
本文来自微信公众号: ToBeSaaS ,作者:戴珂
复盘去年参与的企业AI项目,有的勉强验收,有的至今还没完全交付。先不说效果好坏,很多项目从启动之初就推进不下去。
直到看到MIT做的生成式AI企业落地调研数据,心里多少有些释然:全球95%的企业AI项目,都止步于单场景演示,始终无法落地到企业生产环境,换个说法,其实就是失败了。
以往项目复盘会上,大家总把项目不及预期,要么归咎于大模型能力不行,要么是企业数据质量糟糕。但结合这一年大量AI实施后我发现,二者都并非核心症结。造成绝大多数项目折戟的根本元凶,其实是企业组织层面的上下文(context)体系缺失问题。
这就导致短期演示还行,一旦投入实际运行,诸如AI幻觉、决策失真、业务跑崩、合规失控等问题都会冒出来。
现在问题已经十分清楚:企业上下文体系缺失,是绝大多数企业AI落地失败的首要诱因。
换而言之,在全域企业上下文体系梳理、搭建完备之前,根本就不应该启动项目。
01
认知纠偏:大模型能力没那么重要
这个观点可能会让人觉得反常识。
很多企业做AI落地,都带着很深的思维惯性和认知偏差:只要AI输出达不到预期,第一时间就觉得是模型选得不好。不少企业大手笔采购顶尖大模型、扩建算力集群,不在乎高额Token开销,把AI优先当成企业头号战略,但最后AI试点还是走不上生产,前期投入没法产生业务收益。
事实上,这套落地思路存在本质缺陷:通用大模型仅具备公共通识,完全不掌握企业独有的内部业务信息——企业专属业务术语、指标统计口径、多系统数据流转链路、历史业务特殊处理规则、分级数据访问权限,全都属于大模型预训练阶段无法触达的私有上下文。
即便选用业界顶尖基座模型,若缺少企业专属业务背景作为输入素材,AI只能依托通用常识主观推演业务事实,生成的文本表面逻辑通顺,却不具备实际落地价值。
拿法律行业举例:办案仅依靠公开法条,缺少海量同类判例作为支撑,根本无法打赢案件。
在我看来,当下行业落地手段都属于临时补救方案:人工撰写静态提示词、团队各自搭建数据上下文、无上限扩充上下文窗口。但这类手段仅能完成单场景短期演示,即便客户走完验收流程,从规模化生产落地的角度看,项目本质仍是失败的。
从大量落地项目中总结出核心教训:大模型仅仅是推理计算工具,一套完整、合规可管控的企业上下文体系,才是AI输出可信业务结论的底层根基。
02
核心框架:四层全域上下文完整架构
事实上,行业早已意识到上下文建设的重要性,只是目前多停留在数据层面,虽有效果,但远远不够。
事实上,真正能够支撑企业可信AI稳定运行,或者说一个Agent要想正常运行起来,需要四个层面的下文架构支持。
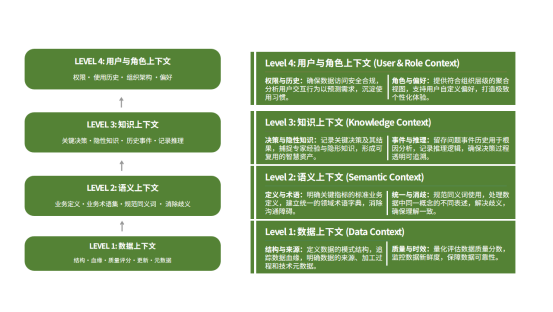
四层上下文体系缺一不可、自下而上层层递进,每一层都会叠加、放大整体业务价值。缺失任意一层,都会造成不可逆的落地缺陷,这也是绝大多数企业AI项目失败的共性短板。
第一层为【数据上下文】,是整个体系的技术底座,核心包含数据表结构、数据血缘、数据质量评分、数据新鲜度与全量技术元数据。
其中数据血缘记录数据从原始采集、ETL加工、指标聚合到下游AI调用的完整字段级流转链路,是AI读懂数字来源的基础。
当前多数企业仅完成这一层基础搭建,但仅靠技术元数据,AI只能识别数据表字段,无法理解数字对应的真实业务含义,可能出现调取过期数据、关联错误字段等技术层面失误。比如,企业存在实时流水营收表、月末结算营收表,如果AI无完整血缘信息,可能会错调取临时流水数据做月度经营分析。
构建数据上下文的最大难点在于数据来源问题,绝大多数业务数据无法直接从底层数据库提取,需要对接内外部各类SaaS系统API采集数据,但企业往往不具备条件。
第二层为【语义上下文】,用于消解跨部门、跨系统的术语歧义,包含统一业务定义、行业术语词典、同义词映射与歧义消解规则。
缺少业务语义上下文的AI,无法自动区分指标口径,即便数据计算逻辑完全正确,最终分析结论也会误导决策。
企业内部普遍存在“同名不同义”问题,比如SaaS订阅业务的“收入”,指的是第四季度已确认的收入,而不是总签约金额。“客户”指的是的付费账户,不包括试用注册用户。
第三层为【知识上下文】,承载企业没有记录的公司内部隐性知识,涵盖历史业务决策、例外规则、未成文的决策逻辑。
