
本文来自微信公众号: AI超维度 ,作者:北京汉·索罗
2026年5月,Cerebras在纳斯达克上市,市值一度冲到600亿美元。这是2019年以来美国最大的科技IPO。
上市当天,CEO Andrew Feldman举起那颗餐盘大小的芯片,照片传遍了科技媒体。一颗普通芯片只有指甲盖那么大,英伟达最强的GPU也不过巴掌大小。Cerebras的芯片占满了一整片硅晶圆,面积是英伟达最大GPU的56倍。
这颗芯片从构想到上市花了十年。其中有三年,做它的公司每月烧800万美元,每隔几周去董事会汇报,总是失败而归。
疯狂的想法:不切晶圆
Feldman在硅谷创业圈不算新人。他之前创办过一家叫SeaMicro的服务器公司,2012年被AMD以3.34亿美元收购。他和四个核心搭档在AMD待了两年就出来了,2016年重新聚到一起,开始琢磨一个更大的问题。
当时AI芯片行业的主角是GPU。GPU原本是给游戏做图形渲染的,后来被发现碰巧很擅长做AI需要的大规模并行计算,英伟达借此拿下了市场。但Feldman的判断是:GPU虽然算得快,但数据搬运效率很低。一台AI服务器里有几千颗小芯片,数据在芯片之间不停搬家,每搬一次就消耗功耗、增加延迟。在他看来,芯片算得再快,数据搬不过来也白搭。
如果数据搬运是瓶颈,能不能从根源上消灭搬运?
Feldman的解决方案在当时听起来接近疯狂:直接把一整片晶圆变成一颗巨大的芯片。
这里需要解释一下大部分芯片是怎么造出来的。做芯片的起点是一片圆形的硅晶圆,它就像一张光滑的银色圆盘,直径30厘米,和餐盘差不多大小。工厂在这片晶圆上用光刻机反复印刷同一个电路图案,每印一次覆盖指甲盖到巴掌之间的面积,整片晶圆上能印几十次。印完之后,沿着图案之间的缝隙把晶圆切开,一片晶圆就变成几十颗独立的芯片——和用模具在一大张面皮上压出饼干,道理完全一样。英伟达的GPU、苹果的手机芯片、高通的通信芯片,全世界几乎所有芯片都是这么造出来的。
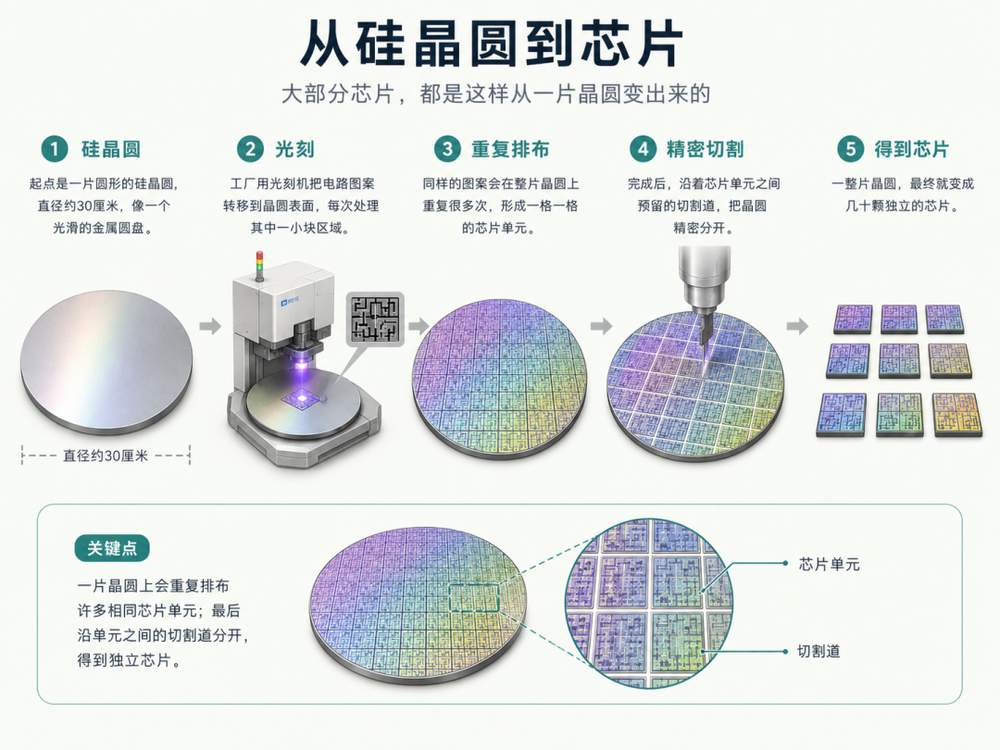
图片由AI生成,芯片制作过程
Cerebras想做的事情是:不把晶圆切开。84次印刷的图案不再各自独立,而是通过印刷区域之间的缝隙彼此连线,拼成一整颗巨大的芯片。一张面皮不压饼干,整张就是产品。这样一来,数据在芯片内部流动时,永远不需要离开硅片——不用通过外部线路跳到另一颗芯片上,不用排队等互联带宽。
搬运的问题,从物理上消失了。
烧掉两亿美元
想法有了,但要把一整片晶圆变成一颗能工作的芯片,每一步都没有先例。
首先是良率。光刻机每次只能印大约3厘米见方的图案,这也是全世界最大的芯片不过巴掌大小的原因。芯片面积越大,碰到制造缺陷的概率就越高。Cerebras的芯片是这个上限面积的54倍,按常规概率,不可能有一片晶圆完全没有缺陷。他们用冗余来解决:芯片上刻97万个核心但只启用90万个,每批晶圆单独定制一套金属层模版绕过那一批特有的缺陷,换来接近100%的良率。
然后是散热。25千瓦的功耗集中在21.5厘米见方的硅片上,风冷远远不够,蒸汽腔散热器又因为尺寸过大会失效。他们从零设计了一套全定制液冷系统:冷板、晶圆、柔性连接器、PCB四层叠在一起,冷却液要求21°C入水,数据中心需要配6000吨级冷水机组。
还有供电。84个定制的Vicor电源模块,50伏→12伏→1伏逐级转换,把超过两万瓦的电力精确送到一片硅上。他们甚至发明了一台能同时拧40颗螺丝而不碎裂晶圆的组装工具。
