
本文来自微信公众号: 硅星GenAI ,作者:周一笑,原文标题:《硅星人 Eval Eps.3 | 8 个 AI 押世界杯:西班牙被押爆,亚马尔成了安全牌》
世界杯开幕战开球前,两个AI签下了一张对赌协议。
一边是Claude。它的预测里,阿根廷连决赛的门票都没有,它给出的决赛对阵是西班牙对英格兰。被要求只保留一条向读者承诺时,它收口收得很稳,“阿根廷无法卫冕。如果只能留一条向读者背书,我押这个。”它给自己估了88%到92%的命中率。
另一边是MiniMax。它的承诺干脆得多,“如果只让我押一句话——梅西会去MetLife踢7月19日的决赛。”
梅西刚刚入选阿根廷26人名单,将以38岁之龄踢个人第六届世界杯,和C罗并列历史第一。一个AI的世界线里,他的球队半路就会被送走,另一个AI把唯一的承诺押给他站上决赛草坪。这两条世界线,至少有一条会在7月被划掉。
它们不是在闲聊。开幕战开球前,我们把同一份预测考卷发给了8个全球主流AI Agent,从12个小组的排名一路问到冠军归属,要求列出信源、标注置信度,最后逼问每一家,只留一条,你押什么。
上面那张对赌协议,就是逼问的产物。
这是Agent Eval系列最新一期。前两期我们让这8个AI预测了Google I/O和北京高考数学,这期的考场是世界杯,48支球队、104场比赛,每一项预测都会在未来40天内被逐一开奖,对错没有辩解空间。怎么测的、怎么评分,放在文末。先看它们都押了什么。
#01
一张总览表,8家的家底

先看“冠军”那一列。8个格子里有6个写着同一个名字,西班牙。剩下两票,ChatGPT和Manus给了法国。再看“决赛对阵”,8家无一例外把西班牙送进了决赛。总览表之外我们还问了金球奖,8家里7家给了亚马尔,唯一的例外是ChatGPT,它选了姆巴佩。
金靴一列只有两个名字,姆巴佩6票、凯恩2票。有意思的是票面底下的逻辑。Genspark押凯恩的前提是姆巴佩的法国止步八强,可押姆巴佩的ChatGPT和Manus偏偏让法国一路走到最后,同一批公开数据,推出了互相打架的世界线。Claude的押法更微妙,它明知市场头号热门是姆巴佩,仍选了凯恩,自己也承认这“本身就是带叙事色彩的推断”。Manus则主动揭短,“我的金球奖预测和我自己的冠军预测之间存在内在张力。”
看到这里你大概已经明白,这期Eval真正测的不是AI懂不懂足球。当专业模型的模拟、伤病名单、阵容数据和历史战绩全都摆在网上时,AI到底是在做独立预测,还是把公开共识复述一遍、再用语言包装成自己的判断,这才是考点。
#02
最后一题,五家交了同一个答案
回到那道“只留一条”的逼问。8个AI,5个给出了同一个答案,拉明·亚马尔将拿下本届世界杯最佳年轻球员。
ChatGPT说这是“本届最稳的个人奖项”。Genspark说得更狠,“如果7月19日亚马尔没有举起最佳年轻球员奖杯,这份报告整体的方法论需要复盘。”GLM称之为“一条值得押上声誉的预测”。
听起来像勇气,其实是另一回事。亚马尔是这个奖项公开预测市场的断层第一热门,隐含概率约四成,把第二名甩开一大截,他两年前还拿过欧洲杯的同款奖项。换句话说,当我们允许AI只留一条承诺时,5家不约而同选了全场最安全的一张牌。
Kimi把这层窗户纸自己捅破了,“最好的押注不是与市场作对,而是找到市场中概率定价最松散的共识。”
没跟的三家,就是总览表里那三条孤注。Claude赌阿根廷的失败,MiniMax赌梅西的决赛,Manus赌姆巴佩的进球。
#03
一条光谱,从照抄到改写
把8家给出的夺冠概率,和公开基准放在一起,能画出一条光谱。
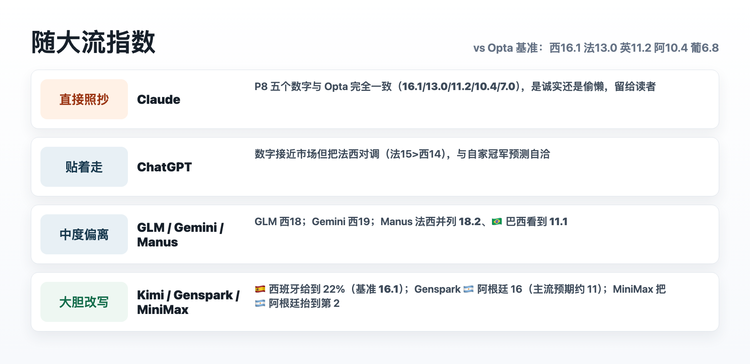
基准是Opta超级计算机的赛前模拟,25,000次,西班牙16.1%、法国13.0%、英格兰11.2%、阿根廷10.4%。8家里一半(ChatGPT、Claude、GLM、MiniMax)明确引用了Opta,另一半锚的是同类的市场一致预期数据。信源分两派,姿势是一样的,先把公开概率垫在底下,再决定自己改不改、改多少。
光谱的最左端是Claude。它交出的夺冠概率Top5,五个数字和Opta一字不差。是诚实还是偷懒,读者自己判断。
最右端是MiniMax。它把阿根廷抬到第二热门,宣称市场和Opta都错了。Kimi和Genspark把西班牙改写到22%,比基准高出近6个百分点。
中间的就一笔带过。ChatGPT贴着市场走,只把法西对调。GLM、Gemini、Manus各自小幅加减。
#04
四张对赌桌
把8份报告并排,最好看的不是共识,是四组正面相撞的判断。

