
本文来自微信公众号: 海豚研究 ,作者:海豚君
1、原本“逊爆了”的亚马逊AWS当下AI的业务布局如何?
2、亚马逊和Anthropic之间的合作关系对公司的帮助有多大?该合作关系是否稳固?
3、亚马逊的自研芯片能力到底如何?
4、亚马逊最弱的大模型能力达到什么水平了?
对于以上几个问题,海豚君来详细看看:
一、亚马逊AI要跑起来了?
1、细探AWS的收入构成
26年一季度,亚马逊的AI年化收入超过$150亿,占AWS总收入的比重达到约10%,而在24年一季度时公司曾模糊的表述过当时AI年化收入体量约小几十亿。当前AWS中AI收入约10%的占比仍明显低于Azure的超20%,相对仍低。
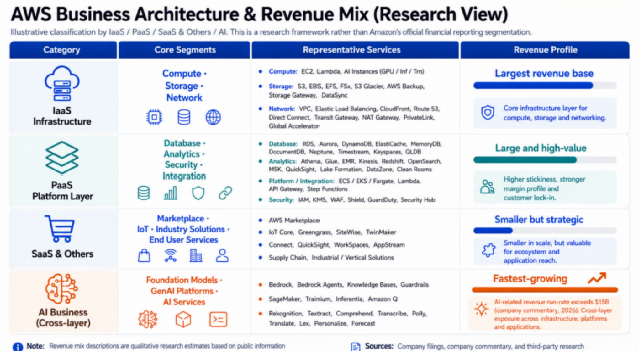
分析AI收入构成前,先说下AWS的收入细分:
a.IaaS:算力芯片、存储(硬盘)、连接带宽等基础资源,拳头产品如“EC2”。因是基础硬件初级虚拟化租赁,利润率低。
b.PaaS中间层:各类Database,数据分析工具,调度管理工具和安全工具等中间层应用,利润率更高;
c.SaaS应用层&其他业务:自研或或第三方软件,以及其他业务例如垂类行业解决方案,IoT等。
AWS一直IaaS最多,即使到现在也仍占60%,PaaS类占比提升到30%,SaaS仍是个位数比重。
2.跨层的AI业务
至于三层蛋糕之上的“+1”就是三大板块中和AI相关收入,单拉出来的口径。据市场推测,AWS的AI业务具体包括:
a.主要是算力租赁业务(IaaS类):相比传统算力租赁的差异是,AI算业务租赁的一般是基于Trainium/Inferentia芯片或英伟达GPU,且客户更加集中于大型AI Lab或科技企业。
由于AI需求的芯片和存储成本高涨,客户群体又更加集中、议价权更强。因此,云厂商们在AI IaaS业务上利润率很低,比传统云低。
b.第二大部分是Bedrock–AWS旗下的MaaS/TaaS(Token-as-a-service)平台,不直接租硬件,而是亚马逊部署好大模型后,直接对外出售模型API或Token。
c.其他还有SageMaker和亚马逊Q等。其中SageMaker简单来说是预部署好的AI/ML训练、调试和部署平台,方便用户自行训练或微调AI大模型,以及训练完成后的调用和推理。
亚马逊Q则是直接面向终端用户的AI Agent产品线,可再细分为Developer、Business、Connect等产品,分别面向开发者、企业员工、客服等用户。
这两项业务和Bedrock一样,都不直接出租“裸硬件”,通过硬件基础上附加上一层服务,因而逻辑上会有更高的利润率。
AWS收入高增,利润率没掉链子,除Anthropic用量爆发外,核心是因为:
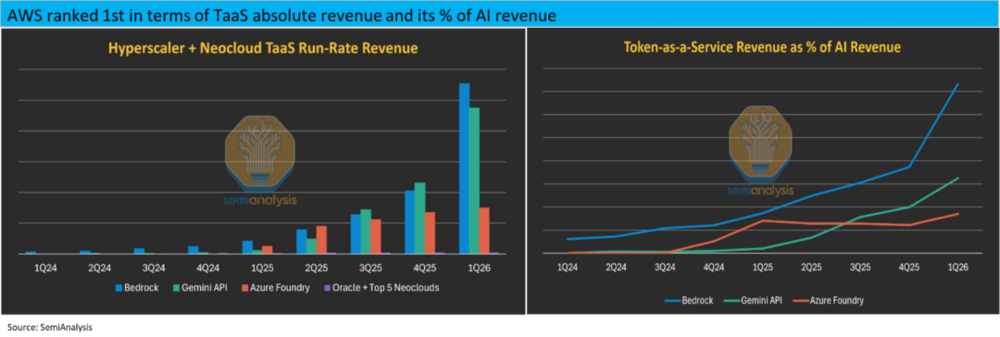
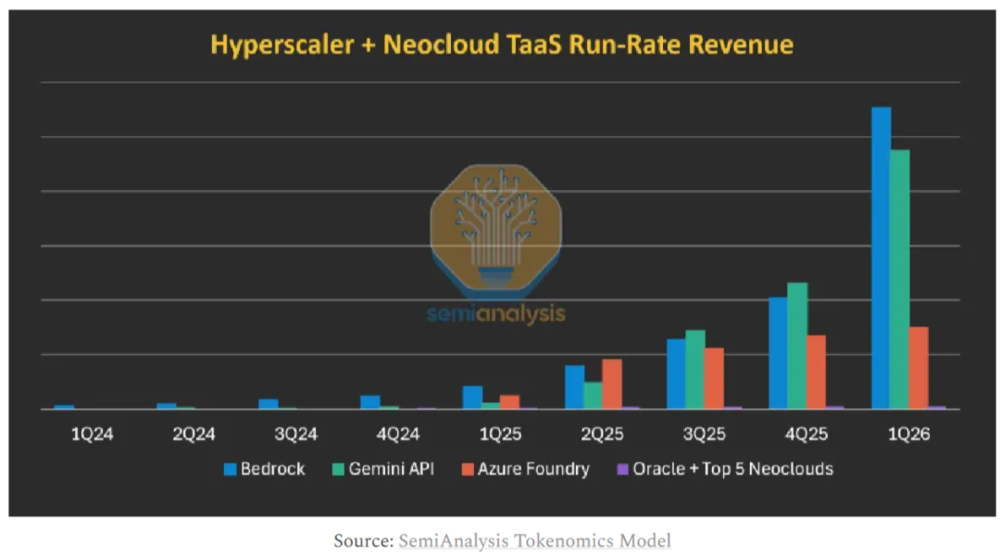
a.AWS AI营收占比不高,但高利润MaaS/TaaS占比多。根据Semi Analysis调研,目前Bedrock贡献了AWS AI收入约37%,而Azure和GCP的AI收入中的约80%仍是来自IaaS类的纯硬件租赁。
b.MaaS/TaaS绝对收入规模上,AWS同样领先达约$55亿,谷歌云稍低于50亿,而Azure则不到20亿。而亚马逊的MaaS/TaaS业务目前的经营利润率可达55%vs.1Q26 AWS整体不到38%的经营利润率。
