
本文来自微信公众号: 机器之心 ,编辑:panda、+0,作者:关注具身智能的,原文标题:《刚刚,国产预训练具身大模型开源了,让后训练不再是必选项!》
2026年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到benchmark成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。
这股竞赛背后藏着一个行业里心照不宣的困境。大多数VLA模型的评测,都是在针对特定任务微调之后才进行的。说白了,就是先技术细节,而是关乎整条技术路线的根本问题:我们是在训练「通用机器人大脑」,还是在为每台机器人定制一套任务脚本?
就在这场关于泛化能力的追问中,自变量机器人(X Square Robot)选择了一种更直接的回答方式:直接把没有经过任何任务微调的预训练模型搬上真实机器人,在17个任务上公开测试。这个模型叫Wall-OSS-0.5。

要理解这项研究成果的意义,需要先知道机器人策略模型是怎么被训练出来的。
一个典型的VLA模型会先吸收大量的视觉和语言数据,形成对世界的基础认知,就像一个刚从大学毕业、学过很多理论的新人。但要让它真正上手操作,还需要针对具体岗位进行「在职培训」:给它看几百条这个任务的示范轨迹,让它学会「怎么拧螺丝」或者「怎么折叠毛巾」。
问题在于,这种「考前培训」模式让人很难判断:是大学课程(预训练)起了作用,还是培训班(微调)解决了问题?过去的多数论文都是在微调之后才汇报成绩,让预训练阶段的真实贡献始终藏在迷雾里。
