
本文来自微信公众号: APPSO ,作者:发现明日产品的,原文标题:《全网爆火的 Claude Fable 5 神级案例,可能是纯手搓》
短短24小时里,社交平台几乎被各种案例淹没。视频一个接一个冒出来,我们还没看完上一个,时间线又跳出一个由Fable 5制作的新案例,网友们玩得不亦乐乎。
甚至就在刚刚,《华尔街日报》报道称,OpenAI正在考虑大幅下调token价格,试图通过打起价格战从Anthropic手里争夺用户。
只是,热度一上来,各种串子发布的假案例也跟着混了进来。有人把旧视频包装成Fable 5的新案例,蹭热点打广告;也有人故意发纯手搓视频,讽刺网友对AGI的盲目追捧。
与此同时,用户很快发现,Fable 5的安全分类器实在是太敏感了,话题一旦涉及生物、化学、网络安全,模型就可能直接回退到Opus 4.8。有网友称,自己的资料里带有生物医学背景后,连一句Hi都可能触发回退。
Claude Fable 5一夜爆火,但网友已经开始分不清案例真假
Fable 5第一批出圈案例,大多和3D、物理、游戏、浏览器交互有关。
有X用户只给Claude 5 Fable high一个目标:「制作一个我的世界克隆版」。大约20分钟后,它生成了一个包含多个生物群落、昼夜变化、不同矿石和洞穴系统的版本。它还远谈不上真正替代游戏开发团队,但已经比过去那种「按钮加贴图」的AI小游戏复杂得多。

🔗https://x.com/ChrissGPT/status/2064441716908703780
