
本文来自微信公众号: 新潮沉思录 ,作者:潮思
2026年春天,中国学术界同时上演了两件引人注目的事。科普博主耿同学以一人之力接连举报多所名校杰青的论文数据造假,搅得生命科学圈天翻地覆。与此同时,全国高校在教育部指导下全面铺开毕业论文AIGC检测制度,要求学生的论文必须通过AI生成内容的筛查才能参加答辩。

两件事看似一攻一守,前者在追查造假,后者在防范代写。但如果把目光从事件表面移开,会发现它们的底层逻辑惊人地一致。
先说AIGC检测到底在做什么。它的原理并不复杂。人在写作的时候,用词带有不规则性,有时会选择不那么“正确”但更生动的说法,有时会写出结构松散但语感自然的句子。而大语言模型的生成逻辑是概率驱动的,它在每一个位置都倾向于选择统计上最合理的下一个词。
举一个直觉层面的例子,一个学生可能会写“这个问题很麻烦”,而AI在同样的语境下更可能输出“这一问题具有较高的复杂性”。后者在语法上更规范,在逻辑上更完整。AIGC检测系统的核心工作,就是捕捉这种过于工整的统计痕迹。它用一系列指标来衡量文本在多大程度上偏离了人类写作的那种不规则性,如果一篇论文在统计上太像模型的输出分布,就会被标记为疑似AI生成。
耿同学打假的核心方法在结构上与此完全同构,只不过对象从文本换成了数据。他检查的是论文数据中是否存在不自然的统计特征。等差数列般的实验数据、补充材料中几十组数据在小数点后两位完全一致,这些痕迹之所以能暴露造假,是因为人为编造的数据和文本面临同一个困境,人类对随机的直觉天生就不够好。真正的自然数据和人类写作都带有一种难以刻意模仿的不规则性,而伪造者无论多小心,都会在统计上留下过于整齐的指纹。
在这一意义上,两种检测做的是同一件事,那就是在表面的统计特征中寻找来源的线索。换言之,它们并没有构建出真正的因果关系。黑格尔在《精神现象学》中讨论颅相学时曾指出,从外在的骨骼形态推断内在的精神品质是一种根本性的范畴错误,外在的东西和内在的东西之间的那种对应关系是虚构的。今天的AIGC检测和耿同学的数据审查面临着结构上完全相同的困境,它们试图从文本或数据的外在统计形态倒推出内容的内在认知来源。
文本的困惑度低可能是因为AI生成,也可能是因为作者写了一段极其标准的学术语言。数据分布的过于完美可能是因为造假,也可能是因为实验条件控制得确实出色。正如颅相学所测量的颅骨形状是真实的,但颅骨形状与智力之间的关联是虚构的一样,AIGC检测所捕捉的统计特征是真实的,但这些特征与文本来源之间的关联同样是虚构的。
这两种检测之所以目前还能勉强起作用,只是因为AI还没有把那些虚假的统计相关性彻底抹平。一旦以后的造假者学会了用AI进行随机数生成(甚至这本来就不需要用到AI),这种基于统计学的打假还能持续下去么?如果对话型人工智能真的能做到让AI生成文本与人为写作之间不存在统计学上的显著差别,这些所谓的AIGC检测真的还有意义么?
