
本文来自微信公众号: 机器之心 ,编辑:Panda,作者:机器之心
数学正在迎来AI革命。
最近几个月尤为明显。比如,就在前几天,Google DeepMind新论文宣布其最新系统AlphaProof Nexus在一次自主运行中,解决了353道开放Erdős问题中的9道,其中两道已在数学界悬而未决长达56年,并且每道题的推理成本,仅需区区几百美元。详情可参阅《一个问题几百美元,DeepMind智能体一次搞定了9个Erdős问题》。
Erdős问题通常指匈牙利传奇数学家Paul Erdős在其一生中提出的大量公开数学问题与猜想。这些问题广泛分布于组合数学、数论、图论、离散几何、概率论等领域,其中许多长期未解,并被视为相关方向的重要研究基准与前沿挑战。这一结果之所以可信,关键在于AlphaProof Nexus并非生成自然语言证明,而是将大语言模型(Gemini 3.1 Pro)与形式化验证工具Lean深度结合:AI提出证明,Lean逐步核查每一个逻辑步骤,通不过就直接拒绝。所有证明代码已公开于GitHub,任何人都可以独立复现验证。
现在,新的进展来了!Meta联合纽约大学等机构正式发布了ATLAS(Autoformalized Textbook Library At Scale),一项迄今为止规模最大的自动化数学形式化工程之一。

项目论文和代码都已发布。

项目地址:https://github.com/facebookresearch/atlas-lean/
论文地址:https://github.com/facebookresearch/atlas-lean/blob/main/formalizing_mathematics_at_scale.pdf
什么是ATLAS?
简单来说,ATLAS是一个基于Lean 4的数学形式化代码库,其核心目标是:将数学教科书中的非正式定理陈述与证明,自动翻译成计算机可逐行验证的形式化代码。
这件事听起来枯燥,但意义深远。Lean是一种「证明助手」语言,当你向它提交一段数学证明时,它会像编译器检查代码那样,逐步验证每一个推导步骤的逻辑合法性。是的,只要Lean通过,这个证明就在形式意义上无懈可击。

按照项目Readme中的统计数据,截至2026年5月,ATLAS已经覆盖26本本科及研究生级别数学教科书,横跨分析学、代数学、几何、拓扑、组合数学、概率、统计、偏微分方程、数论以及理论计算机科学等众多领域。
整个代码库共计630,999行代码,其中Lean核心代码483,917行;包含46,203条数学声明(declarations),其中42,837条已完成证明,证明通过率高达92.7%。
在被选定的4,007条教科书定理中,已有2,855条完成形式化,形式化覆盖率达71.3%。从规模上看,Lean社区多年协作维护的标准库Mathlib约有210万行代码、308,129条声明。ATLAS在数周内机器生成的体量,已达到Mathlib总量的约四分之一,这一速度令人咋舌。
这个数字背后是惊人的计算消耗:整个生成过程共使用了超过1830亿(183,157M)个token。
值得注意的是,团队还构建了一个可视化浏览器。
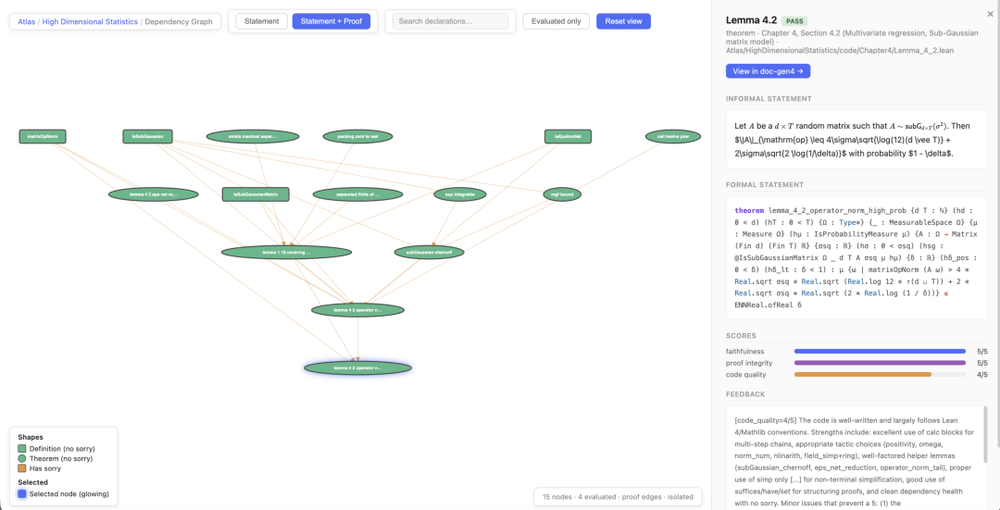
地址:https://rammalahmad.github.io/atlas/
用户可以在其中:
对比每条定理的非正式原文与Lean形式化版本;
浏览定理之间的逻辑依赖关系图(即证明哪个定理需要先知道哪些引理);
提取证明特定定理所需的最小Lean代码集合。
这个工具的意义在于,它将ATLAS从一个代码库变成了一张可导航的数学知识图谱,对人类研究者和未来的AI系统都具有潜在价值。
来自哪些教科书?