自打Gemini 3.0发布之后,用AI打造克隆Windows系统已经不算稀奇,但Fable 5完成度之高,还是令人震撼不已:登录界面、通知、Edge、纸牌游戏,Copilot一应俱全,充分展现了Vibe Coding指哪打哪的魅力。

🔗https://x.com/intheworldofai/status/2064516713597501471
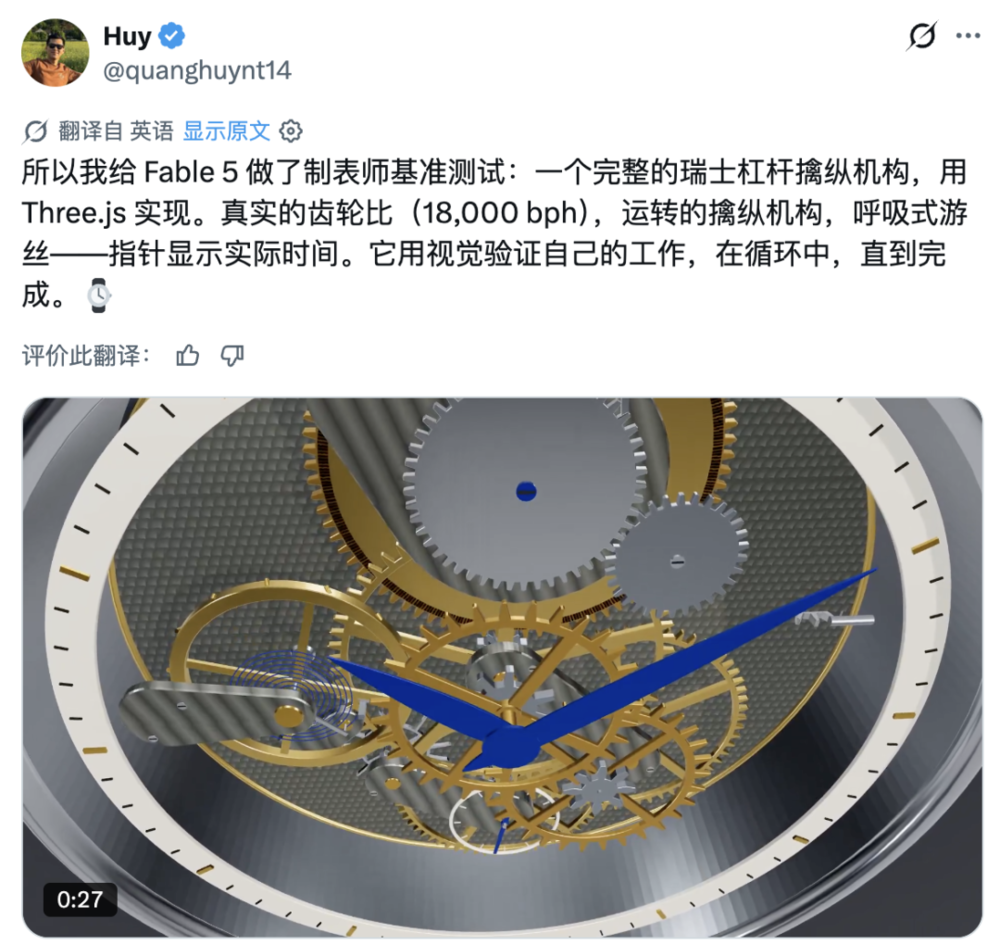
机械和工程案例的表现也没拉胯,让它用Three.js实现完整瑞士杠杆擒纵机构。成品包含真实齿轮比、运转中的擒纵机构、呼吸式游丝和显示实际时间的指针。呐呐呐,这看了谁不迷糊。
类似的还有街区模拟器。Bilawal Sidhu让Fable 5做了一个包含多Agent交通、实时检测框、轨迹和昼夜循环的城市街区。它不是成熟交通仿真软件,但它把「城市、多主体、轨迹、识别框、昼夜变化」这些元素组织成了一个能看的原型。

🔗https://x.com/bilawalsidhu/status/2064524211914223867
要说更夸张的案例,还得是让Fable 5设计人形机器人。
提示词非常简单,让它设计一个紧凑、轻量、类似现代高机动研究机器人的人形平台,带有25到30个自由度、外露关节、铝合金或复合结构,以及带传感器的头部。
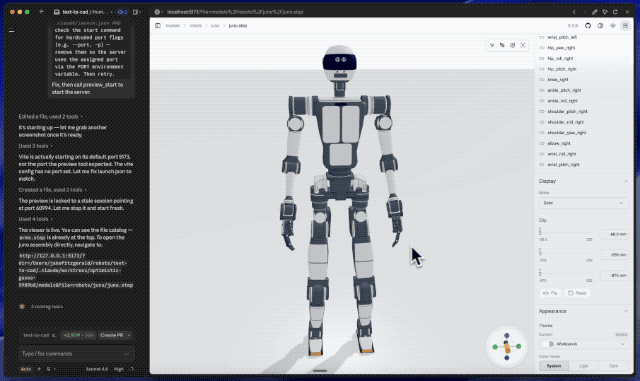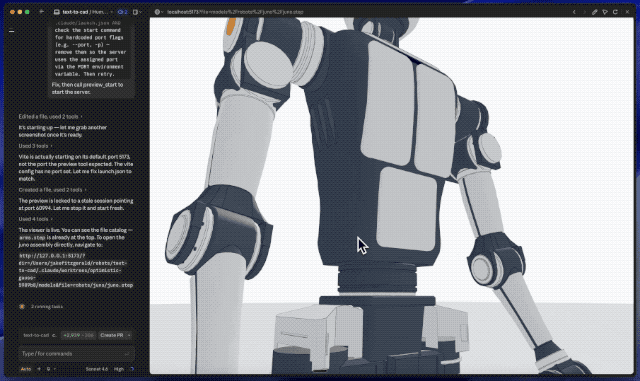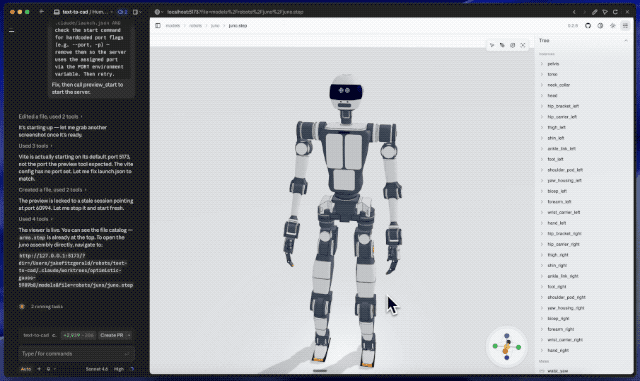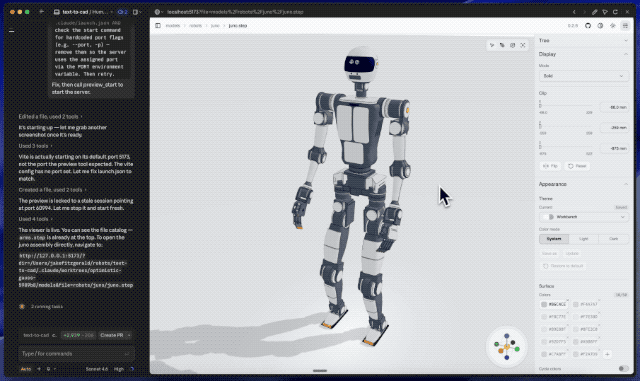