事实上不需要等到未来,这种检测在当下就已经在大面积失效了。一个能将朱自清的经典散文判定为60%由AI写作,将《滕王阁序》判定为100%由AI写作的模型,真的适合拿来作为检测学术论文的工具么?更何况AIGC检测与查重在本质上完全不同。查重只需要拟合过去的数据库就行了,而AI写作将不断创造无限迭代的新数据,检测系统追赶的是一个正在加速远离的目标。

面对这一困境,与中国大学全面铺开AIGC检测相反,国外高校恰恰在这一问题上逐步撤退。澳大利亚科廷大学已经直接停用了AI检测系统,UCLA在内部审查准确率数据后拒绝采用Turnitin的AI检测功能。西方学术界的主流方向不再是发明更好的检测器,而是转向披露和过程评估。
那为什么AIGC检测在国内不仅没有撤退,反而在全面铺开?行政流程的需求只是原因之一。更深层的驱动力是一种弥漫在整个学术界乃至整个社会中的心理焦虑,那就是人们需要确信自己面对的文本是由一个真人写出来的。
这种对人为的执念本身就值得审视。它暗含了一个未经检验的假设,即文本的价值取决于它的生产方式而非它的内容本身。一篇论证清晰、洞见深刻的文章,如果是AI写的就没有价值;一篇平庸的文章,只要是人写的就有价值。这种思维方式和颅相学的逻辑其实是同构的,它把认识论上的品质投射到了来源属性上。AIGC检测产业正是寄生在这种心理需求之上。
而那些坚持这条路线的国外玩家与国内AIGC参与者一样,将该产业视为一条有利可图且年增长率超过30%的黄金商路。它们的商业模式根本不依赖于检测是否真的有效,而是依赖于机构是否需要一个可以走流程的工具。高校需要一个系统来应对教育部的政策要求,期刊需要一个工具来对投稿进行形式审查。
这些需求都不要求检测在认识论上是可靠的,只要求它在行政流程上是可操作的(或者更直白地说,可推卸责任的)。只要高校的通知还写着论文须通过AIGC检测方可进入答辩环节,这些公司的收入就不会受影响。
更有意思的是,检测工具变得越来越激进,改写逃逸工具也变得越来越善于规避检测,检测工具再调整,循环不断。而被夹在中间的人面对的是一套越来越荒诞的激励结构。这已经催生出一个完整的降AI率产业链,从付费改写服务到自动降AIGC率的工具,价格从几元到几十元每千字不等。
换句话说,检测行业和反检测行业共同构成了一个寄生性的生态系统,两者互为存在的理由,而这整个生态系统对于判断一篇论文是否有学术价值这件事,贡献为零。
论文中心制的崩溃
统计学游戏的结束只是问题最表面的部分。这些游戏是以论文中心制的学术评价体系为基础,真正的问题是它们所维护的那个东西本身是否还站得住脚。
要回答这个问题,首先需要理解论文是如何成为学术体系中的硬通货。原因很简单,就是启蒙时代以来现代性对量化,或者说精确性无法摆脱的痴迷。落实到现代学术制度上,大学和科研机构需要一种可标准化、可量化的方式来衡量研究者的贡献。
论文恰好满足了这个需求。它有明确的形态规范,可以被写进简历和评审系统之中。整个学术体系的核心交易围绕它运转。你生产论文,体系给你学位、职称和经费。
