
本文来自微信公众号: 观网财经 ,作者:陈济深
5月27日,雷军在微博转发了小米MiMo-V2.5系列API降价的消息。
按照小米MiMo官方公告,MiMo-V2.5系列API从当天零时起永久降价,最高降幅达99%,同时不再按照上下文窗口长度分档计价。Token Plan计费体系也同步调整,同等价格下用量提升至原来的5至8倍,仍在有效期内的用户额度被统一重置。
雷军在转发中强调,这次价格调整"最高降幅达到99%,不再区分上下文窗口"。
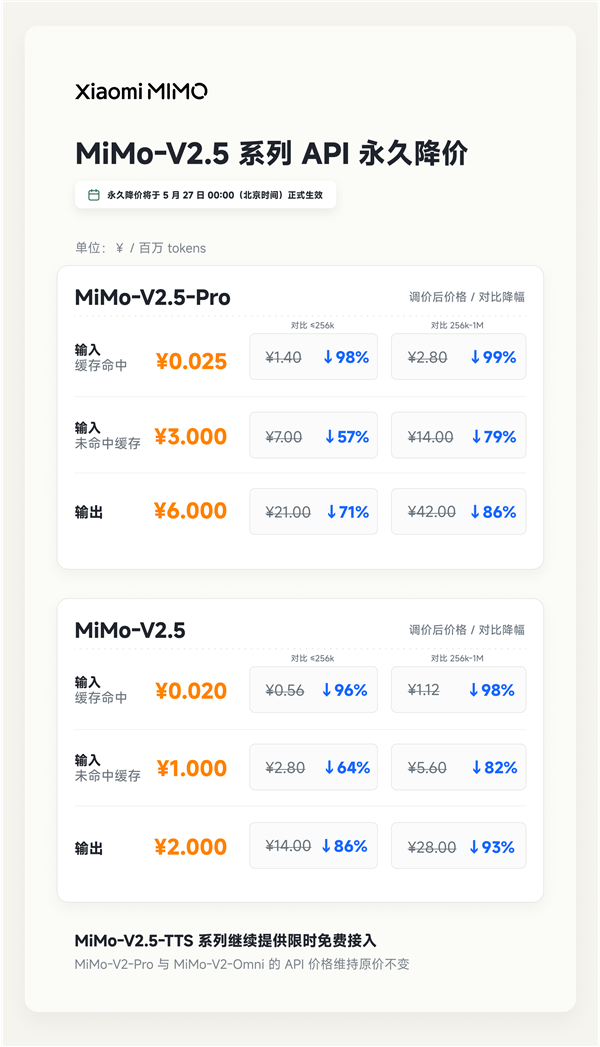
99%的降幅当然足够醒目。但更值得注意的是,MiMo-V2.5-Pro调价后的三项核心价格:输入缓存命中0.025元/百万tokens,输入缓存未命中3元/百万tokens,输出6元/百万tokens。
这三个数字,与五天前DeepSeek刚刚确定为长期价格的V4-Pro完全一致。
DeepSeek V4系列于4月25日上线,V4-Pro首发定价为输入缓存命中1元/百万tokens。上线次日,DeepSeek即宣布全系API输入缓存命中价格降至首发价的十分之一,V4-Pro同时叠加2.5折限时优惠,优惠后缓存命中价格降至0.025元/百万tokens。这一优惠原定于5月5日结束,后延至5月31日。5月22日晚间,DeepSeek宣布2.5折优惠不再限时,永久生效。一个月内连续调价,也让DeepSeek V4-Pro的"原价"更像是一个短暂存在过的参照物。
DeepSeek官方价格页显示,V4-Pro在5月31日优惠活动结束后,将正式调整为原定价的1/4。调价后,V4-Pro输入缓存命中价格为0.025元/百万tokens,输入缓存未命中为3元/百万tokens,输出为6元/百万tokens。
也就是说,小米MiMo此次并不是简单降价,而是将其Pro档模型价格,直接对齐到了DeepSeek刚刚打出的价格基准上。
这使得此次降价超出了常规促销的范畴。
值得注意的是,小米此次降价也发生在MiMo上一轮开发者激励结束之后。官方公告显示,自4月28日启动的100T Token创作者激励计划,已于5月26日提前发放完毕。对MiMo而言,永久降价和Token Plan额度重置,不只是降低开发者尝鲜门槛,也是在免费Token红利结束后,继续承接Agent框架和应用开发者生态。
过去大模型API更接近"能力溢价"定价。模型越接近闭源前沿模型,越能在代码、推理、长上下文、Agent等场景中证明能力,厂商就越有理由维持更高价格。
但DeepSeek和小米MiMo这两次降价,显示出另一套定价逻辑正在浮出水面:模型服务不再只按"能力有多强"定价,也开始受到"单次推理成本能压到多低"的约束。
这背后是推理系统效率的持续优化。小米MiMo在公告中解释称,技术团队基于SGLang HiCache完整支持SWA,将KV Cache在GPU显存、CPU内存、SSD等多级存储之间的数据搬运量降至优化前的近七分之一,可缓存token数量提升至近5倍,并通过专家并行、输入长度分桶等方式提升集群吞吐。
也正是这些看似后台的工程优化,决定了厂商是否有能力长期维持低价。大模型API价格战已经不只是模型参数和榜单能力的竞争,而是延伸到推理框架、缓存系统和集群资源调度能力的竞争。能否在高并发、长上下文和多轮调用下持续压低单token服务成本,正在成为厂商基础设施能力的一部分。
尤其是缓存命中价。
0.025元/百万tokens并不是所有输入的价格,而是请求前缀命中Prompt Cache之后的价格。但对于代码助手、企业知识库、客服系统、文档审核和Agent工作流而言,大量调用都包含重复上下文:系统提示词、工具说明、历史轨迹、检索片段、代码仓库背景,会在多轮任务中反复出现。