2016年拿了A轮2700万美元之后,Cerebras从公众视野里消失了三年。到2019年年中,累计烧掉了将近2亿美元。
2019年7月的一天,芯片跑通了。五个创始人站在实验室里看指示灯闪烁。Feldman后来跟TechCrunch说:"看电脑跑程序和看油漆干一样无聊。但我们五个人一动不动站在那里。那是我人生中最伟大的时刻之一。"
一个月后,斯坦福大学召开Hot Chips大会。Cerebras揭开了第一代晶圆级芯片WSE-1:1.2万亿个晶体管,40万个AI核心,覆盖一整片晶圆。现场没有人在过去见过这种东西。
无人问津的孤岛
从WSE-1到现在,Cerebras的芯片迭代了三代。最新的WSE-3由台积电5nm工艺制造,4万亿个晶体管,90万个AI核心。但决定这颗芯片命运的不是算力有多大,而是一个设计决策带来的一对矛盾。
WSE-3把芯片面积的一半给了一种叫SRAM的高速存储——一共44GB,直接刻在计算核心旁边。和GPU使用的外挂HBM内存不同,SRAM的数据不需要离开芯片就能被读取,片上带宽达到21PB/s,是GPU HBM带宽的大约一千倍。AI推理在生成回答时(即上一篇提到的decode阶段),每吐出一个Token都要把模型权重从内存完整读一遍。英伟达的GPU要去芯片外面的HBM搬数据,而Cerebras的WSE不用搬,因为数据就在旁边。而且,通道一下从四车道变成四千车道。
这就是Cerebras能做到每秒生成一千个Token的原因。
但44GB是个天花板。44GB的片上存储在芯片行业已经是巨量,普通芯片按百兆字节算。可它和GPU的外挂HBM一比就不够看了:英伟达最新的Rubin GPU单卡288GB,是一整片WSE-3的6.5倍。大模型动辄几千亿甚至上万亿参数,再加上长上下文需要的存储空间,44GB根本装不下。如果模型太大,就得把模型切成多片、分到多片晶圆上做流水线。但WSE和外界通信的总带宽只有150GB/s,不到英伟达单颗GPU互联带宽的六分之一。每多一片晶圆就多一个瓶颈,速度优势随之缩水。
为什么对外带宽这么低?这不是工程师忘了加接口,而是晶圆级架构的几何代价。前面说过,光刻机在晶圆上印刷84次,每次图案必须完全一样,相邻区域才能无缝拼接。如果想在晶圆边缘加装高速数据接口,就得在每次印刷的图案里都加上接口电路。但84个区域里只有最外圈的十几个能真正连到外面的世界,中间几十个区域被邻居团团围住,接口电路造了也接不出去,硅面积浪费了,芯片内部的数据通路还被打出一个个洞。让晶圆级芯片成为可能的均匀印刷方式,恰恰是让对外通信极难扩展的原因。这不是工程问题,是几何必然。
还有一个更长期的限制。SRAM的面积不再随芯片制程进步而缩小。WSE-1用16nm工艺,18GB SRAM。WSE-2升级到7nm,SRAM跳到40GB,增长2.2倍。但WSE-3到了5nm,44GB,只比上一代多了10%。这不是Cerebras的问题,是整个行业的趋势:台积电的3nm工艺在SRAM面积上相比5nm零缩减。Cerebras的下一代系统CS-4仍然用同一块WSE-3芯片,SRAM锁死在44GB。
内部极快,对外极窄,容量到顶。这颗餐盘大的芯片被困在一座孤岛上——速度优势真实存在,但受到物理定律的硬约束。大多数分析把这些局限当作"有待解决的工程挑战",但SRAM缩放停滞是整个半导体产业的物理趋势,I/O瓶颈是晶圆级架构的几何必然,都不是换个更先进的制程就能解决的事情。这颗芯片已经接近它的结构性天花板。