但论文之所以能长期充当这种货币,并不是因为文本本身有什么内在价值,而是因为一种特定的成本结构在支撑着它。
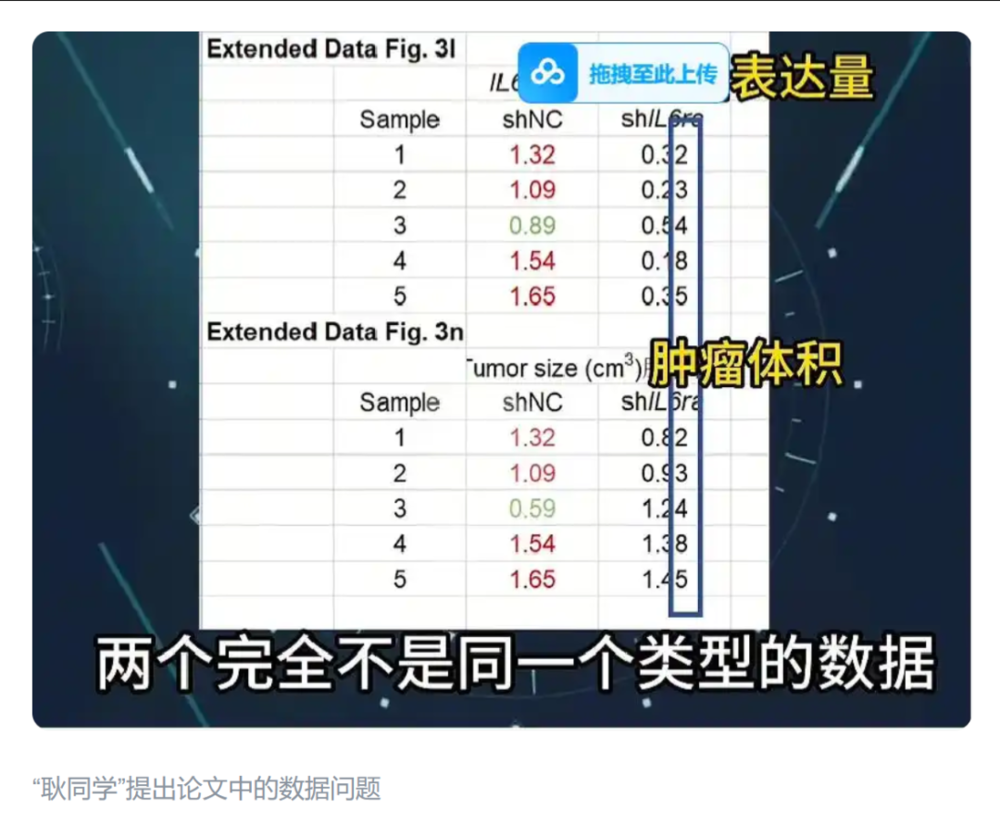
在过去很长一段时间里,写出一篇逻辑自洽且符合学科规范的学术论文本身就是一件困难的事情。而做研究虽然辛苦,却是达成这件事的最省力路径。并非不存在其他路径,造假需要足够的专业能力且面临被发现的风险,找人代写需要花钱且依赖人际信任,拼凑灌水虽然成本较低但产出质量也低。论文作为货币的信用,建立在“真的做研究”相对于所有替代路径具有综合成本优势这件事上。
笔者在之前的文章《德国废掉所有核电站的背后,是启蒙神话的崩塌》中曾经提到,科学权威的真正基础并不是科学结论的普遍有效性本身,而是建立在如何让人确信它是普遍有效的这一信任机制之上。从个人理性的验证,到实验的可重复性,再到因果性的关联解释,这条信任路径才是科学权威得以确立的根基。
论文在学术体系中扮演的角色,正是这条信任路径的制度化表达。一个生物学博士要写出一篇合格的实验论文,他最现实的路径就是老老实实地养细胞和统计数据。换言之,论文的价值从来不在于文本写得好不好,而在于文本背后存在一个不得不做研究才能写出来的约束条件。正是这个约束条件让论文成为了研究活动的可靠代理。
AI的破坏力之所以如此彻底,不是因为它降低了某一条替代路径的成本,而是因为它同时把几乎所有替代路径的成本都压到了接近于零。它既能帮你写出流畅的论文,又能帮你编造统计上合理的数据,还能帮你综述文献、构造论证、生成分析代码。当所有替代路径同时变得廉价时,“真的做研究”这件事就不再有任何成本优势了。
而且这种崩溃不仅发生在生产端,还发生在预期端。货币的信用不仅取决于实际的生产成本,还取决于人们对生产成本的共识预期。即使一篇论文确实是作者真刀真枪做出来的,在一个所有人都知道AI可以零成本生产论文的环境里,这篇论文也会被怀疑。
这就像真钞在伪钞泛滥的环境里也会被拒收。AI不仅改变了论文的实际生产成本,还摧毁了学术共同体对论文生产成本的共识信任。这种信任一旦丧失,即使个别论文是真实的,整个货币体系也无法运转了。AIGC检测本质上是在发明验钞机来应对这场通胀,但问题从来不在于伪钞太逼真,而在于论文这一“货币”本身已经丧失了它之所以能充当货币的那个基础。

值得一提的是,这种丧失在AI出现之前就已经有迹可循了。学术体系长期以来对论文数量和发表级别的过度依赖,早已催生了大量灌水论文、互相挂名引用等操作。这些操作严格来说都不是造假,甚至也不违反任何规定。但它们的实质是一样的,就是在不增加真实研究贡献的前提下增加论文产出,AI只是把这个长期累积的泡沫推向了不可维持的临界点。
那么能否换一种“货币”呢?放弃以文本产出为中心的评价方式,比如转向AI无法廉价模拟的能力维度。这在原理上是可以探索的,但不同学科面对的困境深度截然不同。