c.新云如甲骨文、CoreWeave等因与新云们在软件能力上普遍不强,大多只能做“裸金属”租赁这类低附加值且低利润率的业务。新云MaaS/TaaS收入合计相比三大云厂商基本忽略。
二、和AI Lab合作关系也是关键竞争力
以上我们从AI能力三大支柱能力之一--算力的角度,简要探讨了亚马逊AI业务的具体构成,以及当前MaaS/TaaS正成为云业务的主要发力方向。
而海豚君认为,MaaS/TaaS业务的主要竞争力在于两点:一是平台能提供的模型深度(有没有当前最强SOTA级模型)和广度(可选择的模型数量、类型、层级多不多);二就是提供类似模型时,成本和定价能不能比其他云厂商有优势。
而这第一点对应的是云厂商自研模型或是和第三方模型公司建立良好合作的能力;第二点则主要对应云厂商们通过自研芯片或优秀工程能力降低单位算力成本的能力。
亚马逊一直强调平台模式,对大模型研发投入度不够,自研Nova模型目前能力仅大约相当于Haiku 4.5到Sonnet 4.5水平,因此亚马逊相当依赖于外部AI Lab来其补强AI模型能力。
实际上,前文提到的Bedrock业务销售的API/Token绝大部分是基于第三方模型,目前以Claude为主,在公司和OpenAI建立深度合作后,后续GPT模型API/Token数量想必也会明显提升。
因此,我们接下来就详细探讨下亚马逊和Anthropic这家头部AI Lab的合作关系:
1、与Anthropic的合作
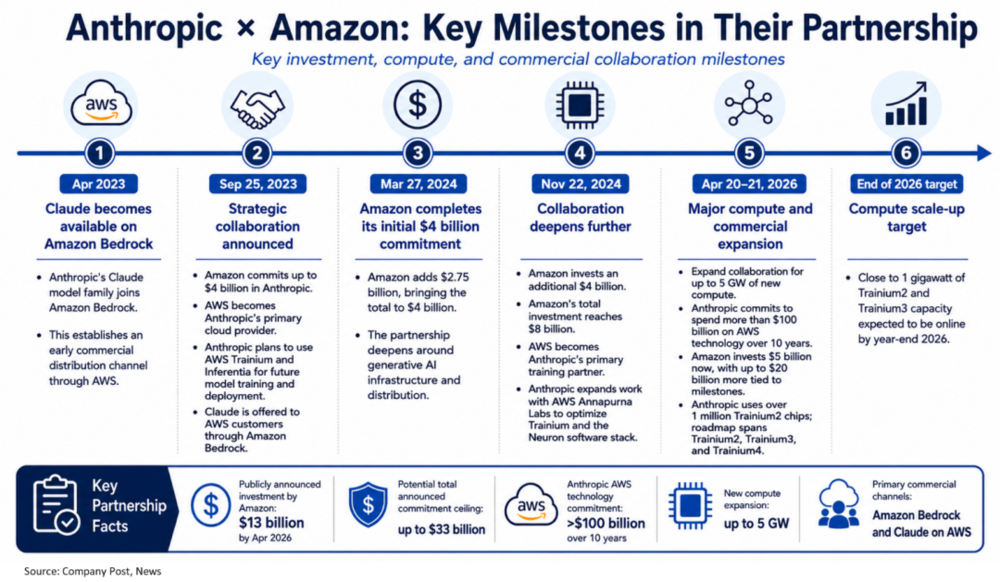
亚马逊首个深度合作的AI Lab是Anthropic,最早的“合作迹象”可追溯回23年4月时Claude模型上架Bedrock,正式官宣合作则在23年的9月。概括来看,两者之间和合作关系发展可大致分为三个阶段:
a.23年9月:首轮合作亚马逊对Anthropic注资40亿美元(分三次到24年5月全部完成),相应的Anthropic决定以AWS为首要云服务提供商,将在训练和推理中更多使用Trainium和Inferentia芯片(根据新闻报道,此前可能主要使用TPU和Nvidia GPU),并在Bedrock上全面向商业用户提供Claude模型。
b.24年11月:这轮合作中,亚马逊对Anthropic再注资$40亿、累计80亿。同时,双方的合作深入到了芯片设计和模型的共同一体化研发。包括硬件上,Anthropic直接与Annapurna Labs(亚马逊旗下芯片研发部门)合作开发设计Trainium等芯片;软件上,Claude模型的底层内核也专门针对Trainium芯片和指令站进行优化。
这一阶段内,两家公司合作的Project Rainier--主要基于Trn芯片的超大规模算力中心项目也首度得到官宣。(后文会再单独详细讨论该项目)
c.26年4月:亚马逊进一步对Anthropic注资$50亿,累计达$130亿,并拥有最高达$200亿的额外投资权。
Anthropic承诺十年内在AWS上花费超过$1000亿,并使用5GW的Trainium芯片,包括已投产的Trn2和后续的Trn3&Trn4。
这里有意思的一点是,目前公允的1GW算力对应的年收入额普遍略高于$100亿,而该1000亿对应5GW的合约中,隐含的每GW Trn芯片算力产生的年云收入明显偏低。
虽然部分原因是算力爬坡需要时间并非从Day1就会用满5GW算力,并且Anthropic也每表示除了5GW的Trn芯片外,不通过AWS租用基于其他芯片的算力,但多少侧面体现出Trn芯片的综合使用成本应当明显低于基于英伟达GPU的成本。
2、Anthropic对AWS收入的贡献?