Wall-OSS-0.5提出的问题是:如果不允许微调,预训练的模型能干什么?
答案出乎意料地乐观。
预训练即可部署
Wall-OSS-0.5是一个VLA模型,在超过20种机器人形态、每轮超过100万条轨迹的数据上完成预训练,同时混入了约9000万条多模态语料。
Wall-OSS-0.5能力概览:涵盖预训练真实机器人行为、下游适配、仿真迁移及具身多模态理解。
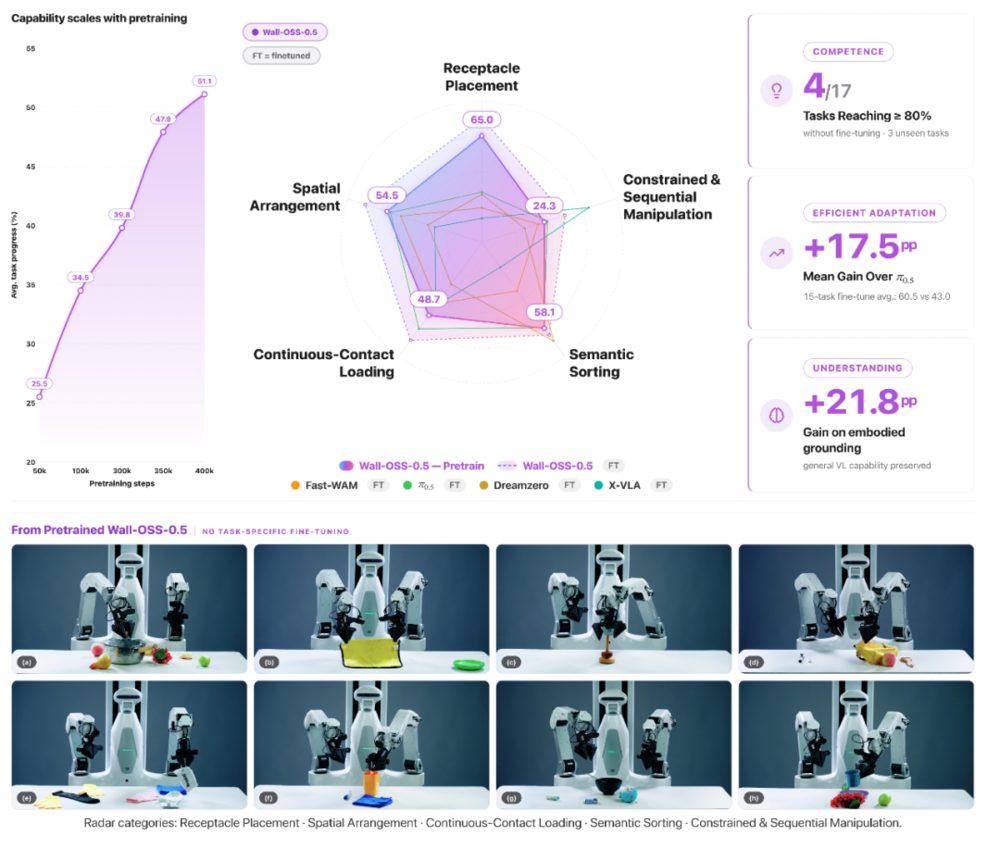
自变量团队随后把这个完全没有任务特定微调的预训练checkpoint,直接放到真实机器人上跑了17个任务,涵盖语义理解、刚性物体操作、柔性物体操作、精细操作和长程多步操作五大类别。
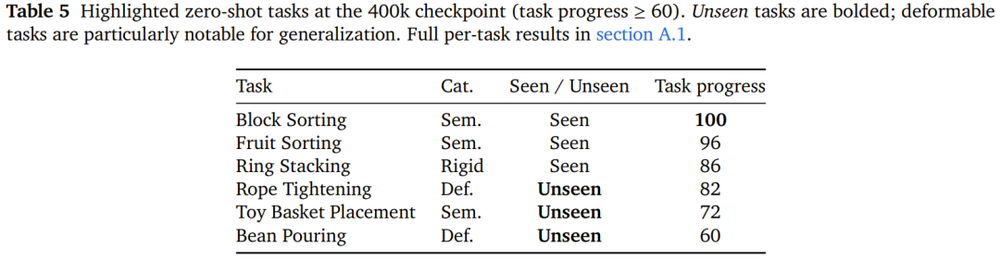
结果非常亮眼!400k预训练步数的checkpoint在17个零样本任务中,4个任务的得分超过80分(满分100分):
400k预训练checkpoint达到了及格分数的任务(零样本)。
积木分拣(Block Sorting):100分(已见任务)
水果分拣(Fruit Sorting):96分(已见任务)
套环叠放(Ring Stacking):86分(已见任务)
绳子收紧(Rope Tightening):82分(未见任务,柔性操作)
需要特别注意的是「绳子收紧」这个任务。它是一个完全没有在预训练集中出现过的柔性物体任务,属于17个任务中最难的类型之一——不仅需要双臂协调,还要感知绳子的松紧状态并动态调整力度。