对实验科学来说,出路相对清晰。论文呈现的是实验结论,而实验本身发生在实验室里,有独立于文本的物质过程。如果评价的锚点从你写了什么转向你的数据能否被别人独立重现,那文本在评价体系中的权重就可以被大幅降低。强制要求开放原始数据、实验记录和分析代码,建立可独立验证的数据链条,这条路在技术上没有根本障碍。
人文学科面对的困境则要深刻得多。对哲学、文学、历史学这些学科来说,写作在很大程度上就是研究本身。论证的展开、概念的辨析、文本的细读、思想史脉络的梳理,这些活动发生在写作过程中而非写作之前。一个哲学家的学术贡献很难脱离他的文本来衡量,因为那个文本就是他的思考本身。当AI可以生成一篇论证严密、引用准确的哲学论文时,人文学科受到的冲击比有人代写了我的作业要深得多。它动摇的是文本写作即思想劳动这个根基。
不过人文学科也并非全无回旋余地。毕竟苏格拉底式的对话才是哲学最初的表达。我们可以设想这样的评价方式:一个哲学系的答辩不再要求学生提交一篇定稿的论文,而是考察学生与大模型的实时对话过程。你如何向AI提出一个有意义的哲学问题,如何在AI给出的回答中识别出隐含的预设,如何追问这些预设,如何在多个看似合理的论证路径中判断哪一个触及了真正的要害。这些能力不是AI能替你展示的,它们必须在交互过程中实时发生。
这是笔者想在接下来课程中尝试的方案,不再要求学生提交论文,而是要求学生根据笔者提出的问题在30轮AI对话后生成对问题的最终回应,并把这个对话流程提交给笔者。
到这里为止,事情似乎还是可以解决的。旧的评价工具失效了,但不管是实验科学的可重复验证,还是人文学科的对话能力考察,替代方案在原理上是可以被设计出来的。
然而真正困难的部分还没有出场。
科学共同体的黄昏
严格而言,第二部分结尾给出的替代方案本质上是一种乐观主义。这些方案都依赖一个共同的前提,就是存在某种可靠的外部检验机制。实验科学的可重复验证要求有人去做重复实验并诚实地报告结果。对话能力的评估要求有人来判定学生展现的思维质量是否达标。
但是,任何评价工具都需要由人来操作。而一旦追问由谁来操作这个问题,就会触碰到一个远比AI冲击更古老的结构性矛盾。以笔者自己的方案为例,笔者凭什么可量化的客观标准判断学生与AI对话的表现好坏?

这就回到了本文一开始所说的,即现代性对可量化的本质性痴迷。这种痴迷反映到科学方法论上,就落脚为对可重复的实验验证的追求。因为只有能被重复的东西才能被精确测量和比较。近代科学之所以区别于经院哲学和神学推理,最根本的一条就是它的结论原则上可以被任何人通过重复实验来检验。
从伽利略开始,科学权威的合法性就建立在个人理性验证的基础之上。将镜子放在太阳光下观察折射现象是小学生就能做到的实验。正是这种任何人都可以亲自验证的可及性,让科学区别于需要信仰才能接受的神学教条,也让科学共同体建立起了一种不依赖于个人权威的自我纠错能力。可重复性不只是一个技术标准,它是整个科学信任体系的认识论地基。
但三百多年过去了,这块地基正在从两个方向同时被侵蚀。