那么作为亚马逊的AI战略上最重要的合作伙伴,Anthropic实际给AWS贡献的营收规模有多大?
这包括两个部分,主要部分是Anthropic自身花费在AWS上的训练和推理费用,另一部分则是AWS通过Bedrock代销Anthropic模型API/Token产生的分佣收入。
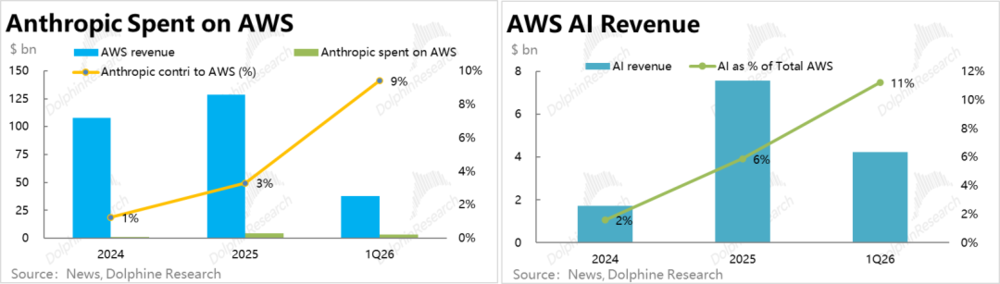
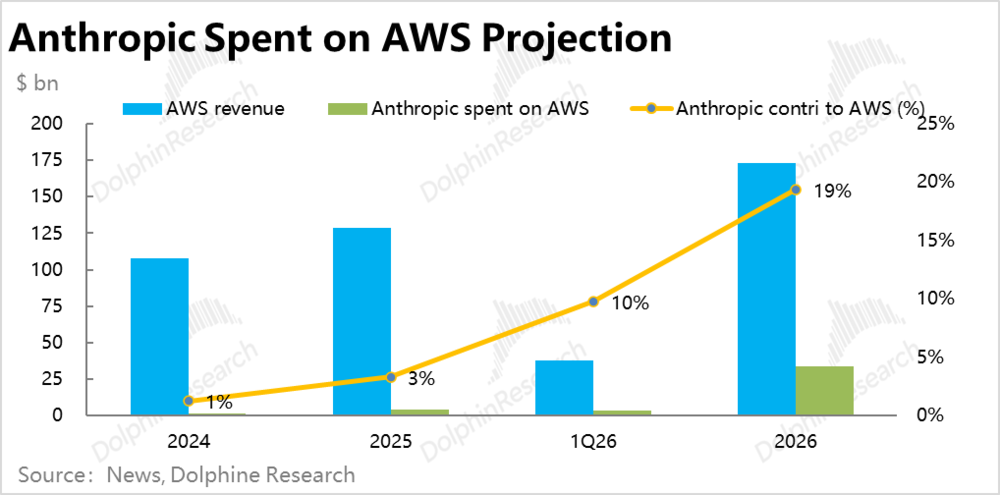
a.海豚君根据新闻报道中的数据进行粗略测算,24年、25年和26年1季度内,Anthropic的算力支出大约占AWS当期收入的约1%、3%和8~9%。虽然绝对占比不高,但以今年1季度为例,Anthropic直接贡献的收入占AWS AI收入的比重能达80%或更高。
b.而AWS通过Bedrock分销Claude模型产生收入,该模式下Bedrock定位是分发平台,Anthropic自身才是销售主体,因此全部销售额会记为Anthropic的收入。AWS从中直接获得的收入,是基于销售额一定比例的渠道佣金。
因而,MaaS业务贡献的绝对收入规模会较小,但也因佣金性收入的边际成本非常低,利润率会明显更高。整体来看,可以说当前AWS AI收入的绝大部分都是由Anthropic直接或间接贡献的,因此Anthropic后续ARR的增长势头也对AWS的增长提速有很强的指引作用。
(需要注意,当客户在Bedrock上购买Claude模型的API/Token时,其底层的调用的算力硬件大概率也是由AWS供应,因而也会给AWS带来硬件出租收入,但这部分是作为Anthropic在AWS上花费的推理算力支出计入IaaS收入)
c.目前看,亚马逊和Anthropic没有类似微软和OpenAI基于股权关系的收益分配。
d.整体来看,当前AWS AI收入的绝大部分都是由Anthropic直接或间接贡献的,因此Anthropic后续ARR的增长势头也对AWS的增长提速有很强的指引作用。
