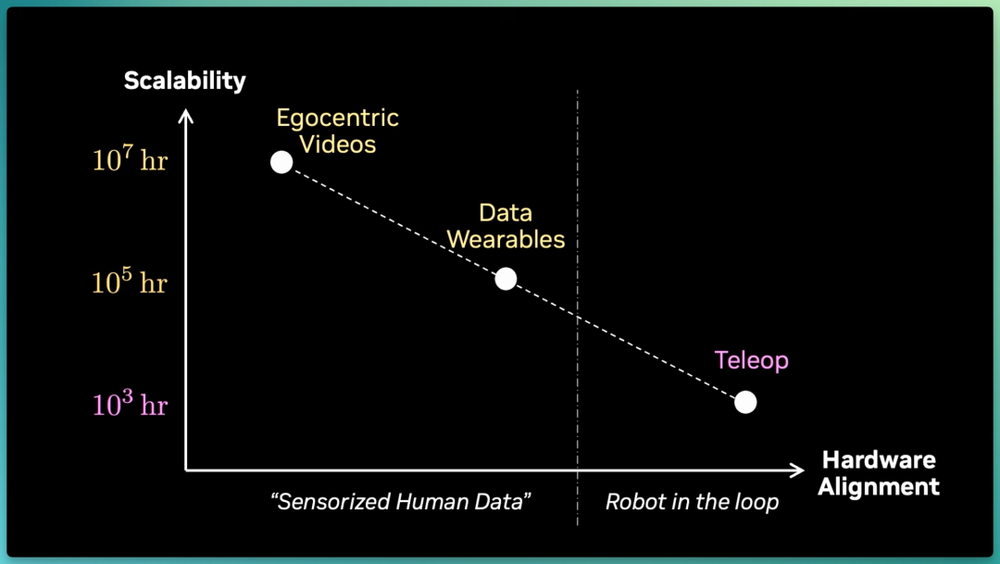
距离最初针对语言模型的神经缩放律提出已整整过去了六年,如果我们把所有数据策略放到一张图上,横轴X轴是与机器人硬件的对齐程度,纵轴Y轴是可扩展性,可以看出:
遥操作的可扩展性最差,可穿戴的数据采集设备可达到数十万小时,而第一视角视频如果能转动FSD飞轮,未来一年内轻松达到1,000万小时。
图中虚线的左边都属于新范式,即Sensorized Human Data(传感器化的人类数据)。
如果让我来做个预测:
未来一两年内,遥操作比例会不断下降,降至几乎可以忽略不计的水平;随后会出现一批为不同硬件和使用场景定制的数据穿戴设备;最终,机器人训练的主要数据源,将是第一视角视频。
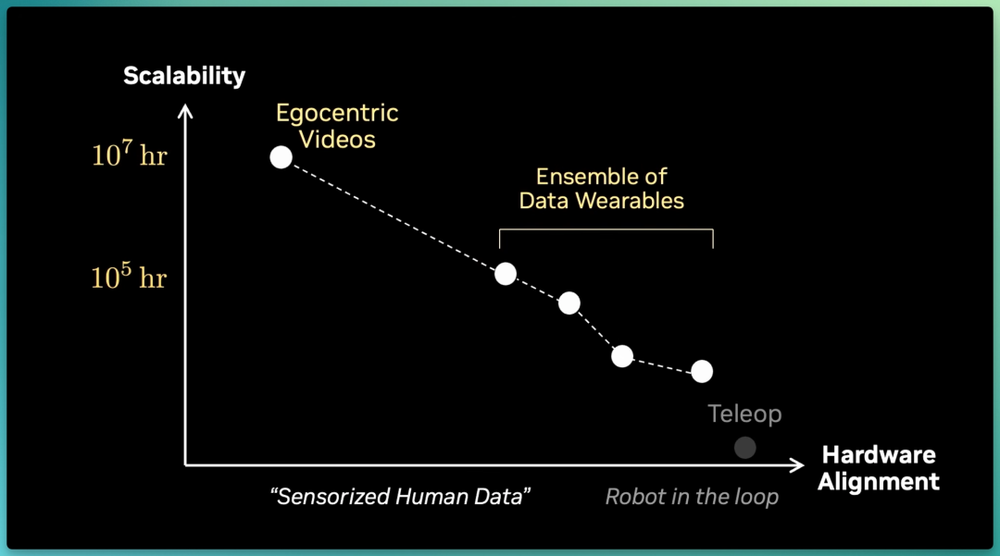
让我们为老朋友Teleop默哀吧,你服务了我们,但Sensorized Human Data万岁!
