
本文来自微信公众号: 碳基智 ,作者:碳基智
上周写了篇笔记《Skill的本质不就是提示词?吹什么》,聊了下我对Skill的理解,在跟评论区朋友讨论的过程中,我进一步提出了自己的一个想法:
Skill是模型厂商的阳谋,本来Skill背后所隐含的这些业务背景、领域知识等高质量语料模型是拿不到的,结果因为要做成Skill提升模型输出能力为自己提效,用户主动地贡献了这些作为模型后续训练的素材。
所以今天这篇笔记,接着深入去探讨一下,这个论断背后我的理解。
1
先说下大部分用户对Skill理解不到位的地方,核心其实就是一句话:
Skill=用户侧的效率工具+平台侧的数据采集器
这两个身份是并行存在的,但很多人其实只关注到了前面半句,而忽视了后面这半句。
先来画一张映射图,帮助大家全方位理解Skill系统为何是平台阳谋:
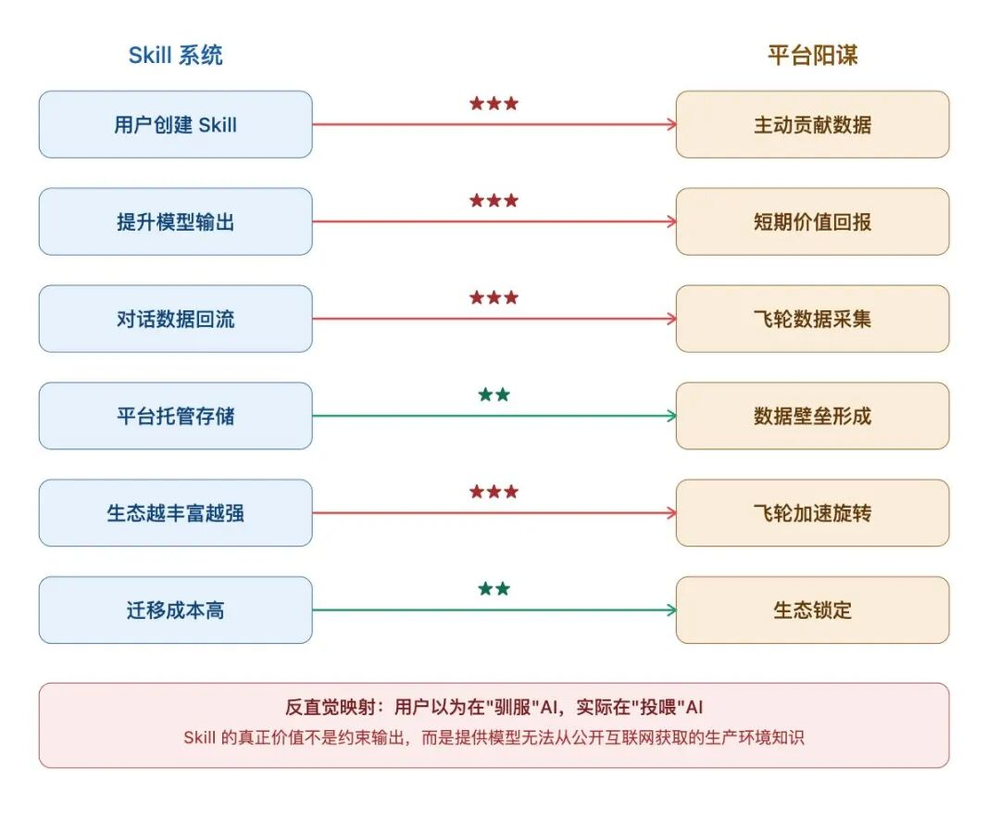
一个Skill系统,一般来说包含以下6个核心要素:
结构化提示词:用自然语言编写的指令模板,约束模型输出格式与风格。
领域知识注入:用户将行业know-how、SOP、判断标准写入Skill。
工作流编排:定义多步骤执行链路,让模型按特定顺序完成复杂任务。
触发机制:用户通过特定指令/场景激活Skill。
平台托管:Skill在平台服务器上存储、运行、被调用。
生态分发:通过Skill Store/Marketplace实现跨用户流通。
这些背后其实都可以对应到模型厂商的数据飞轮,也是模型越来越强的原因之一。
2
Skill把人类的核心工作流「翻译」成模型可执行的格式
很多人理解的Skill就是高级提示词,本质上虽然没什么毛病,但其实是对Skill的低估。
提示词解决的是一次对话怎么问,Skill解决的是一类工作怎么长期复用。它让用户把原本只存在于脑子里的工作方法主动写出来:什么时候启动、先做哪一步、参考哪些材料、输出什么格式、什么东西不能碰、遇到模糊输入怎么处理。
这正好是当下大模型落地的核心痛点。模型已经有足够强的语言、推理和代码能力,但一旦进入具体生产链路,就会暴露出没有「现场感」的问题。它不知道公司内部术语,不知道品牌口径,不知道这类方案过去怎么写,不知道哪些表达会被踩中老板的雷区。Skill通过把这些上下文装进一个可触发的包里,让模型不再凭通用知识瞎猜。
所以Skill的阳谋就在这里:它以帮你提高效果为名,让你主动完成了一次工作流整理。用户当然受益,因为输出更稳定;厂商也受益,因为它推动整个生态把专业能力变成模型可执行格式。模型厂商:他还得谢谢咱。