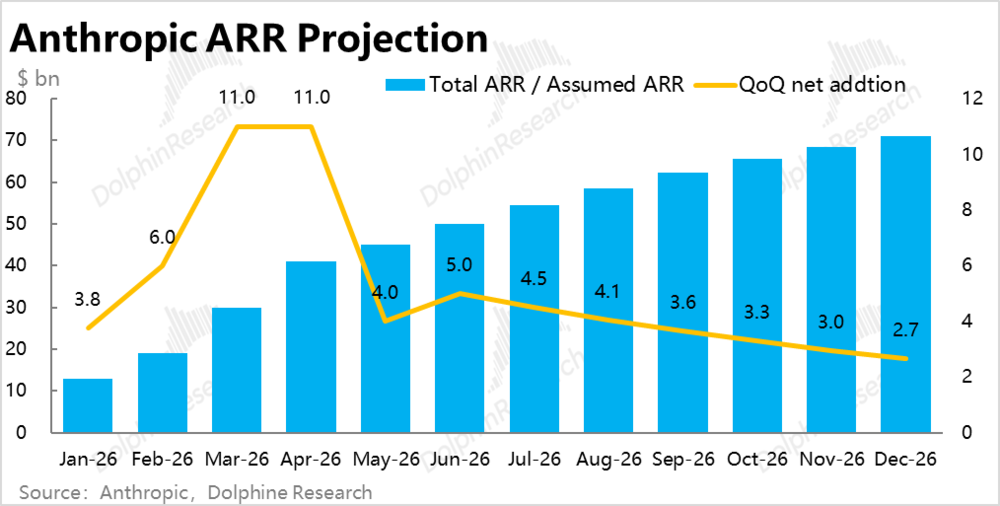
做一个简单测算,Anthropic的ARR在3、4月达峰后,5月的环比增速有所放缓。截至5月其ARR大约为$450亿,保守假设按后续每月的环比增量平稳下降,到26年Anthropic底达约700亿出头。
则在简化假设后续AWS所有AI收入都来自Anthropic,且AWS非AI收入在26年增长约16%(去年约14.4%)的情况下。则26年全年Anthropic可能会贡献AWS约19%的总收入,带动AWS在26年的总收入增速达到35%以上,相比一季度是约28%的增速。和我们此前在模型中预估的全年增速大体相当。
此外,微软曾一度因和OpenAI的紧密合作,业绩强势上扬。但之后也因和OpenAI关系的渐渐疏离,呈现颓势。模型和模型分销商之间强共振。
亚马逊和Anthropic之间会不会复刻微软的“老路”?海豚君看下来,感觉应该不会。
首先虽然两个CSP都是两个顶模的早期投资人,而且投资金额也都类似,但关键区别是:
a.微软&OpenAI的股权绑定更深:据推测亚马逊对Anthropic仅持有约个位数%的少数份额,在后者的管委会中也没有席位。
因此,海豚君认为微软和OpenAI之间的合作很大程度上建立在更高的股权关系绑定上,这一点从微软能够直接从OpenAI的收入中直接分成,且之前对API有独家分销权。亚马逊却只能从与Anthropic的正常商业交易中获得收益,也有体现。
b.合作开放,但亚技术绑定深:我们认为亚马逊和Anthropic之间的合作关系,更多建立在两家公司之间的技术。
Anthropic的模型训练大量使用了亚马逊独有的Trainium等芯片,且Anthropic模型的底层代码和亚马逊的ASIC芯片相互之间都做了专门的深度适配。
因此,Anthropic不能“无痛”脱离亚马逊,有比较高的迁移成本。而由于微软在自研芯片上的能力不足,GPT模型主要基于英伟达的硬件生态,OpenAI因此对微软没那么依赖。
3、Project Rainier能告诉我们什么?