能以82分的成绩完成,是这次实验最有说服力的数据点之一:模型不是「背过」这道题,而是真的迁移了某种可复用的操作能力。
从训练进度来看,这些能力并非一开始就有。随着预训练步数增加(从50k步到400k步),见过的任务平均得分从26.1升至50.0,没见过的任务平均得分从24.2升至53.6——两条曲线几乎并排上升。这意味着模型积累的能力确实在向新任务迁移,而不只是记住了训练分布里的任务样板。
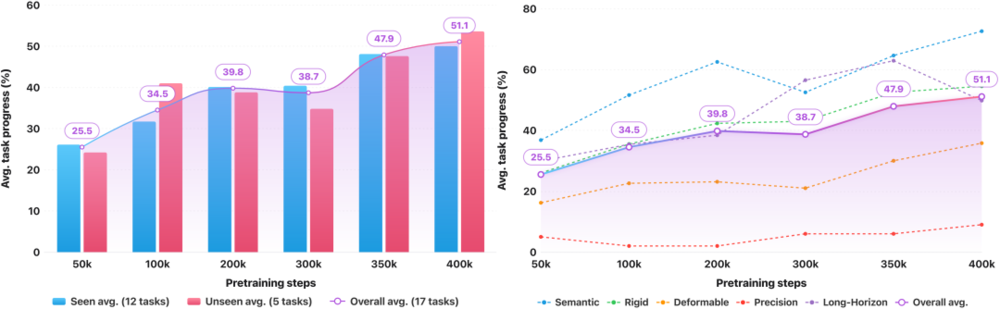
不同的预训练checkpoint的零样本评估趋势。
论文称这种现象为能力的阶梯式涌现(staircase emergence):积木分拣从大约50分跳跃到100分,套环叠放从73分跳跃到100分,都发生在训练中后期的某个临界点。这像极了大语言模型中观察到的涌现现象。更重要的是,到400k步时,整体平均任务进度还在上升,尚未饱和,这意味着更长的预训练有望能带来更多提升。我们也期待进一步的研究为我们揭示具身智能预训练的Scaling Law。
当然,零样本并非万能。毛巾折叠(10分)、餐桌摆设(9分)、充电器插接(9分)这三个任务几乎无法完成,它们涉及柔性形变和精细对准,是对精度要求最高的类别,单靠预训练还远远不够。
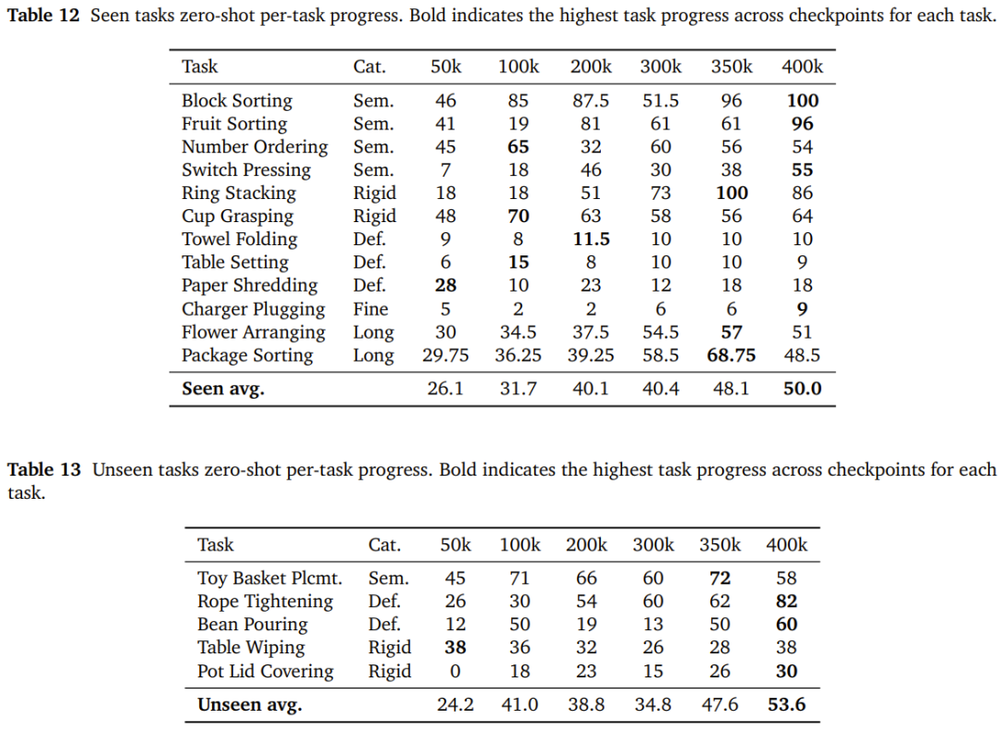
不同预训练步数的checkpoint在不同已见和未见任务上的零样本表现。
这些任务清晰地描绘出当前能力边界:一旦任务的「语义理解」成分占主导,预训练就能发挥;一旦涉及精度等更多要求,就需要微调来补足。
不仅学得快,还越动越聪明?