那么Cerebras的命运取决于什么?不是自己的芯片能不能变好——而是别人的模型能不能变小。
这个问题在2019年没有人在乎。
从WSE-1亮相到2024年,整整五年,AI行业的全部注意力都在训练上:谁的模型更大、谁的算力更猛。英伟达的GPU为训练而生,拿下了超过八成的市场。用户在ChatGPT的对话框里等两秒钟也不会抱怨。推理快不快,没有人在乎。
Cerebras拿着一颗只擅长推理的巨型芯片,敲不开大门。唯一的大客户是G42,一家阿布扎比的AI公司,2024年上半年贡献了Cerebras总收入的近九成。2024年9月,Cerebras第一次提交IPO申请,G42的阿联酋背景触发了CFIUS(美国外国投资委员会)审查,审查遥遥无期。2025年10月,Cerebras正式撤回上市申请。
一个细节值得记住:大约2017年,OpenAI曾讨论过收购Cerebras,Feldman后来对TechCrunch承认了这件事。据报道Elon Musk在2018年也试过。Feldman两次都说了不。
推理速度开始值钱了
变化发生在2025年下半年。变的不是技术,是用户行为。
Claude Code和一批Agentic AI工具进入了开发者的日常工作流。Agent不是陪用户聊天,它要反复调用模型、实时生成、即时反馈,对推理延迟的敏感度比普通对话高出一个量级。Anthropic推出了Opus 4.6的fast模式:6倍价格,2.5倍速度。到2026年4月,半导体研究机构SemiAnalysis发现自己80%的AI开支——年化峰值1000万美元——砸在了fast模式上。更能说明问题的是:当更聪明的Opus 4.7发布时,他们的工程师拒绝切换,唯一的理由是Opus 4.7没有fast模式。
AI行业从未出现过这种事。开发者主动留在一个更笨的模型上,只因为它更快。
推理速度变值钱了。Cerebras那座孤岛,突然有人想起来了。
2025年12月25日,英伟达花200亿美元签下Groq的技术和核心团队,三周后,2026年1月14日,OpenAI和Cerebras签下超过100亿美元的推理算力合同。全球最大的GPU公司和全球最大的AI模型公司,几乎在同一时间做了同一个判断:GPU自己搞不定推理,需要另一种芯片。英伟达把Groq吸收进了自己的体系。OpenAI选择在英伟达的体系之外下注。
2月12日,第一个成果落地。OpenAI发布了GPT-5.3-Codex-Spark,这是OpenAI第一个不跑在英伟达芯片上的生产模型,运行在Cerebras的WSE-3上,每用户每秒超过1000个Token。
但这里有一个容易被忽略的事实。Codex-Spark的每秒1000 Token,是在一个1200亿参数的蒸馏模型上实现的,它不是真正的GPT-5.3-Codex(万亿参数级),而是后者的十分之一大小,用大模型的输出蒸馏训练而成。正是因为模型小到能装进WSE-3的44GB SRAM,速度才能拉到这个水平。换句话说,Cerebras的速度优势有一个前提条件:模型必须足够小。
这是很多人对Cerebras的误解所在:看到"每秒1000 Token"就觉得它比GPU快了几十倍,实际上这个速度只存在于一个精心选择的模型规模区间。Cerebras的孤岛容不下巨兽,但如果你愿意带一个身形更小的模型登岛,它能跑得比任何地方都快。
OpenAI的赌注就藏在这个取舍里:不追求在最大模型上跑得稍微快一点,而是蒸馏出一个小得多的模型,然后在速度上拉开一个数量级的差距。用智力换速度,用蒸馏换延迟。赌的是在足够多的场景里,够聪明加上极快,胜过最聪明但更慢。