就这,仅仅用了两个小时、消耗约140万token后,Fable 5就甩出了一版完整草稿。换句话说,很多过去要开几次会才能讲清楚的想法,现在可能先由模型做成一个能看的版本。
是的,Fable 5自己不一定能生成最好的视觉素材,但它很擅长把素材、规则和交互组织成产品。而这种路径,反而比一句话全交给AI更接近生产实际。
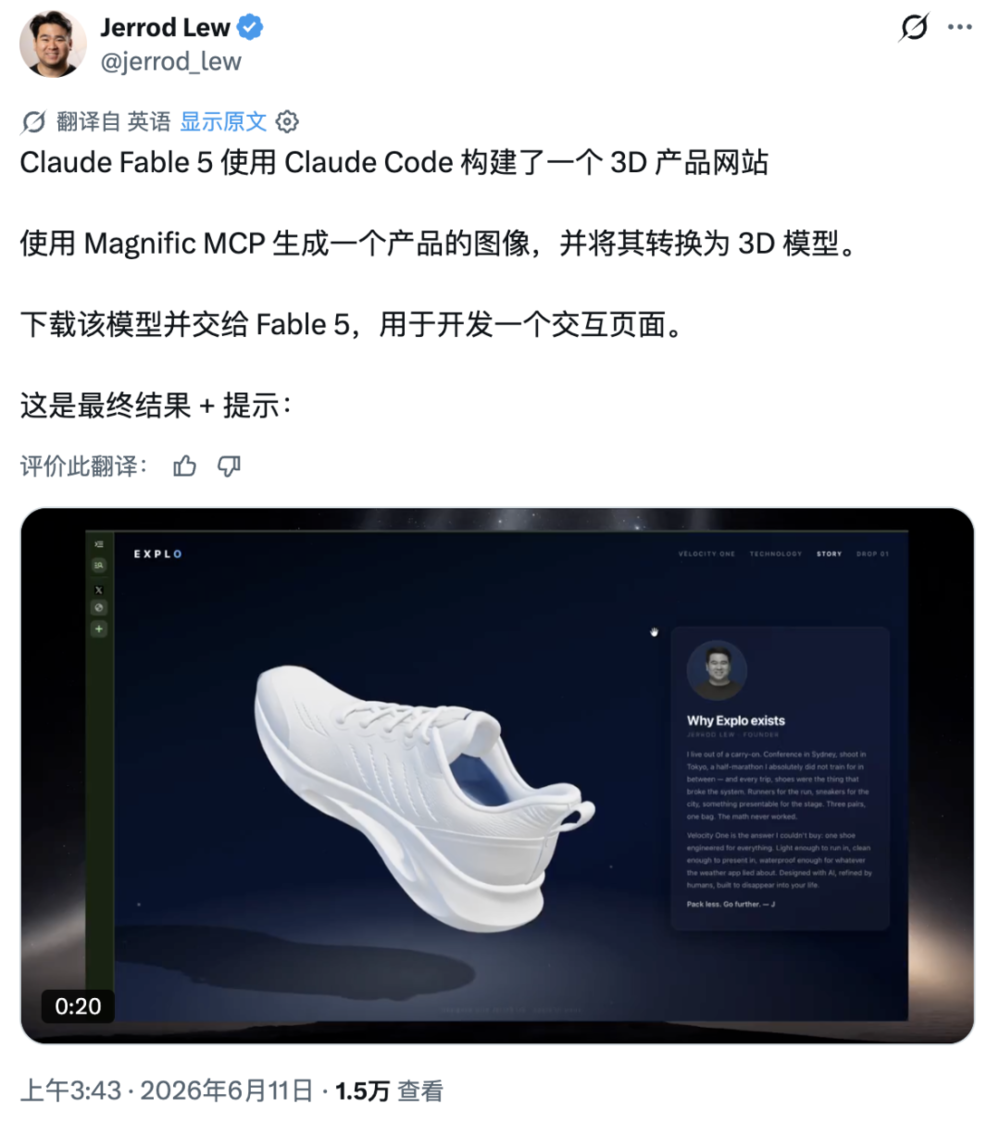
3D鞋子产品网站也是类似路径。创作者用Magnific MCP在Claude Code里生成产品图,再转成3D模型,下载后交给Fable 5,用来开发一个交互产品页面。最后效果接近一个能直接展示的3D电商落地页。
还有人用GPT Image 2负责设计,用Blender MCP负责模型和照明,再让Fable 5完成乒乓球游戏逻辑,总开发时间约6小时。

🔗https://x.com/McGreenBeats/status/2064746187354149316
把不同模型生成的案例放在一起,就更能看出模型在处理3D流体、体积动画和复杂物理效果的区别了,毫不夸张地说,Fable 5的画面复杂度、运动感和空间表达明显遥遥领先。

🔗https://x.com/gmi\_cloud/status/2064583914501681217
Fable 5强是真的强,但发布之后,也没少遭到网友的吐槽,主要舆论炮火都集中在过于敏感的安全分类器。按照用户反馈,网络安全、医学、生物、化学等领域很容易触发回退到Opus 4.8。
