
本文来自微信公众号: 未来光锥 ,作者:刘淼,原文标题:《刘淼:数据是 AI 时代材料科学唯一的壁垒 | AI for Science沙龙》
为什么AI时代要讲数据?
这是AI领域大家特别关注的一件事。AI的到来给了我们一个特别好的工具——在这个时代我们其实有了“infinite mind”(无限心智),用机器去帮我们或者代替我们思考,从而让各个领域都获得非常高效的进步。
如果我们看Gartner 2025年(高德纳)的新兴技术成熟度曲线,标出来的这些技术基本上都是AI和机器人。也就是说,几乎所有领域被效率革命的方式都是“AI加机器人”。在这种情况下,科学领域也会面临很大的挑战和变革。
从国际上看,大家都在做这件事:
美国:特朗普政府提出的AI行动计划,把芯片、数据中心、模型都放在了非常重要的位置。其中和科学相关的内容,可以归纳为三件事:自动化实验室、高质量数据集、计算基础设施。在科学领域落实这件事,是通过美国能源部(DOE)的Genesis Mission(创世纪任务)——用科学去变革研发方式,加速材料科学的发现。
中美对比:在战略上中美其实是一致的,但策略不同。我们偏政府主导、政策主导,美国偏市场化主导。
在这个背景下,美国科技公司的进步非常大:
DeepMind在2023年底发布了GNoME数据集和模型,号称通过高通量计算的方式发现了38万种热力学稳定的材料,相当于人类800年知识积累的总和。
Microsoft也做了很多事,比如MatterGen和MatterSim,对这个领域有很大的推动。MatterGen用生成式的方法,给出材料性质,就可以推测和推理出该材料可能的组分构型。
学术界:英国Andy Cooper团队、美国Gerbrand Ceder团队,都用机器人的方式自主化地去发现新材料、改革制备工艺,效率有特别大的提升。
新兴公司:DeepMind、Microsoft和Meta的一些人合作成立了一个新实验室叫Periodic Labs,这是由Google的各种X-Labs出来的团队,估值非常高,要用AI和机器人变革材料科学。最近Jeff Bezos也有动作,号称要投资62亿美元,这是他卸任Amazon CEO之后唯一一次在一家公司担任管理角色去推动的事——他做的叫Physical AI,材料科学可能是其中的一个板块。

在行业进步的带领下,我们现在面临的是AI在材料领域的应用,仔细看你会发现,大家都是从数据开始做的。
我列出来一些材料科学数据领域的进步。过去两个诺贝尔奖(化学奖和物理奖)多多少少都是AI方向的,但本质都是数据的进步。所以近期Google DeepMind、Meta、Microsoft都开始做这样的数据集。在国际范围内,这条技术路线已经勾画得非常清楚了。

如何去做?
这些大公司都在做的一件事是:用密度泛函理论(DFT)去做计算。计算一个材料已经非常容易,于是可以批量计算材料的性质——根源是解密度泛函理论,也就是解电子的薛定谔方程;知道电子的行为之后,就可以推测出材料的各种性质。这已经是非常稀松平常的事了。
这就是科学发展的“第四范式”:在数据基础之上,做各种各样的AI工具。回头看,数据计算的奠基人和先驱者是Materials Project,之后各国科研机构都开始做。近期Google、Microsoft、Meta也都加入。我们是在中科院物理研究所和松山湖材料实验室下面做这件事,现在这个实验室一部分也被独立为东莞材料科学与技术研究所。
ICSD(无机晶体结构数据库)里人类已发现的已知材料很快会被算尽,所以我们通过元素替代的方式不断扩增化学空间。