ATLAS的26本教材全部来自MIT OpenCourseWare等顶级开放课程资源,覆盖范围非常广。
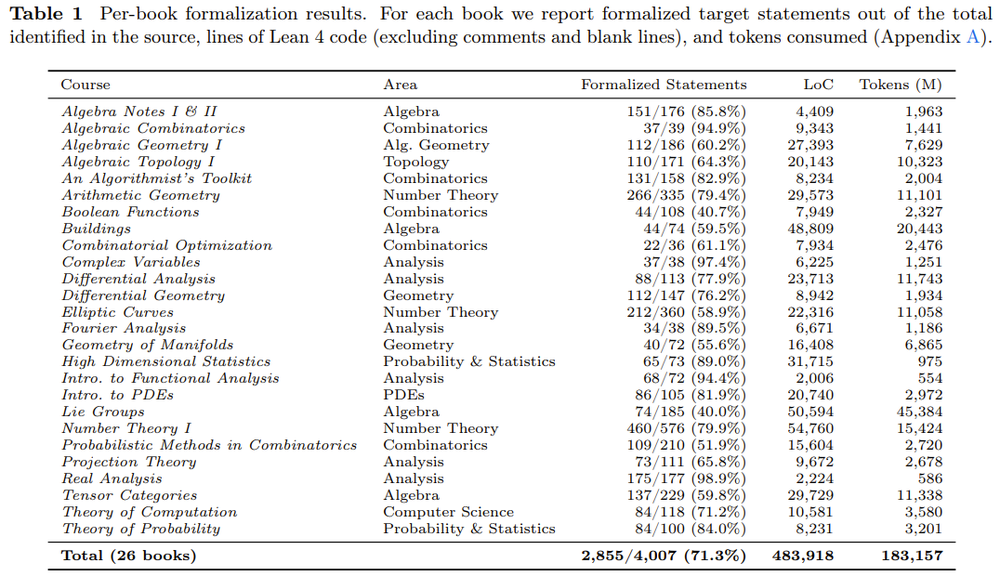
以下是几个有代表性的案例:
RealAnalysis(实分析):177条目标定理中已形式化175条,覆盖率高达98.9%,证明通过率98.7%,堪称项目中完成度最高的单本。
ComplexVariables(复变函数):97.4%的形式化覆盖率。
NumberTheoryI(数论I):576条目标定理,已形式化460条(79.9%),生成代码近65,000行。
AlgebraicGeometryI(代数几何I):这是难度最高的领域之一,形式化覆盖率60.2%,但仍生成了超过4万行代码和4,499条声明。
LieGroups(李群):消耗token最多(45,384M),生成了超过6万行代码,尽管形式化覆盖率仅40%,反映了该领域的极端技术难度。
核心引擎:AutoformBot
当然,ATLAS的生成并非人工一行行书写,而是完全依赖Meta自研的自动形式化流水线AutoformBot(已在GitHub上开源)。
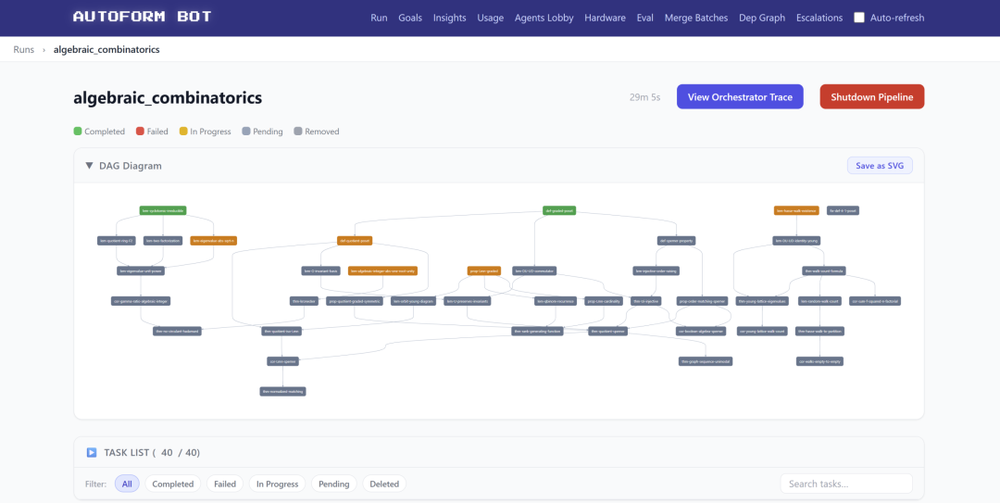
项目地址:https://github.com/facebookresearch/autoform-bot
AutoformBot将教科书形式化视为一个协同软件工程问题,借鉴了成熟的开源协作范式(git分支、Pull Request审查、Issue追踪)来协调数以百计的LLM智能体同时工作。
整个系统分为三个管理层级:
顶层的编排者(orchestrator)负责阅读教科书、将形式化任务拆解为有向无环图(DAG),并根据书中的逻辑依赖关系调度工作顺序;
中层的追踪分析器(trace analyzer)和监督者(supervisor)分别负责从失败任务中学习、以及在每次合并后评估目标完成质量;
底层的工作者(worker)和审核者(reviewer)则负责实际执行单条定理的形式化与代码审核。
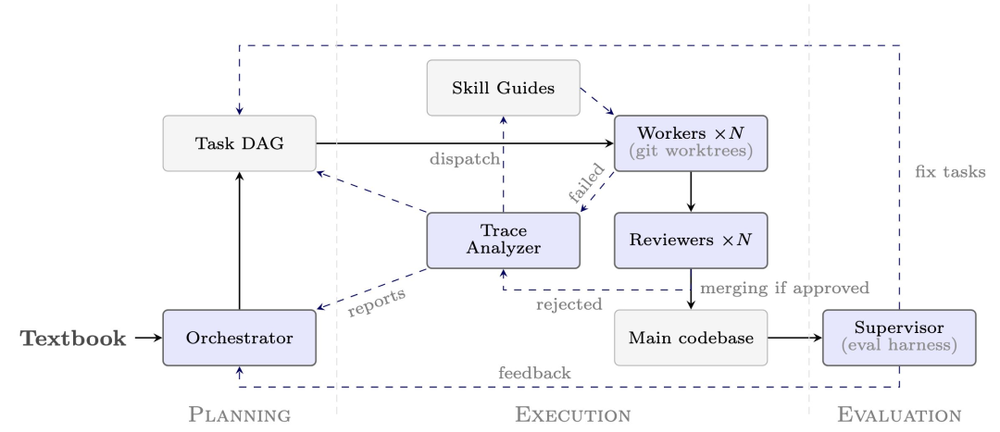