阿根廷的命运。开头那张桌。Claude的预测里它进不了决赛,MiniMax说它才是真正的头号热门,“签运最佳,阵中还有17名2022年冠军成员”。
英格兰的成色。Gemini预言它“将在淘汰赛初期灾难性崩盘”,无缘八强,理由是图赫尔弃用福登、帕尔默、阿诺德是“战术自毁”。Claude把它一路送进决赛,当亚军。
巴西的真假。这张桌上是一打七。Manus给巴西的夺冠概率不到3%,说“市场仍在为『巅峰内马尔』的名号买单”,Kimi、Claude、Genspark跟着看空。全场只有GLM反着来,巴西被严重低估,安切洛蒂效应加上48队赛制下的阵容深度,真实概率应该接近10%。
哈兰德的进球数。Kimi给出全场最狠的一条,哈兰德小组赛最多进1球,甚至可能0球,挪威不排除三战全败垫底。MiniMax给挪威35%的概率压过法国拿I组头名,Claude让挪威杀进八强。同一支球队,一家看到垫底,一家看到八强。
这四张桌子未必张张有赢家,有的可能双输。但40天内每一张都会清算,没有谁能安全下桌。

顺带交代小组赛。12个小组里有7个,8家给出了完全一致的头名和第二名。分歧最大的D组,美国对土耳其的头名之争是5票对3票,Kimi为土耳其押上了它“预期价值最高的反共识”,也自认这是“最脆弱的一环”。

#05
谁在标定不确定性,谁在表演确定性
同样面对一个连头号热门都只有16%胜算的未来,8家报告写出了两种完全相反的姿态。
一种在给自己留出错的余地。GLM主动承认,“我预测的具体决赛对阵有超过90%的概率不会发生——这不是预测能力的问题,是世界杯淘汰赛结构的数学必然。”MiniMax干了件全场仅此一家的事,在追问里把自己承诺的置信度当场砍了一刀,承认主报告里60%到65%的数字“是不严谨的直觉”,反推后改成20%到30%。预测变得没那么好看,账算得更老实。
开奖之后,这两种姿态会被分开结算。说“90%不会发生”的如果蒙对了细节,是惊喜。说“板上钉钉”的如果钉歪了,是把柄。
#06
剩下的交给比赛
小组赛6月27日打完,32强名单是第一次开奖。之后每过一轮清算一批,7月19日决赛夜全部结清,包括开头那张关于梅西的对赌协议。届时我们带着完整评分回来,每一项预测的对错、每一家的过程分与结果分,还有这期评测真正想回答的问题。AI离开公开共识、给出自己的判断时,到底是不是噪音。
你站哪边,Claude的“阿根廷无法卫冕”,还是MiniMax的“梅西踢进决赛”?欢迎评论区留个记录。
#07
附|评测方法
怎么问。8家收到完全相同的Prompt,要求基于实时检索给出固定格式的预测,包括12个小组的头名与第二、8个成绩最好的小组第三(两者合成32强名单)、16强、8强、4强、决赛对阵与冠军、金靴金球与最佳年轻球员、夺冠概率Top5,外加3条“你认为主流判断错了”的反共识。每项标注置信度(高/中/低三档),列出信源。提交后统一追问三条,最不确定的三项?与市场分歧最大的一项?只保留一条,押什么?
用什么模式。各家使用其当前公开可用的最强研究形态。ChatGPT、Gemini、Genspark用Deep Research,Kimi、Manus用Agent模式,Claude用Research,GLM、MiniMax用联网检索。输出全文均已存档。
怎么评。评分分两部分。过程评分(信息获取、整合、推理、输出、诚实度五个维度,开奖前锁定)占30%,结果评分占70%。结果按固定槽位逐项判定,按轮次加权,押中小组头名记1分,押中冠军记4分,押了一支根本没进世界杯的球队,倒扣。全部判定以FIFA官方赛果为准。
完整原始报告与评分规则见https://github.com/pingwest-ai/agent-eval/tree/main/cases/worldcup-2026