如果说零样本测试证明了Wall-OSS-0.5拥有「物理直觉」,那么在需要针对特定任务进行微调的场景下,它则展现出了作为基座模型的「先验优势」。
微调阶段的大幅领先
在包含15项真实机器人任务的微调评估中,Wall-OSS-0.5展现了极高的学习效率与上限。对比行业标杆π0.5,在同样的微调数据预算下,Wall-OSS-0.5的平均任务进度达到了60.5,不仅领先前者17.5分,更是在涵盖抽屉整理、碗中放勺等10项核心操作任务的子集上,将领先优势扩大到了26个百分点。

这种优势在主流仿真基准测试中同样表现稳健:
高难度操作:在RoboCasa厨房模拟环境的精密插入(Insertion)任务中,Wall-OSS-0.5的成功率达到了39.6%,而π0.5仅为4.0%,在强约束任务的处理上实现了近乎一个数量级的提升。
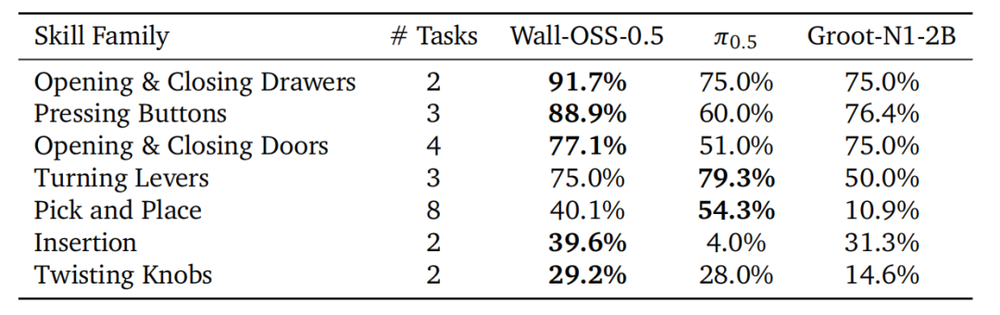
在RoboCasa厨房操控任务中的分项对比。Wall-OSS-0.5在articulated(关节)及insertion(插入)等精细操控任务中优势极为明显。
适配效率:在LIBERO单臂操控基准上,Wall-OSS-0.5仅需20k步微调即达到97.5%的平均成功率,不仅成绩超越了π0.5经过30k步训练的成绩,更直接节省了约三分之一的算力与适配时间。

场景鲁棒性:在包含50个双臂协作任务的RoboTwin平台中,面对充满光照与背景干扰的随机化场景,Wall-OSS-0.5依然保持了80.9%的高成功率,展现出极强的域外泛化能力。
动作训练还能倒逼感知能力进化
在以往的具身智能研发中,让模型「肢体发达」(学会操作)往往伴随着「头脑简单」(视觉-语言理解能力退化)的代价。但Wall-OSS-0.5在接受高强度的动作训练后,其基础图文理解能力不仅没有崩坏,反而迎来了对机器人至关重要的「能力重塑」。
测试显示,该模型在具身视觉定位任务上的能力暴涨了21.8分,在Placement reasoning(放置推理)任务中提升了11.0分。这标志着模型并没有因为学习动作而变成一个只会输出坐标的「盲目机器」,而是主动将自身庞大的通用视觉算力,倾斜到了「寻找目标、判断方位、推理落点」这些操控任务最急需的感知能力上。
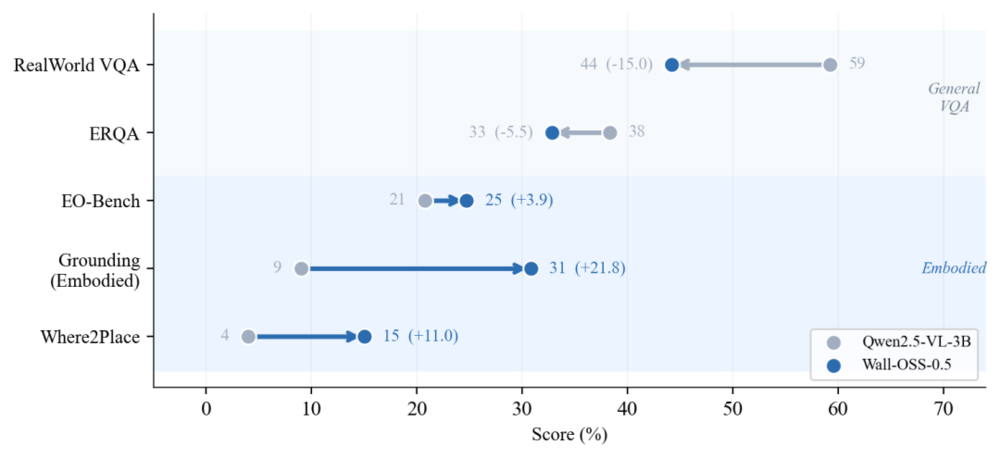
多模态感知能力的「能力重塑」。通过协同训练,模型将通用视觉算力转化为机器人更急需的具身感知能力,在Grounding和Where2Place等任务上表现出显著的性能跃迁。
这种「鱼与熊掌兼得」的特性,证明了其协同训练方案不仅有效,而且在物理世界的感知与操作之间建立了一种良性的互补关系。
Wall-OSS-0.5为什么这么强?