岂不是皆大欢喜。
3
Skill是模型厂商绕过垂直训练瓶颈的上下文工程方案
垂直行业的能力是很难靠继续堆通用预训练解决的。原因很简单:高质量行业语料稀缺,而且很多关键知识根本不在公开的文本里。这些东西散落在各个环节,可能是关键人的脑子里,可能是内部的文档/wiki里,也可能是本地电脑的PDF/Excel里,模型根本拿不到。
网上能公开出来的,都是脱敏过的优化过的,包装出来的语料,拿着这套东西训练出来的通识模型想做专业工作,那是天方夜谭。
传统路线是微调或专门训练,但这条路成本高、周期长、数据敏感,还很难覆盖每个组织的细碎差异。Skill则给了一个更产品化的解法:模型参数保持通用,任务发生时再加载正确的上下文和规程。这个结构比为每个行业训练一个模型更轻,也更符合真实企业的定制需求。
由此,一种新的能力分层出现了:底层是通用大模型,中间是工具和上下文,最上层是用户定义的工作流。厂商掌握底层运行环境和Skill标准,用户贡献上层流程和资源。短期收益叫定制化,长期收益叫模型厂商把垂直能力外包给生态,再把生态重新纳入自己平台。
4
Skill可能是专业工作流的App Store前夜
如果Skill继续发展,它会越来越像早期的App Store。
Skill更像一种新的软件形态:用自然语言写流程,用文件夹组织资源,用脚本补足执行,用模型完成推理和生成。Skill时代的软件可能会演变为人说需求,模型根据Skill调用流程。
一旦这种形态成熟,模型厂商的位置就会变得非常关键。它提供底层模型,也提供Skill的运行环境、安装机制、权限系统、触发逻辑和分发入口。用户和开发者会不断贡献各种垂直Skill:写作、法务、销售、财务、教育……
每一个Skill都可以是一个小型工作流应用。
这很像App Store的早期。平台真正掌握的是标准、入口、分发、审核和生态秩序。Skill也是如此。模型厂商如果定义了Skill的格式和运行方式,就可能定义未来专业工作流如何被AI调用。
而且我感觉,现在这种所有Skill都开源的方式还是太互联网了,以后高质量的Skill需要付费购买,就像买App一样,是可能发生的事情。
5
最后,从历史沿革的角度再看一下,厂商们的阳谋进化史,你会发现AI行业里发生的各种事情,还是不新鲜呐:
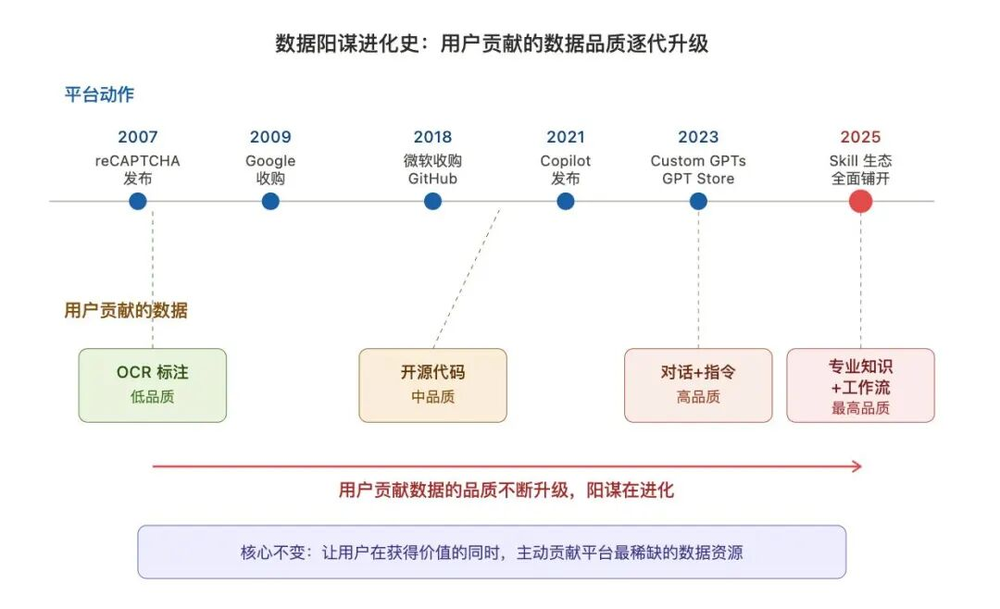
以上。