仿真环境的军备竞赛:从iPhone到Dream Dojo
数据策略讲完了吗?注意我在数据策略上画了两个圈,那么外圈是什么?
所有前沿LLM实验室现在都在花大预算购置数以百万计的编码环境来做强化学习,机器人领域同样如此,我们迫切需要扩大训练环境的规模。
当然,你可以直接在真实机器人上做强化学习,我们实验室用RL把某些任务的成功率推到接近100%,机器人可以连续执行数小时。但要达到100万个环境规模,按照之前的方式就需要100万台机器人,我们需要更好的解法。
这里,你用iPhone拍一张照片,通过3D世界扫描流程来提取所有物体,然后在经典物理仿真器中自动重构它们,因此,所有对象在扫描后都是可交互的。接着,再用我们称为digital cousins的变体,在仿真中对这些对象进行无限扩增,iPhone因此变成了一台可装进口袋里的世界扫描仪。
我们把这个过程叫做Real-to-Sim-to-Real,即以可扩展的方式将物理世界数字化重建。

但这个方法仍然依赖于传统的图形引擎,我们能不能做得更好?答案是Dream Dojo。
Dream Dojo将视频世界模型升级为完整的神经模拟器,通过接收连续动作信号,实时输出下一帧的RGB画面和传感器状态。
你在这里看到的每一个像素都不是真实的,Dream Dojo通过纯数据驱动的方式,捕捉并学习不同机器人的运动机制,整个过程没有涉及任何物理方程或图形引擎。
因此,机器人领域新的后训练范式是一套大规模并行的强化学习系统,它运行在少数真实机器人工作站之上,同时由大量GPU图形核心负责世界扫描,并由高强度推理计算运行世界模型。
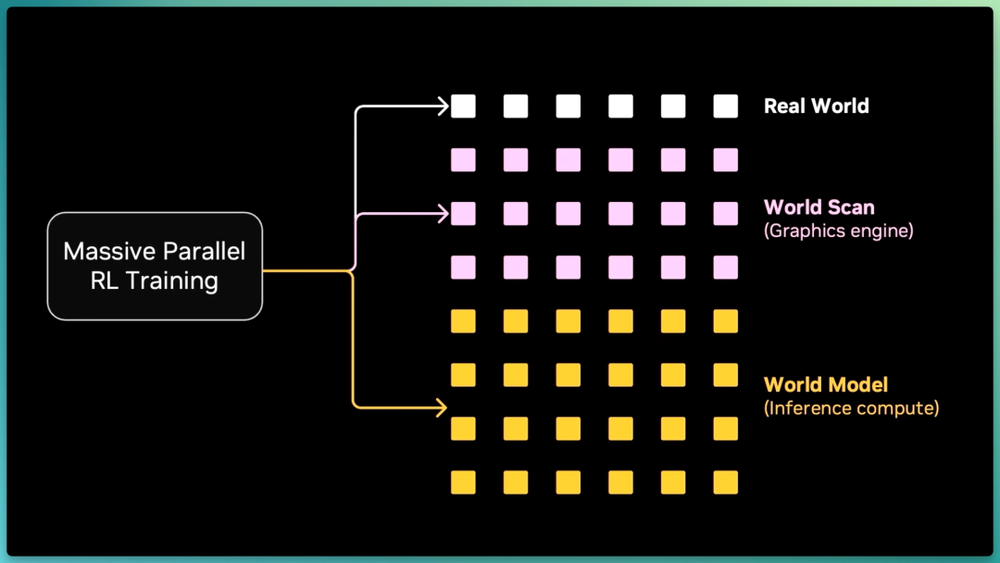
正如这个等式所示:
算力=环境=数据
整合在一起,就是机器人将走的Great Parallel。而这正在发生,我们正在目睹终局的开端。