从结果来看,Wall-OSS-0.5着实相当强,甚至可以说有点反常:一个从未见过这些任务的预训练模型,零样本就能完成柔性双臂操作;微调后更是在多个任务上将π0.5甩开30个百分点以上。这种级别的领先,不像是某个超参数调得更好的结果,而更像是底层训练逻辑上的系统性差异。
那么,它到底做对了什么?
答案其实隐藏在一个被很多人忽视的差异中:大语言模型输出文本是「一截一截」的离散状态,而机器人的物理动作必须是「丝滑连贯」的连续曲线。如果把动作直接以连续信号灌入主干,这股信号对习惯了文字接龙的VLM来说太微弱,根本无法撼动其底层认知。论文数据也印证了这一点:训练稳定后,流匹配损失对主干的梯度贡献仅剩约5%。
换句话说,要想让连续动作直接「教会」主干大脑,几乎是徒劳的。自变量团队的解法是:既然连续信号太弱,那就借道离散,把梯度强行送进去。以下四项设计,共同支撑起这套「用离散路径传梯度、用连续路径做执行」的训练框架。
梯度桥接:让动作反向塑造主干大脑
当前主流的VLA训练大多采取「分层隔离」策略:先用海量视觉-语言数据预训练主干,再在其顶部挂一个动作专家单独训练。这种做法虽然安全,但代价是主干模型本身永远学不会「动作」,它只是在为动作专家提供特征,并不真正理解物理世界的可操作结构。
Wall-OSS-0.5的方法是:梯度桥接协同训练。团队将动作离散化为特殊的「字符Token」,与文本Token拼接到同一条自回归序列中,用大模型最原生、最强烈的交叉熵损失进行训练。
这一支路就像在VLM大脑中架起了一座「梯度桥」,强迫主干在预训练阶段就把「看、说、动」统一在同一套表征空间里。同时,模型保留流匹配损失用于生成连续动作,并辅以多模态交叉熵损失作为锚点防止视觉语言能力退化。三路信号协同开火,消融实验证明:一旦砍掉这座「桥」,真实机器人任务成功率会出现断崖式下降。