今年3月,AWS宣布多年合作:Trainium芯片做prefill,WSE-3做decode,通过Amazon Bedrock对外提供服务。5月,Cerebras上市。从撤回IPO到市值600亿,只花了七个月。
三条线都绑定在Open AI上
支撑这个翻盘的不只是技术。是一笔把Cerebras和OpenAI深度绑定的交易。
合同条款在Cerebras的上市招股书(S-1)里写得很清楚:750兆瓦推理算力,2026到2028年分批部署,每批合同期3-4年、可延至5年。OpenAI另有选择权加购1.25吉瓦,总潜力达到2吉瓦。截至2025年底,Cerebras披露的剩余履约义务为246亿美元。
但OpenAI对于Cerebras来说,角色远不止是客户。
它同时提供了10亿美元的担保贷款,年息6%——如果Cerebras以算力交付来偿还可以免息,但合同一旦终止则全额立即到期。OpenAI还保留了指示托管银行直接控制这笔资金用途的权利。
它还拿到了3345万股认股权证,行权价每股0.00001美元——约等于白送。完全摊薄后OpenAI可持有Cerebras 12%的股份。Sam Altman本人还是Cerebras的早期投资人。
债权、股权、收入管道——三条线都绑在Open AI上。
市场对Cerebras最常见的风险提示是"客户集中度高"。这个说法轻描淡写了。客户集中度高意味着你丢掉一个大客户会很疼。Cerebras面对的,是它的贷款方、最大潜在股东和几乎唯一的收入来源是同一个实体,三条线同向,没有任何对冲。这不是"集中",是一体。2017年OpenAI想收购没收购成的公司,九年后用另一种方式实现了绑定。
还有交付的压力。OpenAI合同要求2026到2028年每年部署250兆瓦的推理算力。Cerebras到2026年底的自有租赁产能可能只有约43兆瓦,缺口巨大。2027年贝尔AI园区的128兆瓦上线会改善局面,但圭亚那的100兆瓦项目已经多次延期。数据中心建设成本由OpenAI承担,Cerebras被允许支付高达200美元/千瓦/月——远超市场均价的130-140美元。但WSE-3对液冷的要求非标准化——每千瓦冷却液流量是英伟达参考设计的近3倍,普通液冷机房不能直接用。
设计芯片、造系统、写软件、卖推理、建数据中心,Cerebras同时在做五件事。而2028年前要交付的服务器总量,比这家公司成立以来所有出货量之和还要多出一个数量级。
英伟达花200亿美元把推理速度买进了自己的体系。OpenAI则花了超过200亿美元把速度买到了英伟达体系之外。同一个底层判断的两个方向:过了某个智能阈值,开发者宁愿要更快的Token,也不要更聪明的Token,而且愿意为此支付六倍的价钱。
Cerebras的600亿市值,行业押的是九个字:蒸馏会比摩尔定律跑得更快。
摩尔定律已经在SRAM上停转了:5nm到3nm,存储密度零增长,44GB就是天花板。但蒸馏没有停。1200亿参数的模型今天还不够聪明,可能一年之内就追上今天万亿参数前沿模型的水平。如果蒸馏够快,44GB的孤岛就是推理时代最有价值的基础设施——模型越蒸越小,芯片越跑越快,速度本身成为产品。如果蒸馏不够快,44GB和150GB/s就是物理定律画下的永久边界,速度再快也困在一颗装不下主流工作负载的芯片上。
这是整个AI芯片行业在2026年做出的最大一笔对赌。答案可能一年之内就会揭晓。