终局的三重门
大家玩过《文明》这款游戏吗?还是我最喜欢的游戏,我把我的研究想象成在文明科技树上解锁成就。
在机器人领域,还有三项成就等待解锁,解锁完成我就退休,老实说我有点等不及了。
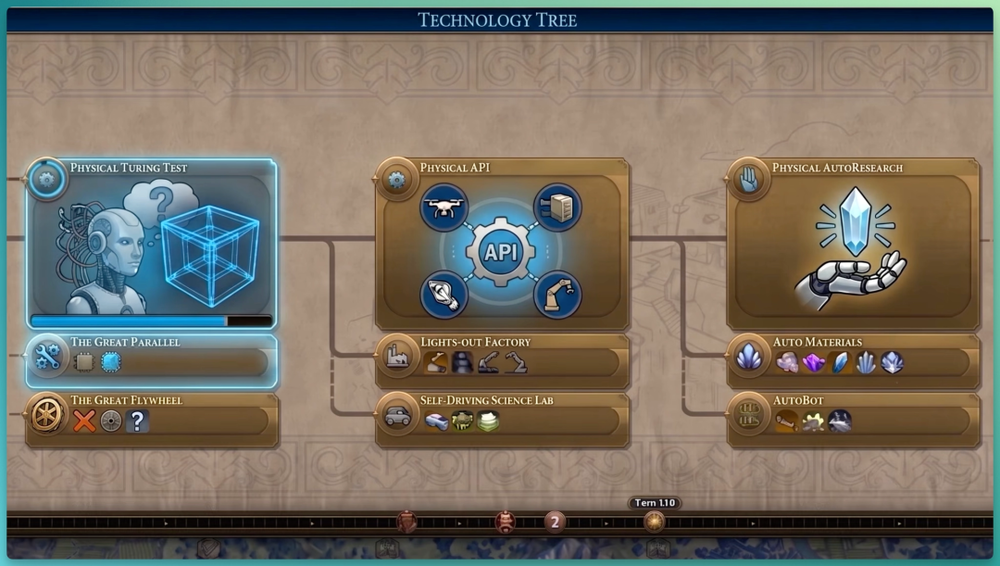
第一关:物理图灵测试
在广泛的日常活动中,你无法区分是人类还是机器人在执行任务。物理图灵测试衡量的是单位能量输入对应的单位劳动产出。看看这台机器人销魂的姿势,我们还有很多工作要做,大概还需要2-3年。
第二关:物理API
你拥有一整个机器人机群,它们可以像任何软件一样用API和命令行进行配置,将来由某个版本的Opus 9.0来统筹编排。
有了物理API,我们就能实现熄灯工厂/无人工厂,这些本质上就是“原子打印机”,它们以Markdown文件中的设计为输入,输出完全组装好的产品,整个过程完全自主运行;或者实现能自动化化学、生物和医学领域科学发现的湿实验室。


第三关:物理自动研究

当机器人开始自主设计、改进并构建下一代自己时,将远超人类能力的边界。你可能会问:这是不是太科幻了?我们有生之年能看到吗?
AI社区从2012年AlexNet的第一个前向传播(一个勉强能区分猫和狗的模型)到2026年的AI Ascent(我们已在探讨智能体自动研究),用了整整14年。现在再加14年怎么样?

2026年恰好在2012和2040的正中间,而技术的发展并非线性推进的,而是指数级增长。所以
我有95%的把握,我们将在2040年到达这场终局的终点,文明科技树的末端。
如果你笃信机器人学,机器人学亦将回馈于你。
致在座的各位,我想我们这一代人,生不逢时,既错过了探索地球的黄金时代,又未能赶上遨游星辰的浩瀚征途,但我们又生逢其时,恰好处在解决机器人技术的这个时刻。