这一章节的最后,在简要聊一下Project Rainier,如前文提到的这是AWS为了满足Anthropic训练和推理需求,建设的基于亚马逊自研芯片的超大算力中心。根据公司已宣布的建设计划,该项目前包括2个营址(Campus)--Campus New Carlisle和Campus Northern Indiana,具体来看:
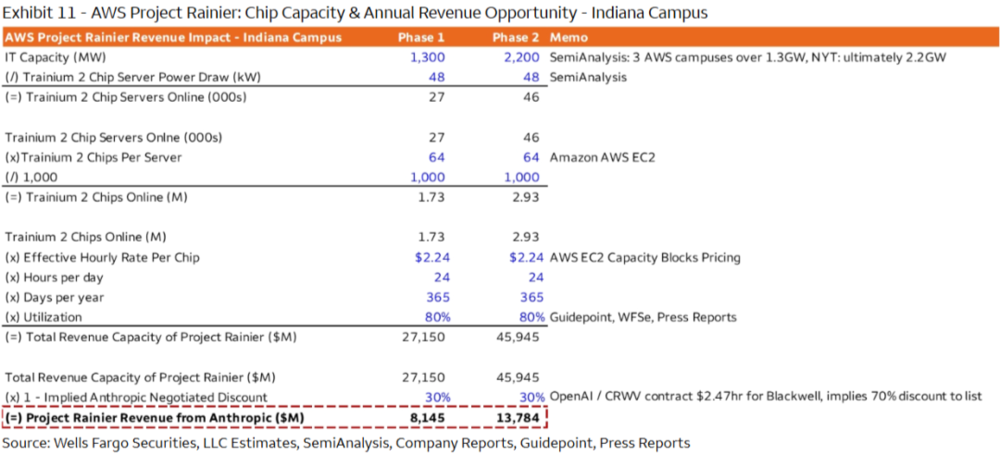
a.New Carlisle是首个项目,计划总投入110亿美金,总算力规模在2.2~2.3GW。于24年9月开始建设,25年10月底首次投入运营(当时上线规模大约为50万颗Trn2)。据Well Fargo的预测,26年初该项目一期(Phase 1)完全上线,总规模大约1.3GW,据测算对应约170万颗Trn2。
随着Trainium 3代芯片计划于26年中开始量产,后续Rainier项目中将同时部署Trn 2代和3代芯片,并且预计将再新增约0.9~1GW的产能(预计大部分将在26年内建设完毕)。
b.Northern Indiana项目在25年末宣布,预计总算力规模约2.4GW,计划投资额$150亿,目前对该项目的信息较少,但有新闻报道在5月开始该项目已进入建设阶段。

根据以上信息,可以初步得出以下几个值得关注之处:
a.目前Project Rainier已宣布的合计产能约4.6~4.7GW,且主要基于Trainium芯片建设,这和Anthropic在4月合作协议中宣布将总共使用约5GW Trn芯片的规模基本对应。
因此该项目的建设节奏可以视为亚马逊和Anthropic两者之间合作关系的风向标。
b.亚马逊从零到建设完成约1GW+算力中心需要的时间大约在15~16个月,该建设速度和同行Oracle的速度大体相当(Abiliene Phase 2约1GW,预计15个月完成)。
c.按公司披露的投资额,Rainier两个项目对应的单GW计划投资额仅$50~60亿左右,远低于英伟达声称的每GW对应500亿投资额的框架。当然公司并未明确$110亿和$150亿投资额覆盖的范围--是只包括数据中心厂房和基础设备,还是包含了芯片、服务器等全部设备。(按常识应该不太可能是完整的花费额)
因此,虽不能简单推断Trn芯片的单GW建设成本只有基于英伟达GPU的1/10,但定性推断Trn芯片的单GW综合建设成本比英伟达GPU低不少应当问题不大。
d.从Anthropic宣布的10年$1000亿的云计算支出,对应5GW Trn芯片,隐含单GW收入明显低于目前行业内每GW对应约100亿收入的普遍水平。
参考外行的测算(测算与25年底,因此不可能是通过4月宣布的合作金额来倒推),Trainier New Carlisle项目2.2 GW产生的实际年收入(折扣后)大约在140亿,即基于Trn芯片的每GW算力产生收入大约只有目前行业均值的60%~65%。