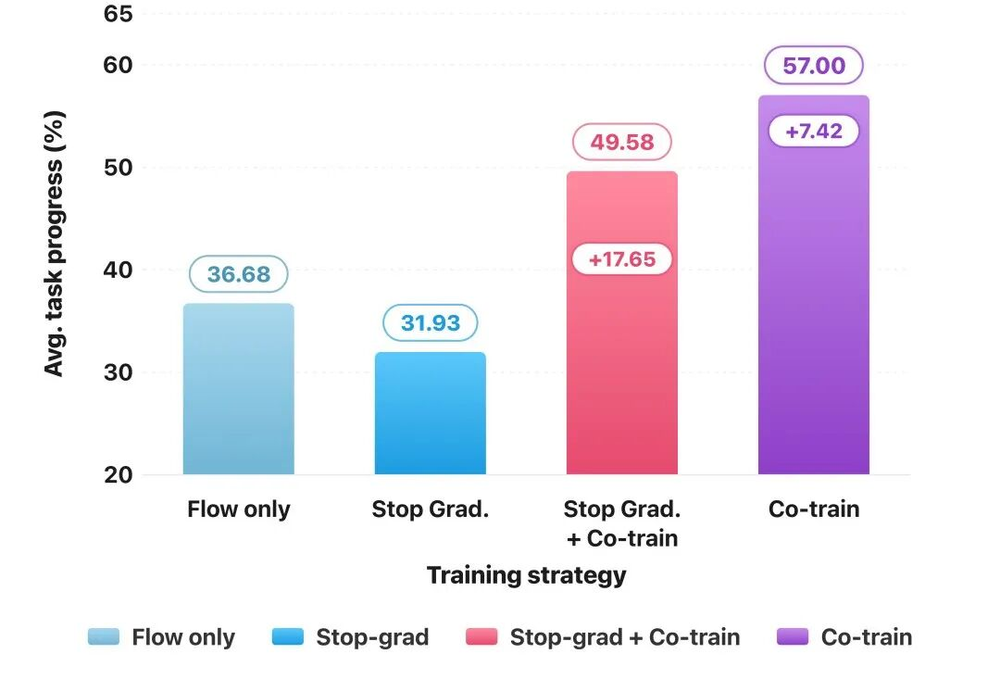
梯度桥接效应验证。实验证明,将动作监督通过「梯度桥」直接引入主干,远胜于简单的分层隔离策略。
视觉对齐的动作Tokenizer:传递语义,而非数字
梯度桥建好了,但跑在桥上的是什么货?如果离散Token只是对动作做机械的数值压缩,那传进主干大脑的只是一串没有物理意义的编号,主干学到的也只是统计学上的共现。业界广泛使用的FAST Tokenizer就存在这个问题:它能还原动作,但并不知道这个动作「对应画面里发生了什么」。
Wall-OSS-0.5训练了一个视觉对齐的残差向量量化Tokenizer。它在量化动作的同时,强制Token的表征与对应时刻的视觉特征对齐,并要求其预测下一帧的视觉变化。这样一来,每一个动作Token都同时承载了「电机怎么转」和「画面怎么变」两层信息。它和视觉、语言进入了同一个语义空间,主干网络在预测下一个动作时,其实就是在脑海里进行高维度的时空推演。
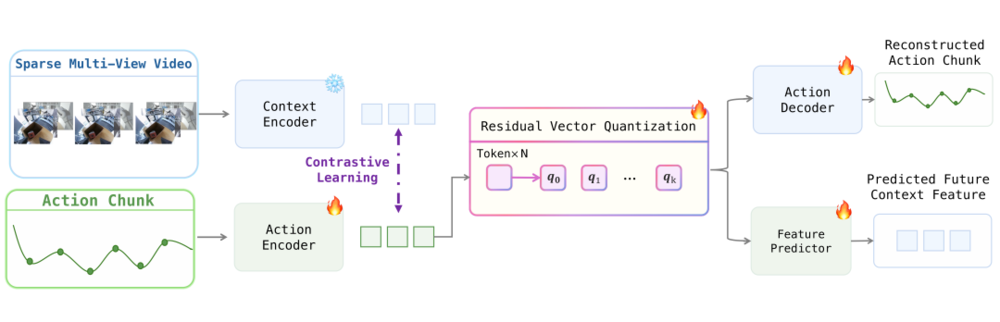
视觉对齐动作Tokenizer的工作流。模型不仅压缩动作,更强制动作表征与视觉特征对齐,赋予Token真正的「物理含义」。
动作空间监督:把好钢用在刀刃上
主干懂了语义,但最终指挥机器人躯体干活的,还得靠连续分支输出的轨迹。流匹配的标准做法是预测「速度」(噪声到目标的瞬时方向)。然而,机器人的物理动作轨迹有一个特性:整体形状(低频结构)决定任务能否完成,而高频细节几乎不影响成败。如果在速度空间里算损失,模型会像强迫症一样,把大量算力浪费在拟合无关的高频抖动上。
自变量团队直接修改了底层逻辑:把损失从「预测速度」改写为「预测重建出来的最终动作」。这在数学上等价于对动作轨迹成型初期(高噪声阶段)进行了自动加权。这就好比让画师先集中精力把人体的骨架打准,再去描绘衣服的褶皱,让模型在仿真中跑出了远超前人的收敛速度和稳定性。