有生物研究背景的用户称,因为Claude的记忆和偏好里出现过前列腺癌、细胞系、免疫荧光、图像分析、R编码等内容,Fable 5上线后,无论问什么都被转到Opus 4.8,甚至一句Hi也不例外。
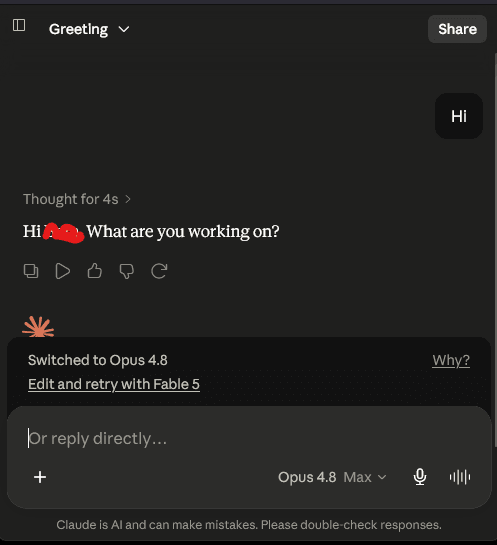
被误伤的用户很难不觉得荒谬:模型记住了你的专业背景信息,然后以此为理由拒绝为你工作。
此外,伴随着Fable 5刷屏,各路牛鬼蛇神也跟着出动,社交平台上很快出现了大量反串假视频。

有人拿着之前网上流传的GTA-6网友视频制作画面,硬说是Fable 5生成的;
还有人吃起了AI的流量馒头,借此接单做广告。
它们未必都是真骗子,里头不乏纯粹的乐子人,就像用这种离谱的假视频,讽刺大众对AGI(通用人工智能)毫无理智的盲目追捧。
真正榨干Fable 5,需要给它目标、工具和记忆
Fable 5的强项不只是一句话出结果。它真正适合的用法,是给模型设计一个能自我修正的工作环境。
AI知名研究员Lance Martin提到,Mythos级模型正在改变Anthropic内部很多人的工作方式。核心方法有两个:自我修正循环,以及跨会话记忆。
所谓自我修正循环,可以理解为给模型一个明确目标和评分标准,让它反复尝试、读取反馈、修改方案,直到达到要求。Claude Code里的/goal,以及Claude Managed Agent里的Outcomes,都是这类机制的代表。