综合以上两点,可以侧面表明Trn芯片对运营方而言建设成本,和对用户的使用成本应当都明显低于当前基于英伟达芯片的平均水平。
但也需要强调,Project Rainier目前主要使用的Trn2和Trn3代芯片的绝对性能,前者大致只有H200的约60%,后者略微超过。因此定价要低也合乎情理。
二、亚马逊的ASIC芯片实力如何?
云算力、芯片和大模型是AI综合能力的三个主要评判标准,而亚马逊的自研芯片是其能深度绑定Anthropic,并在云业务上建立成本优势的关键因素。因而这一部分我们来探讨公司的芯片业务布局。
2.1、亚马逊自研芯片类型和时间线
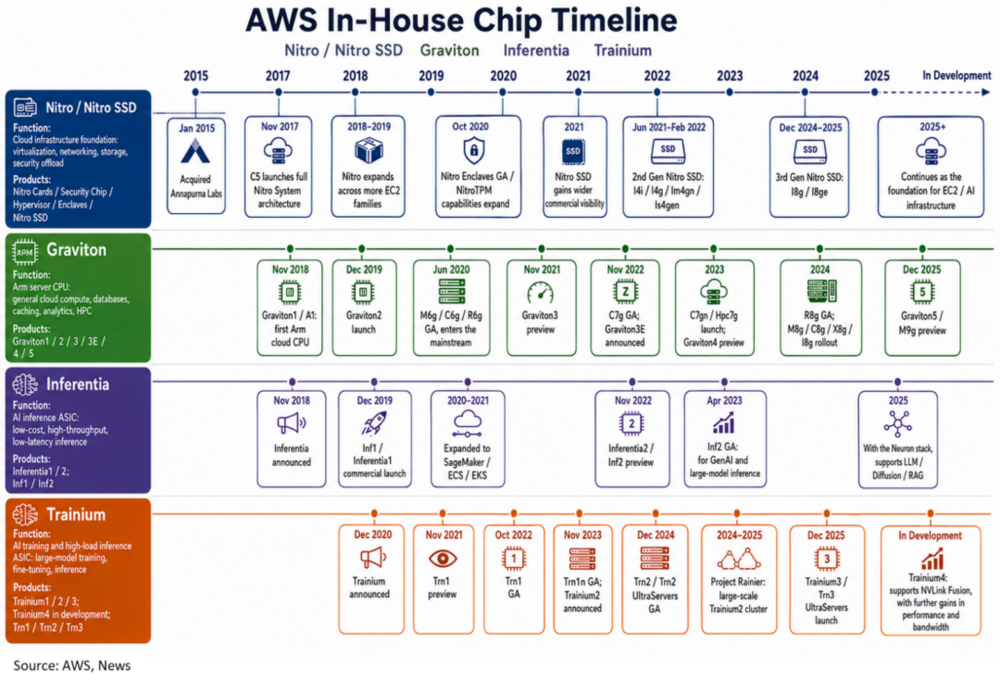
亚马逊的芯片自研史,开始于2015年初收购芯片设计公司Annapurna Labs,且可大致归类为4条并行的研发路线–Nitro(专用控制系统和存储),Graviton(基于ARM架构的通用CPU),Inferentia(推理向ASIC芯片)和Trainium(训练&推理全能向ASIC),具体来看:
1)Nitro/Nitro SSD:是公司自研的第一条硬件产品线,17年就推出首代。Nitro系列不直接供客户租用常规计算芯片,而是专用于内部管控的控制硬件系统,将包括虚拟化,网络、存储、等资源分配,任务管、安全管控等职能,交由独立的硬件模块控制,起提升运行效率从而优化成本结构的作用。
2)Graviton:基于ARM架构的通用型CPU,最早一代发布于18年,早期以低价格/高能效比为特色,主要负责相对低负载任务。
而经过多轮迭代后,目前第5代(25年底推出,预计26年中开始大规模商用)已和同代x86架构主流CPU性能不再有巨大差异。
因此,Graviton目前已大量提供给外部用户租用,且大概率是目前亚马逊使用量最大的自研芯片。
3)Inferentia:主要用于传统AI/ML(machining learning)的专用推理ASIC,首代发布于18年底,当时是主要用于如搜索排序、个性化推荐、图片/语音识别等较为基础的ML功能。
随后转型为LLM的推理芯片,但因推理对芯片性能的要求也“水涨船高”,且Trn芯片也可以用于推理,因此目前其定位已部分被Trainium取代,在22年底公布2代后至今无新产品发布。
4)Trainium:进入LLM时代后,目前亚马逊最重要的自研芯片产品线,首代发布于2020年(实际应用于22年),最早的目的也是用于训练传统ML模型。
但随着GenAI LLM模型成为AI的主流路径,在经过5年3代的迭代后(4代正在研发中),已成为主要用于AI模型的训练和推理的芯片,对标Nvidia GPU和Google TPU。
小结来看,由于Nitro主要是用于内部使用,而Inferentia的推理芯片定位已部分被取代,目前值得关注的主要就在Trainium和Graviton,后文我们的重点也就放在这两条产品线。
2.2、性能比较