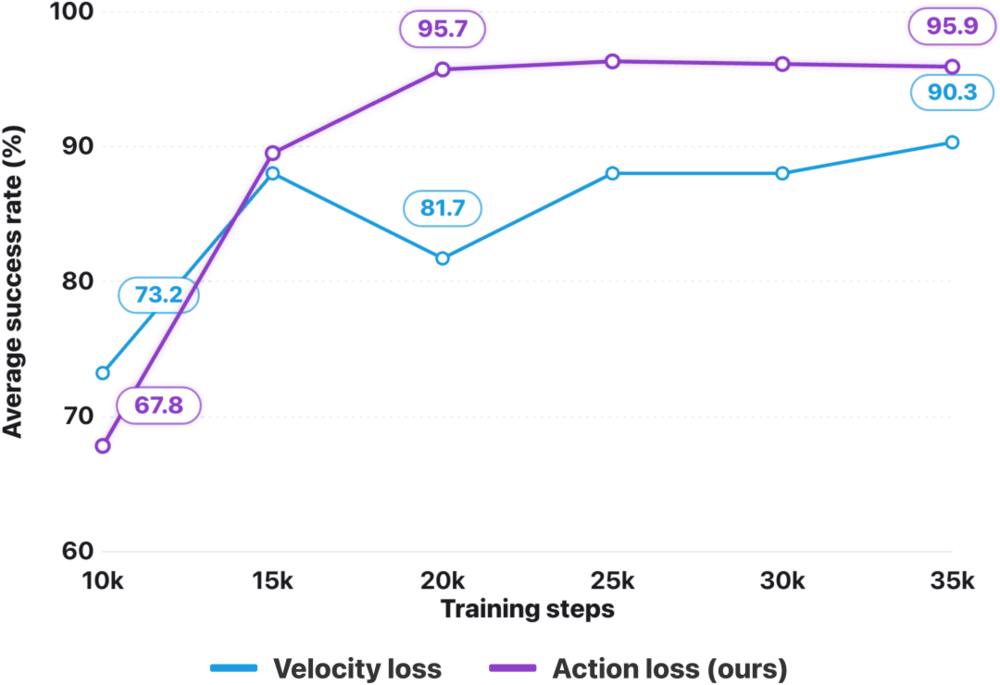
动作空间监督vs速度空间监督。通过将学习重心调整至轨迹结构的塑造,模型在训练效率和成功率上均表现更优。
DMuon:扫除异构计算的系统工程路障
上述极其精妙的多源监督架构,带来了一个工程层面的副作用:模型内部参数尺度与梯度强度高度异构:VLM骨干来自大规模预训练,动作头则是从头初始化,三路损失反传的梯度量级系统性失配。
这是Muon优化器的用武之地:通过Newton-Schulz迭代对更新矩阵做正交化,能有效缓解这种异构困难。但原生的Muon单步开销大得离谱。
为此,团队实现了DMuon(分布式Muon)。结合基于LPT的专属所有权调度以及回收迭代冗余计算的CuteDSL内核,他们把引入Muon的整体开销从2x降至0.02x,缩减了约100倍。这种即插即用的系统级优化,让这套庞杂的训练配方在大规模集群上真正成为现实。
四项设计,各有侧重,但指向同一个目标:让主干网络在预训练阶段就真正「经历」过动作,而不只是「见过」动作数据。梯度桥确保动作监督能穿透进主干;语义Tokenizer确保穿透进去的是有物理意义的信号;动作空间监督确保连续执行路径把好钢用在刀刃上;DMuon则确保这套精密配方在真实的大规模训练中跑得起来。
开放,是通向通用机器人的唯一密码
当然,具身智能还有很长的路要走。毛巾折叠和充电器插接还在10分以下,长程任务仍依赖单帧视觉输入……这些未解决的问题,论文里写得很清楚,团队也没有回避。
整体而言,Wall-OSS-0.5为具身智能研究提供了一套经过真机验证、可以被复现和挑战的基线,可以成为关注这个方向的研究者和开发者进一步探索开拓的起点。