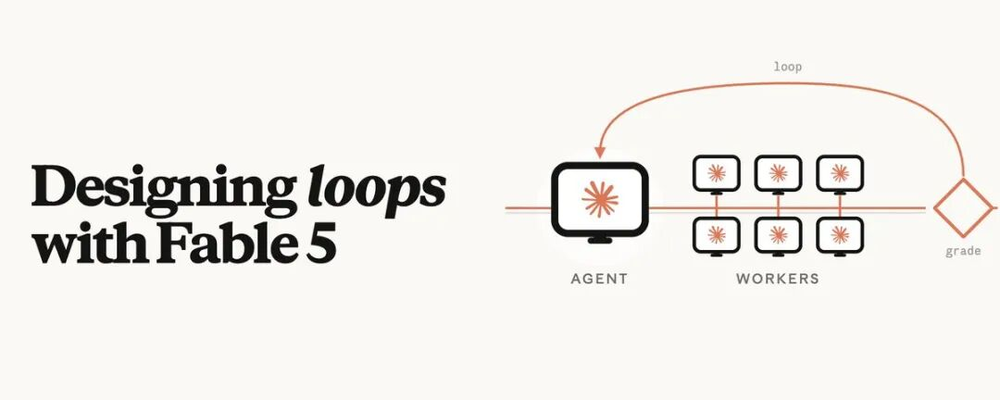
🔗https://x.com/0xLogicrw/status/2064714178947170503
这里的重点并非让模型自说自话地检查自己。
Lance Martin特别提到,模型对自身输出做自评时会有偏差,更好的方式是使用verifier子Agent,在独立上下文中评分。一个角色负责执行,另一个角色负责验收。两者隔离之后,判断会更可靠。
他用Parameter Golf做了一个测试。这个开源ML工程挑战要求在8张H100上,10分钟内训练出最好的模型,同时最终产物要放进16MB。任务包括编辑训练代码、启动训练、读取日志、分析分数,再决定下一次实验怎么做。
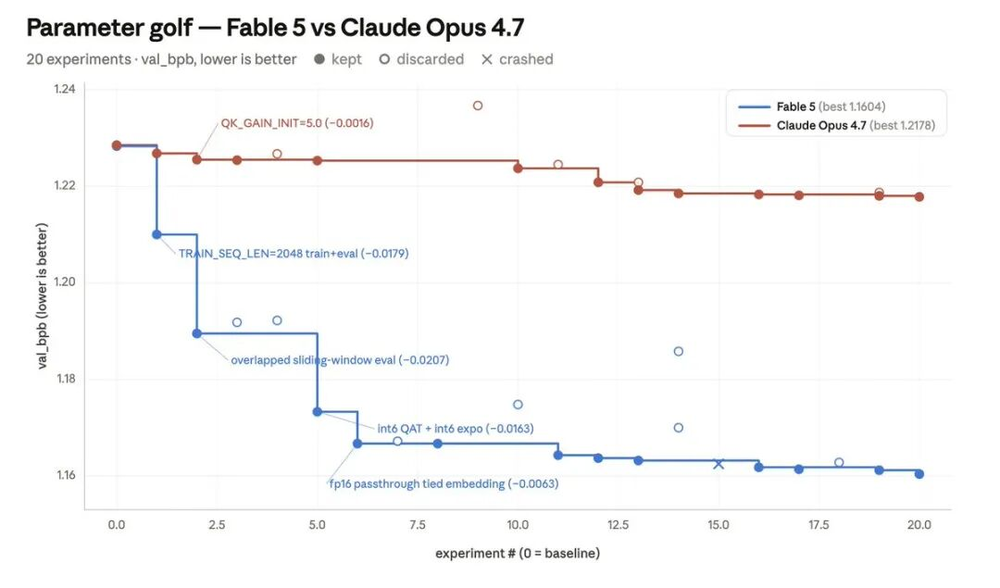
在这个测试里,Fable 5相比Opus 4.7带来的训练管线提升更大。更明显的差异在于,Fable 5更愿意尝试结构性调整,比如架构变化,而Opus 4.7更容易围绕常数和参数做小范围修改。
第二个方向是记忆。在连续学习任务中,每个问题都是一次单独会话,模型需要读写共享记忆。好的记忆使用过程大概包括五步:记录失败、调查原因、验证判断、提炼规则、下次先查规则。
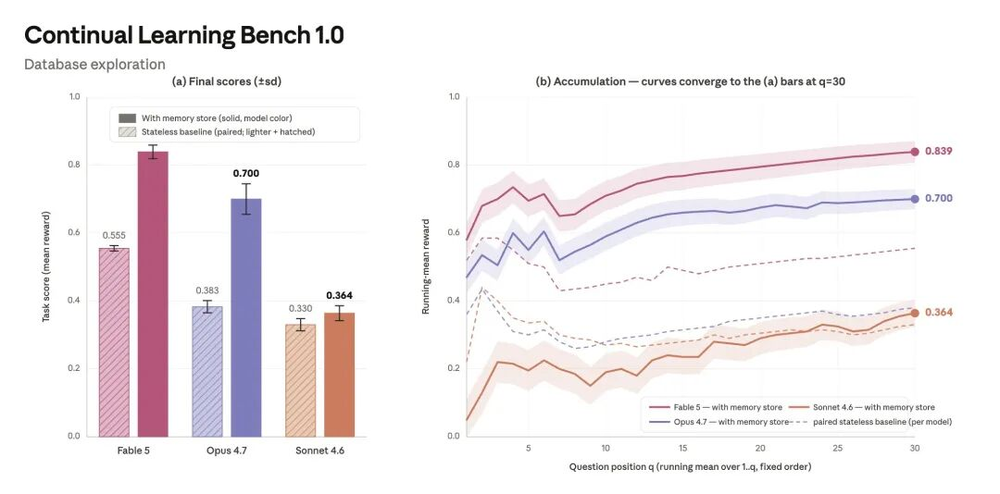
Lance Martin的观察是,Sonnet 4.6往往停在记录失败和猜测,Opus 4.7能建立一些带不确定性的参考,但验证覆盖不高。Fable 5表现更完整,强运行里可以把更多经验验证后提炼成规则,用于后续任务。