第一个方向是实验本身的复杂度。今天一项典型的生物医学实验涉及的特定细胞系、特定试剂批次、特定仪器参数和特定环境条件之间的组合,复杂到即使研究者完全诚实、开放了所有数据和流程,复现也是一件极度困难的事情。
很多领域事实上已经不存在常规意义上的重复实验,取而代之的是我相信你的实验室有能力做出这个结果。换言之,可重复性从一个可操作的检验程序退化为一种基于声誉的信任。
第二个方向则更为根本,笔者在之前的文章中将这个问题概括为科学的黑箱化。随着学科的不断分化和深化,前沿科学的复杂程度已经远远超出了任何个体的认知能力。让一个人掌握大型量子对撞机实验的操作和观察需要经年累月的专业训练,而这还仅仅是物理学的一个分支。
当科学在个体认知中彻底成为黑箱的时候,任何人都可以亲自验证这个启蒙时代的承诺就事实上破产了。绝大部分人根本无法判断一项科学结论是否正确,因为他们可能连充分理解这项结论都做不到。科学的可重复性变成了一种理论上的可能性,而非实践中的现实。于是科学信任的基础就悄然从我可以验证滑向了我选择相信。
这两个方向交汇之后,就产生了一个严峻的组织问题。现代科学的发展必然导向学科的高度分化,知识积累到一定深度后,没有人能掌握整个领域,研究者只能在越来越窄的方向上深耕。这是现代科学的内在逻辑,不以任何人的意志为转移。
但分化推进到足够细的程度之后,每一个细分方向都小到了全世界只有二三十个实验室在做的地步。这些实验室的负责人互相审稿、互相评基金、互相引用、在同一批会议上碰面、甚至共享学生和博士后。
于是一个结构性的悖论出现了。同行评议的设计理念要求评价者同时满足两个条件,既具备足够的专业能力来理解被评价的工作,又与被评价者没有利益关联。但在一个足够小的细分领域里,这两个条件是互相排斥的,能看懂你工作的人恰恰就是和你存在合作、师承和经费利害关系的那批人。
由此产生的不是哪个人的道德失败,而是一种结构性的相互纵容。我审你的论文,发现数据可疑,但如果我较真,我的论文将来也会落在你或你的熟人手里。我质疑你的基础性发现,那建立在你工作之上的我自己的研究也会跟着动摇。这个方向出了丑闻,整个领域的经费都要缩水。所以理性的选择就是不看太仔细,提几条无关痛痒的修改意见,放过去。
这是博弈论意义上的纳什均衡,不需要任何密谋,不需要任何人有意腐败,系统自身就会稳定地运转在质量控制全面空转的状态上。
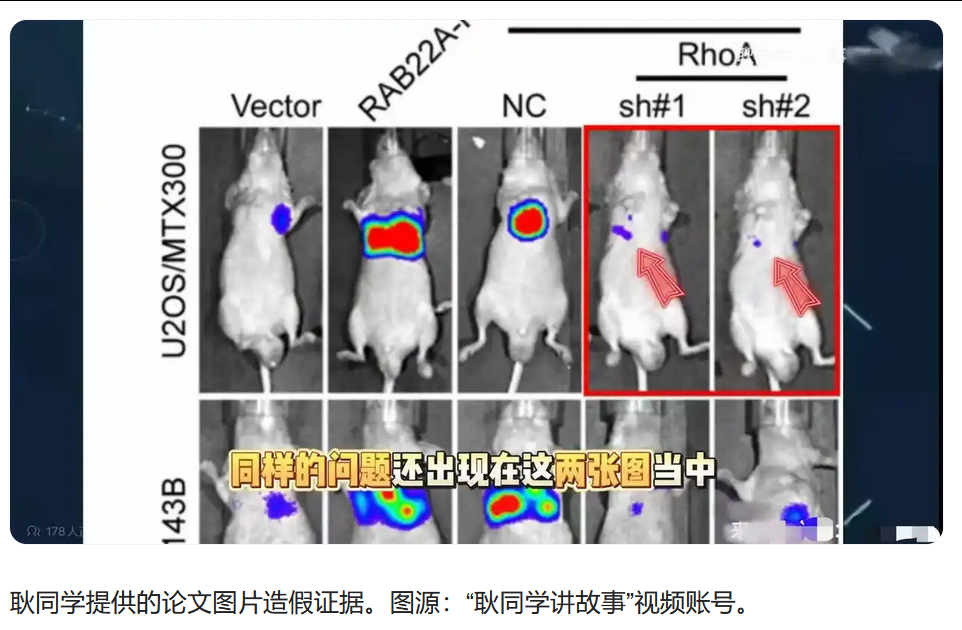
这种结构性纵容并非抽象的理论推演。哈佛大学教授安韦萨31篇论文造假就是一个非常现实的例子。他以心肌干细胞的开创性创造了一个细分学术领域,养活了无数相关研究者和利益团体。直到17年后,神话才变成了造假。
这才是耿同学事件最深层的意义所在。那些发表在Lancet、Nature、Cell上数以百计的文章难道真得没有人觉得不对劲么?那么多实验室和利益团体难道没发现实验很难复现么?不是没有人能看到,而是没有人有足够的动力去看到。毕竟大家都要靠这个细分领域吃饭,打碎饭碗的做法对谁都没有好处。我国国自然基金中大量关于该造假领域的研究就是一个颇具讽刺意味的事实。