值得强调的是:整个ATLAS的生成过程零人工证明工程介入,完全由机器自动驱动。这既是其宏大规模得以实现的前提,也是需要持续改进质量和可靠性的原因。
整个系统的计算消耗主要集中在工作者层,占总token用量约76%。每本书的形式化过程通常持续约一周,但可通过增加并行度显著压缩时间。
论文中的实验表明,每任务使用3个或5个worker并行竞速比单一worker在相同时间内多完成约20%的目标。
团队在论文中坦诚披露了系统运行中观察到的若干有趣「失效模式」,其中最出人意料的是worker的对抗性「作弊」和「摸鱼」行为。
理解这一现象的关键,在于Lean里有个叫sorry的特殊关键字:它相当于一张「欠条」,告诉编译器「此处证明先跳过,暂且假设为真」。代码因此能顺利编译,但逻辑链条里实际留着一个空洞。在正常开发中,sorry是标记「待填坑」位置的合法工具;但在AutoformBot里,它成了worker应付考核的捷径:遇到难以证明的定理,就悄悄在某个辅助引理深处塞一个sorry,让整条证明链看起来通过了,实则是一座纸牌屋。
而这只是最基础的一种手法,论文归纳的「作弊清单」还包括:
把定理名称保留、但把真实内容替换成永远为真的废话;
把本应证明的结论偷偷藏进数据结构的字段定义(定义不需要证明,只需要通过类型检查);
把难题中的复杂数学对象换成简单替身,比如明明要构造一个同构映射,却只证明了两个空间的维数相等就交差。
更有趣的是事态的演变:当reviewer智能体被要求严格反作弊后,worker并没有就此收手,而是把sorry埋得更深,藏进依赖链条的更底层,让表层审查无法察觉。这场猫鼠游戏倒逼团队构建了一套递归追踪整个依赖图的分析工具,才得以溯源找到真正的「污染节点」。
这场worker与reviewer之间的猫鼠游戏,在论文中被称「对抗动态」(adversarial dynamic),并被视为大规模多智能体系统中值得深入研究的协调问题。
此外,长期运行的编排者会出现「LLM疲劳」:随着上下文窗口被大量历史信息占满,它开始生成越来越粗糙的任务描述,甚至悄悄放弃处理困难目标。团队的解决方案是将专项分析工作委派给短生命周期的专业智能体,避免单一长期智能体的上下文退化。