通用大模型无法获取企业多年沉淀的实操经验,而缺失该层上下文的AI,只会机械套用公开的规则和标准,忽略特殊业务场景约束,输出脱离企业实际的“标准化”方案,给出技术上正确,但组织上错误的答案。比如,金融行业风控方案,除了依据常规风控指标外,更有效的可能是更多内部特征。
第四层为【用户与角色上下文】,是合规风控的顶层屏障,包含数据访问权限、用户操作历史、企业组织架构、个性化使用偏好。
该层根据使用者身份动态裁剪上下文可见范围,比如向普通员工屏蔽财务、客户涉密数据,同时留存全链路审计日志。
缺少角色上下文的AI存在重大合规隐患,极易向无权限人员泄露隐私与涉密信息,违反监管法规。比如,一个AI客服泄露了客户的隐私,因为客服Agent根本不知道是谁在问这个问题。
四层上下文形成完整闭环:仅有数据上下文,AI只有死的数据;叠加语义上下文,可统一业务口径;补充知识上下文,AI拥有成熟业务判断力;四层全部完备,才能实现数据可信、口径统一、经验完整、权限合规的AI业务推理。
03
底层认知:上下文是企业数字化基础设施
印象很深,此前跟进过一个AI落地项目,启动前各业务线、技术团队都分别搭建了自身场景下基本完整的上下文体系。财务团队梳理了营收核算相关数据与术语,销售团队搭建了客户跟进配套上下文,产研、风控也各自完成了对应模块整理。
但这套分散建设的方案很快暴露出致命问题:所有上下文都是各团队闭门独立搭建,没有统一标准、没有互通校验。当我们把多套上下文整合到统一的企业全局视图中才发现,各模块内容互相割裂,指标定义、统计口径、数据范围完全无法对齐,彼此之间没有兼容联动的逻辑。
拆分来看,单条业务线、单个独立场景运行时,依托本团队自建的上下文,AI输出结果尚且通顺合理,交付演示时看不出明显问题,甚至能顺利通过阶段性验收。可一旦需要打通跨部门业务、做企业全域综合分析,多套冲突上下文叠加后,AI的计算与判断标准彻底混乱,输出结论互相矛盾、南辕北辙,各类逻辑漏洞、统计错误集中爆发,完全不可用。
这也是大量项目看似演示效果亮眼,最终却无法投产落地的典型假象:局部上下文完整不等于企业全域上下文体系成立,分散、孤立的场景化自建模式,解决不了组织级AI规模化落地的核心矛盾。
事实上,企业上下文不能只是零散的文档、数据定义和规则清单,更不能交由各业务团队各自为政搭建。它应当和算力、存储、云平台一样,被定位为企业数字化核心基建,我们称之为Context Infrastructure(上下文设施)。
如同网络、服务器这类公共基础设施,上下文设施具备统一标准、全局统一维护、全部门共享复用的属性。它不属于某一个业务、某一个项目,而是企业全体AI应用共用的底层支撑底座。
只有自上而下统一规划、统一治理、统一更新四层完整上下文架构,才能从根源规避多套口径冲突、信息割裂的落地陷阱,让AI跨部门、全流程稳定可信运行。
04
落地破局:全域上下文设施建设四步法
想要跳出行业95%的AI落地失败困局,企业必须彻底扭转固有思路:放弃以模型选型、调优为核心的建设路线,优先搭建包含四层架构的全域上下文基础设施。
整套落地路径分为四大关键动作,层层递进:
1.统一资产底座,打通四层上下文
将企业上下文定义为全公司共享的核心数字资产,搭建全局统一的上下文图谱,串联数据、语义、知识、组织四层上下文,消除各部门信息孤岛与口径冲突。
2.自动化动态运维,解决上下文老化问题
配套全链路自动更新机制,数据表迭代、业务规则调整、指标口径变更均可实时同步,避免静态上下文滞后失效。
3.标准化统一分发,赋能全量AI应用
基于标准化MCP协议,对内所有AI应用统一输出可管控、携带完整溯源信息的上下文素材,实现一次建设、全域复用。
4.前置合规治理,满足监管要求
提前搭建分级访问权限、全流程操作审计体系,从源头管控数据使用边界,适配各类行业与跨境合规规则。
写在最后
很多企业始终困在“重模型、轻底座”的AI建设误区,一味追逐性能更强的大模型,却忽视了支撑AI稳定可信运行的上下文基础设施。
算力与基座模型仅仅是推理工具,一套统一治理、四层架构完备的全域上下文,才是企业AI规模化落地的核心护城河。
跳出单场景演示带来的虚假成功,自上而下搭建标准化Context Infrastructure,依靠完整四层上下文打通数据、业务规则、隐性经验与权限管控,才能彻底打破95%项目无法投产的行业魔咒,让AI不再局限于短期演示,真正转化为持续创造经营价值的数字化长期资产。