举几个具体例子:
超导体发现:已知一个化合物之后,我们替换元素做高通量计算,找到这个空间里哪些化合物是稳定的,发表出来指导实验。我们从数据库里筛选出和MgB₂(二硼化镁)结构类似的一个超导体——从筛选到实验合成,只用了3个月时间就把新材料发现出来。
全固态电池:现在做电池有一个困难是,电极材料和电解质材料会发生副反应——界面处的副反应会让电池的效率和循环性能变低。解决方案是找一层中间层把电极和电解质隔开。我们有这样一个工作流,可以从5万多个化合物中筛选出几十个比较好的镀层材料。我们还筛选了电池的正极材料,找到了一个氟化物的钠电池材料,如果合成出来,其性能超过现在的磷酸铁锂。这些已经被我们申请成了专利。
-预测材料稳定性:给定一个原子在空间摆开的构型,力场可以快速把它带到平衡态的位置。
-微调(Fine-tune):在预训练力场的基础上,用少量数据就可以微调到更合理的情况,比如可以分辨钛金属体系从HCP到FCC的相变,这在传统经验势能(empirical potential)里一直是难点。
-离子晶体分子动力学:我们对一个流行的全固态电解质做了离子扩散率的模拟,结果和实验值非常接近。
如何选择科学问题?
传统上大家做这些AI的事情时,都以数据为起点或判据。如果数据是合适的,你就可以拿这些数据做合适的科学问题。
DeepMind其实是挑选问题的高手。他们选AlphaGo的原因是因为围棋的数据质量非常高,不存在主观偏见、模糊的问题,预测指标也非常清晰。
所以选择科学问题永远是人工智能领域最重要的一步。怎么选择?拿数据来做一个非常重要的判据。
-2023年:用Llama 2做了一些训练,发现有迹象,但难度和资源需求都非常大。
-2024年:发现可以用RAG(检索增强生成)模式去做。
互动提问
提问1:10年后的材料实验室会是什么样子?
刘淼:这是个开放性的问题,我没有答案。因为这个领域发展太快了,顶多能看个两三年。
但总的来说,我们可以看一下生物医药的发展,他们比材料科学发展早一点点。几乎所有材料科学里经历的事情,生物医药里其实已经做过了一遍——他们至少早20年就知道用AI计算找药,他们有各种各样的人工智能方案做新药发现,或者类似的软件/硬件产品。除了生物医药,材料科学可能是第二个在数据上具备类似发现或突破的领域。我觉得还是很有希望——既有很多未知,又有很多希望。
提问2:DeepMind、Microsoft发Nature都不再公布数据和模型了。你们把GPT-FF和材料数据库都免费开放,对国内免费是出于什么考虑?
刘淼:其实他们没有公布数据,但还是公布模型的。开源的意思不是“模型+数据+训练方式”全部开源,而是只公开参数。这又回到我报告的主题:数据很重要。所以各个领域的大模型公司,包括图像、世界模型、大语言模型,都不公开数据。材料科学也在朝这个方向发展。
这也是未来的趋势:数据将会成为这个行业的壁垒,其他的都不会是壁垒。模型已经不重要了,因为模型的壁垒已经非常小——你的模型比我的模型在同样数据底下效率高一点点,这种差异已经小到看不出来了。接下来无非就是怎么做数据,这会成为这个行业唯一的壁垒。在这种数据高价值的情况下,大家是不会把数据放出来的。我们的数据有些开放给大家浏览,但作为供机器学习使用的数据,没有人会放出来。
如果你要做这个行业或者任何AI相关的行业,如果没有在数据上占到先机,you will never make it(永远做不成)。每个企业都是这样。所以学生、投资人、每个行业的人都可以看一下:你要去的这家公司,在数据上是不是有先机——如果没有数据先机,there is no way you can go。
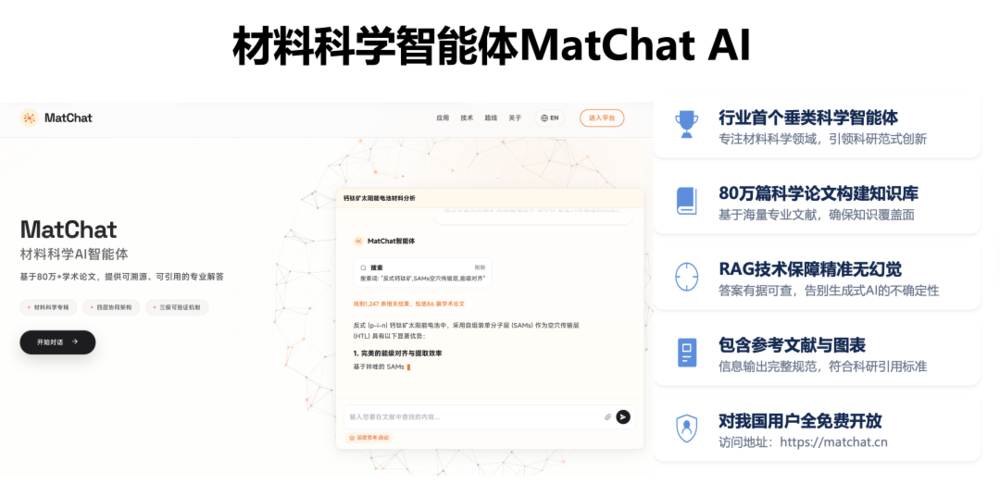
提问3:你们80万篇论文的数据是怎么清洗的?
刘淼:首先,我们在一个学术机构里面,有一些资源和条件可以获得论文全文。拿到论文全文之后,把PDF变成可用的数据,这里我们用到了浦江实验室的MinerU这一类的智能文档解析工具。这种行业先进的工具用起来,可以让某一个细节变得更好。
我想今天在座的我们几位都是在做科学的工程化。在这个行业里,科学已经做到一定程度的时候,可以通过工程化的方式让它变成生产力工具,把它做成产品、做成大家可以使用的工具的过程中,其实是工程思维——每个细节都到位,最后产品才能比较好。任何一个细节不考虑,最后产品就会因为那一个细节显示出不好的地方。
提问4:做AI的人很多都被业界高薪吸引过去了。AI for Science如何长期有系统地做下去?高校研究所有竞争力吗?
刘淼:我的感受是,这个领域做AI+科学的人,更多是从科学出身的。如果你单纯是AI出身,在这个领域很难往下做深入发展。做AI的人虽然工资很高,但那些做“生化环材”四大“火坑”专业的人出来,在AI+科学领域做事,对他们来说可能是一个让自己往更前沿方向走的机会。
人类社会人很多,每个人做的事情不一样,如果大家都做一样的事就没意思了。我们也希望吸引进来的人不是看钱,而是在思考“怎么样去创造价值”。这中间有一些有意思的、自己感兴趣的、好玩的事情。我相信这个领域还会不停地吸引人进来,至少我看到我们新进来的研究生干劲十足,所以我丝毫不担心这个问题。
最近我看了Yann LeCun(杨立昆)的一个播客访谈,他提出一个观点:如果你现在去一个大厂或者企业做大语言模型,或者在研究生阶段学LLM,其实非常无聊。我回头思考一下我们团队在做什么——有做基础设施的、有做产品的、有做数据的、有做模型的,这其实和一个大语言模型公司做的事非常相似,相当于他们的早期阶段。所以这个领域其实就像大语言模型的早期阶段,映射到我们这个行业中,因此这个领域是蓬勃发展的。
在这个阶段,与其去一个成熟企业、成熟方向里做一只小蚂蚁,不如来我们这个行业,做一个行业成长期、早期进来的独角兽。这就是我们在这件事上的取舍。