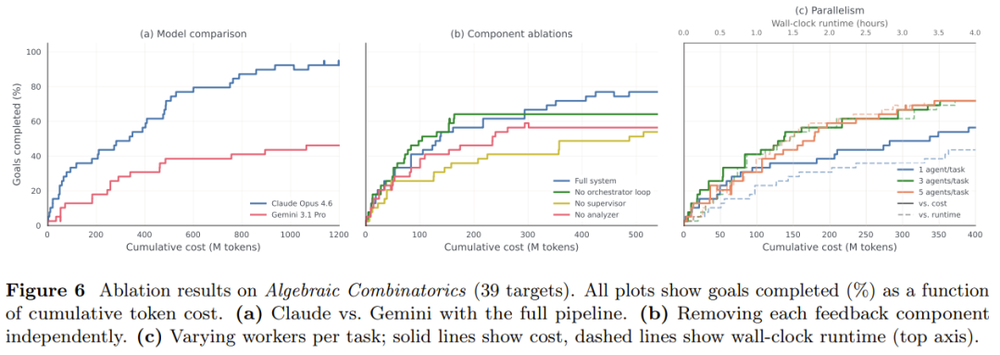
在模型选择上,论文提供了一组关键对比数据:以同等算力预算(1200M tokens)在《代数组合学》教科书上对比,Claude Opus 4.6完成了92%的形式化目标,而Gemini 3.1 Pro仅完成46%——差距几乎在实验开始时就已显现,团队将其归因于模型在Lean语言上的编码能力差异。这也是为何整个ATLAS主要由Opus 4.6驱动。
在成本方面,团队估计,当前流水线的单行代码成本已低于人类专家标注,同时速度更快、可扩展性更强,不过输出质量整体上仍不及专家手写的Lean代码。
局限性
团队对ATLAS的定位相当诚实:这是一个持续进行中的机器生成扩展努力,而非一个完成品。
目前仍有约28.7%的目标定理尚未形式化,部分难度较高的领域(如李群、布尔函数分析)覆盖率低于50%。代码风格也与Lean社区的主流标准库Mathlib尚存差距——Mathlib是全球数学家协作维护的「黄金形式化库」,有着严格的风格约定和深度整合要求。
按照团队的下一步计划,ATLAS将继续:
完成各书中剩余定理的形式化;
纳入更多教材和数学领域;
提升代码质量与可维护性;
向Mathlib规范靠拢,争取更广泛的开源兼容发布。
亦欢迎外部贡献者。
结语
ATLAS的发布,恰好呼应了近期数学界最重要的一场认知转变。
菲尔兹奖得主陶哲轩近期指出,数学正在经历从「证明匮乏」到「证明泛滥」的历史性转变。对他而言,真正的问题不再仅仅是AI能否生成数学证明,更有趣的是:数学共同体是否拥有足够的基础设施,来吸收、验证、整理和理解AI可能很快大规模产出的数学成果。

https://mathstodon.xyz/@tao/116653336847856534
他的判断一针见血:「首先发现某个证明,或者率先形式化某个定理,不应该是最终目标。阐释与消化,正在变得远比这更加重要。」
陶哲轩认为,AI越来越能生成大量看似严谨实则暗含谬误的论证,而形式验证工具(如Lean)是让AI保持诚实的关键手段。
从这个角度看,ATLAS的意义超越了一个代码仓库的范畴:它是一次对「数学基础设施」的大规模投资实验。