概况性的讲,公司自研芯片的核心底层原因主要是--降低对外部硬件供应商的依赖,凭借从底层硬件到顶层软件一体化自研的方法,提高硬件的能效/成本比,进而最终体现为公司云业务利润率的释放。
因此性能/性价比的比对,最好的情况也是不只看单芯片能力,而是基于包含芯片、存储、网络连接、软件一套完整系统,以便更真实的体现不同芯片生态和不同云厂商的真实能力。因此,以下对Graviton芯片性能和参数的比较都是基于AWS内真实提供的实例。
1)Graviton芯片性价比很能打
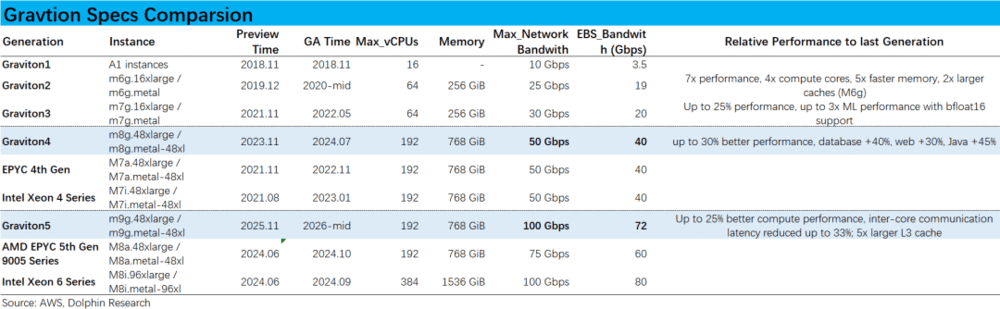
看纸面参数,下表中列出了基于Graviton各代芯片和其对标的同样CPU在AWS内实例的规格。其中Max CPU数反映最大并行计算的能力,Network bandwidth反映实例和外部的连接速度,EBS bandwidth反映计算实例和存储之间的连接速度。
由于AWS对同一芯片有大量不同型号的实体(各有能力特化),我们统一选取“M型号”(通用版本)下的最大CPU数实例,可见Graviton 5实例的纸面参数大致和已量产的最新的Intel Xeon 6和AMD EPYC 5th旗舰型号CPU相差不大。
但Graviton 5是25年底推出,26年中量产,而其对标的两款CPU芯片则都是24年的产品,下一代也已在研发中。综合来看Graviton大约还落后AMD和Intel约一代产品。(实际上从AWS的型号命名也可看出)
另外值得注意,Graviton实例的连接能力更强,如通用版本中Graviton 5强于EPYC 5代。而若都看连接能力特化版本,以Graviton 4为例,其特化版的Network和EBS最大带宽分别高达600Gpbs和300Gbps,相比之下其对标EPYC 4代的最大带宽分别只有300Gbps和50Gbps(Intel的更低)。
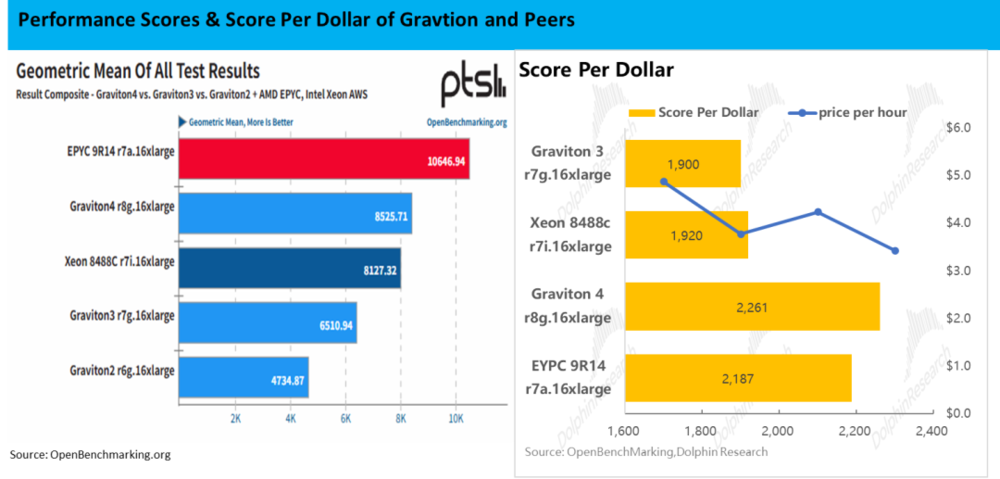
至于实际性能的比较,虽然Graviton 5因尚未大规模商用,没有实际性能测试,但OpenBenchMarking上有对Graviton4,AMD EPIC 9R14和Intel Xeon 8488三种芯片同型号实例的多种测试,可以看到:
a.Gravtion的平均性能得分和Xeon 8848c大致相同,大约是EYPC 9R14的80%。
b.按测试当时(24年底)各实例的定价,每美元对应性能Graviton4位列第一,比EYPC略高3.4%,比Intel Xeon高出近18%。
由以上基于4代的性能/能效比测试可见,虽然Graviton芯片在绝对性能上相比同代最强的AMD CPU仍有一定差距,但在AWS环境下能实现比对标的上代旗舰CPU芯片更高的投入产出比,足以吸引部分更追求投入产出比的用户使用Graviton来替代传统CPU。
2)Trainium4潜力可观?