过去,长上下文和多步Agent之所以难以大规模部署,一个重要原因就是持续调用成本过高。当缓存命中价格被压到0.025元/百万tokens,真正被重估的不是一次问答,而是复杂任务连续运行的成本。
这也是小米取消上下文长度分档的意义所在。
此前,MiMo-V2系列按照256K以内和256K至1M上下文窗口分档计价,长窗口输入成本明显更高。此次V2.5系列降价后,MiMo不再区分上下文窗口长度,相当于直接降低了长上下文任务的使用门槛。
对开发者来说,这比单纯"便宜一点"更关键。Agent、代码助手和企业知识库真正消耗成本的地方,恰恰不是短问短答,而是长上下文、连续调用和多轮任务。
放到全球价格体系中,这一差异更加明显。OpenAI此前披露,GPT-5.5 Pro API定价为输入30美元/百万tokens、输出180美元/百万tokens。相比之下,DeepSeek V4-Pro和MiMo-V2.5-Pro调价后,即便不计算0.025元的缓存命中价,仅以缓存未命中输入3元、输出6元计算,价格也已经低出不止一个数量级。
这意味着,国产模型的低价不再只是"平替"叙事,而是开始对全球大模型API的价格体系形成压力。
这种压力最终会传导到企业采购方式。
未来企业不会只问"哪个模型最强",而会更关注"什么任务该用什么模型"。高风险的法律、金融、关键代码审查和重大经营决策,仍可能交给更贵、更稳、更有合规保障的模型;但客服初筛、批量摘要、内部知识库问答、代码初稿、文档整理等高频、重复、低风险任务,则会更多被路由到低价模型。
换句话说,企业买的可能不再是单个模型,而是一套路由系统。
这种趋势已经在海外企业实践中出现。Airbnb CEO Brian Chesky此前表示,其客服AI由13个模型组成,并在很大程度上依赖通义千问,原因是"更好更便宜"。当企业开始把不同模型放进同一套生产系统,模型竞争就不再只是榜单分数竞争,而是单位任务成本、稳定性、吞吐、延迟和合规能力的综合竞争。
当然,低价并不等于真实总成本一定低。
0.025元只对应缓存命中输入。实际部署中,企业还要看缓存命中率、首token延迟、并发限制、服务稳定性、长上下文吞吐、第三方平台加价以及数据合规成本。如果业务场景高度动态、上下文频繁变化,或者服务在高峰期无法稳定承载,价格表上的低价未必能完全转化为生产环境里的低成本。
因此,这轮价格战的关键不只是"谁更便宜",而是大模型厂商能否在低价下保持可用、稳定和可规模化。
更具意味的是,据彭博社等媒体报道,DeepSeek近期正推进约700亿元人民币融资,潜在投前估值约450亿美元,梁文锋向投资者强调的仍是开源模型和AGI目标,而非短期商业化。如果这一融资进展最终落地,V4-Pro永久降价也更像是一种长期生态策略,而不是阶段性促销。
DeepSeek先把限时优惠变成长期价格,小米MiMo随后将Pro档价格直接对齐。两家公司共同释放出的信号是:国产大模型API正在从能力溢价阶段,进入成本约束阶段。
后续压力将传导给更多模型厂商。
如果同等能力区间的模型已经可以把缓存命中输入压到0.025元/百万tokens,那么价格更高的模型就必须回答一个更直接的问题:它贵出来的部分,究竟来自更强能力、更高稳定性、更好合规,还是仅仅来自过去的定价惯性?
从更大的产业格局看,这也是中国大模型路线的一个典型切面:不只追求单点最强模型,而是通过低成本、高频迭代和开放调用,把模型能力尽快压进真实应用场景。
当海外前沿模型仍维持高价策略时,中国厂商正在把大模型推理服务做成更接近基础设施的东西。价格战只是表象,真正竞争的是谁能用更低成本支撑更大规模的应用生态。
大模型价格战没有结束。它只是从"谁敢降价",进入了"谁能用真实成本支撑低价"的新阶段。