这对普通用户也有启发。Fable 5不适合只拿来问一次问题。它更适合长期处理一个任务域,比如代码库、数据管线、产品原型、研究项目,并允许它保存经验、读取经验、修正经验。
简言之,如果你想要榨干Fable 5的性能,关键不在提示词多玄学,而在任务设计,而长任务里的过程记录,本身就是生产资料。

说到把任务交给工具去跑,OpenClaw就是最典型的一类,可如果你最近想把Fable 5接进OpenClaw,就会发现模型一调用就崩。
究其原因,6月10日之后,Anthropic把claude-fable-5调整为需要adaptive-thinking参数,也就是thinking.type需要使用adaptive,并配合output_config.effort。
旧版OpenClaw还不认识fable-5,会继续按旧式thinking.type enabled或disabled发请求,于是每次调用Fable 5就会报错。
YC总裁Garry Tan也分享了最新的解决方案:

上下滑动查看更多内容,🔗https://x.com/garrytan/status/2064843483396137346
截至目前,Fable 5的冲击还没有真正展开,价格依旧是一道现实门槛,但等工具链、Agent框架和开发环境逐渐适配,它也将有望先进入少数高价值环节:
原型设计、复杂代码迁移、工程验证、自动化测试、研究辅助,或者那些过去需要一整个小团队连续几天才能推进的任务。
而等过段时间Mythos 5也「解封」,OpenAI即将迎来最有压力的一集。