在这一意义上,第二部分的方案只能用乐观主义来形容了。它们全都回避了同一个问题,就是谁来检查那些开放的数据是否真实,谁来判定一次对话中展现的思维质量是否达标,谁来做那个重复实验。如果负责判定的依然是那几十个互相认识的人,那新的评价方式会以和旧方式完全相同的路径走向空转。
工具可以换,但操作工具的社会结构没有换。开放数据的制度可以被形式化地执行但实质性地架空,对话评价可以被人情关系柔化为走过场,就像同行评议曾经被柔化为社交仪式一样。
有些人可能会想到一个看似合理的出路,既然问题出在人类评审者的利益纠葛上,那为什么不让AI来充当没有利益关联的外部审查者呢?
但这条路通向的不是问题的解决,而是一个更深的深渊。如果我们把验证的权力交给AI,本质上是用一个黑箱去审查另一个黑箱。而且第二个黑箱比第一个更加不可穿透。
前沿科学虽然复杂,但原则上一个人经过足够的训练仍然可以理解它。大语言模型的决策过程则连它的开发者都无法完全解释。把知识的裁判权交给一个其运作机制本身就不透明的系统,这不是在修复科学的信任危机,而是在信任危机之上又叠加了一层更根本的不可理解性。
更关键的是,这种让渡一旦发生,改变的就不仅仅是谁来审查的问题了。科学之所以是科学而不是神谕,恰恰在于它的结论是通过人类理性的公开辩论和可检验的共识来确认的。这是启蒙运动留给科学最核心的遗产。如果把确认权交给一个人类无法理解其推理过程的算法,那科学在认识论上就和神谕没有本质区别了,只不过神从超自然的上帝变成了超认知的算法。
借用霍布斯的理论说,人类为了摆脱同行评议的自然状态,自愿将裁判权让渡给一个技术利维坦。但与霍布斯的社会契约不同,这里的让渡没有任何约束机制,因为我们甚至无法理解这个利维坦是依据什么在做出判断。这不再是同行评议是否空转的问题,而是人类在知识生产中全面让渡裁判权的例外状态。
启蒙要求理性化,理性化呼唤专门化,专门化产生黑箱化,黑箱化瓦解了人类的验证能力,验证能力的丧失要求一个超越人类认知局限的裁判者,而这个裁判者的不可理解性恰恰复现了启蒙最初试图推翻的那种神学结构。
每一步都是前一步的逻辑必然。科学追求客观性追求到了极致,就必然要排除一切主观因素。而以个体经验为基础的人类理性本身就是最大的“主观因素”。与其说科学变成了新神学,不如说启蒙从一开始就内含着重新走向神学的辩证结构。
这不是科学的病态,这是科学的生长方式内含的悖论。AI没有从外部制造这个悖论,它本身就是这个悖论展开的最终形态。它是启蒙逻辑最忠实的执行者,也正因为如此,它成为了启蒙逻辑自我否定的完成。
那些在统计表面上寻找造假痕迹和AI痕迹的努力终将归于无效,而即使我们找到了更好的评价工具,那个让一切评价工具最终走向空转的结构性力量依然在那里。它内嵌在现代科学自身的组织方式中,或者更准确地说,它内嵌在启蒙理性自身的运动方式中。
阿多诺的时代没有AI,但AI正在成为启蒙辩证法的自我预言。