对于Trainium芯片,由于其基本只以UltraServers/Clusters、即大规模集群的形式向大客户提供,公网上对Trainium芯片的真实性能测试(尤其是3代和4代)相当少,只能主要以官方提供的参数和性能评价作为参考。
首先在单芯能力上,可见:
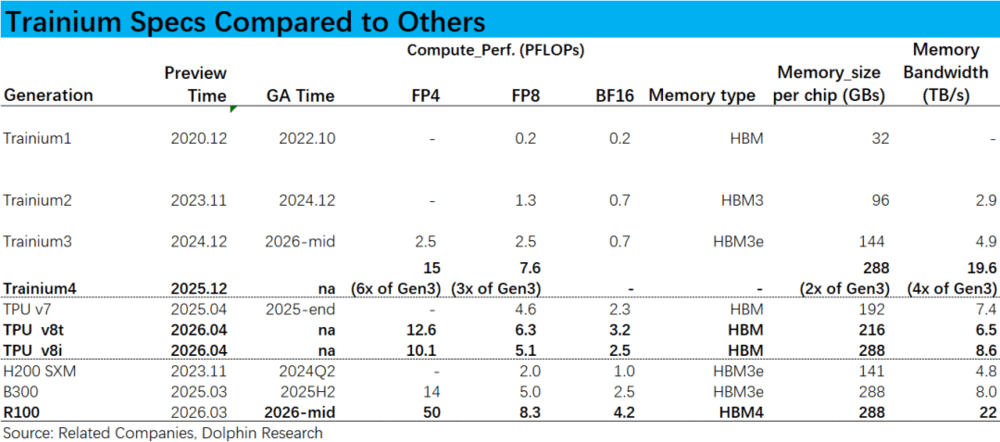
a.目前已开始量产的Trainium3的理论性能(计算频率和内存带宽),只刚刚超过Nvidia H200(发布于23年底)。但仍明显弱于Google TPU v7(发布于25年中旬),以FP8计算频率为例,Trn3的只有TPU v7的约55%。
至于已大规模使用的Trn2代芯片的纸面性能则更只有Trn3的50%~60%,显然仍不具备多强的竞争力,更多只能适配于推理计算,或非旗舰级模型的训练;
b.不过按公司披露的性能目标,正研发中的Trainium4的理论性能将直接超过TPU v8系列和Nvidia B300系列,仅在FP4计算精度下的计算速度次于英伟达最新Rubin架构下的R100系列。
也就是说,Trainium 4的理论性能若实际落地,将跨越式达到行业内的领先水平,足以吸引头部AI Lab等大型客户采用Trn4芯片来进行旗舰型模型的训练与推理,有希望进一步显著推动AWS收入的增长。
当然也需要注意以上性能目前只存在于纸面,目前Trn4还没有明确的流片时间。
三、自研模型已起步,还有很大差距要弥补
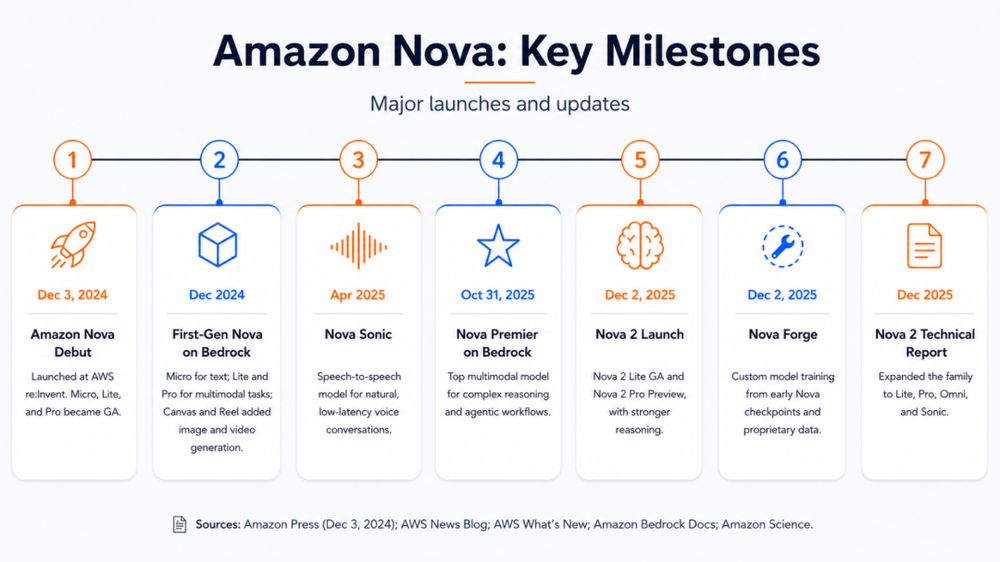
本文的最后,我们简要过一下目前亚马逊在AI能力三支柱上最弱的一环--即大模型能力。亚马逊实际也已推出了自研的大模型Nova,能力确实较差,比行业SOTA水平差了1~2个大版本,概括来看有一下几个关注点:
a.发布时间晚、更新节奏不快:Nova首代版本发布于24年12月,直到到25年底才更新了Nova2代。可见亚马逊自研大模型的起步确实较晚,且更新迭代的节奏相对较慢。
b.多模态路线:可以看到,Nova的研发路线并非追求专精(如选择文字或Coding某一能力死磕到SOTA级别),而是选择了多版本、多模态路线。在主版本之外,还有Omni版本能支持文字、图片、视频处理能力,有Sonic版本支持语音处理。
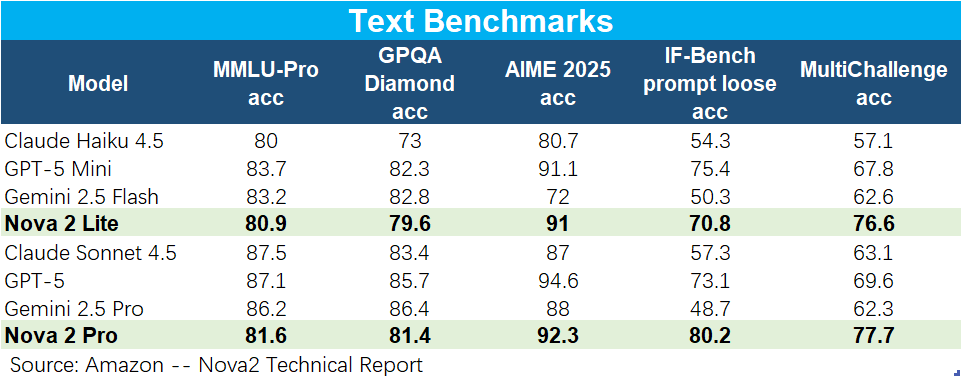
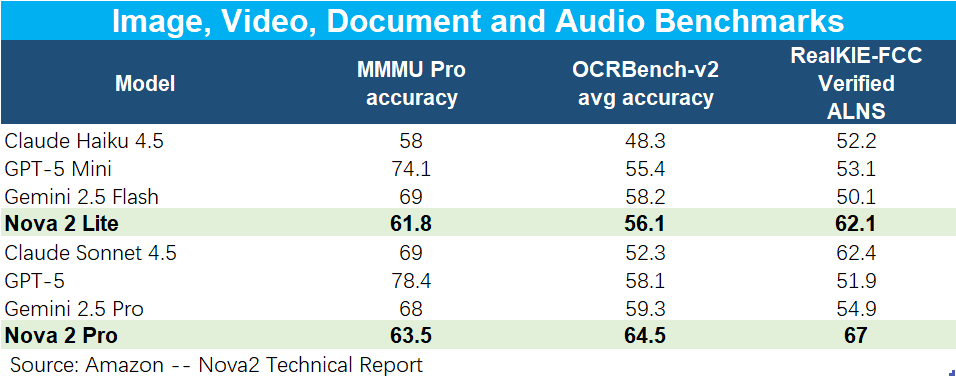
c.绝对性能不强,但反应迅速:模型的具体能力上,根据亚马逊提供的基于MMLU-Pro等指标的跑分数据,Nova2 Lite的能力大致相当于Gemini 2.5 Flash或Haiku 4.5,而Nova 2 Pro的能力,则和Gemini 2.5 Pro或Sonnet 4.5互有胜负。
可见Nova 2的能力确实不强,最新的旗舰模型只相当于头部AI Lab上一代版本的中游模型的能力,但也确实在OCR和RealKIE这两个体现对图片和结构化文档识别能力的指标上表现更好。
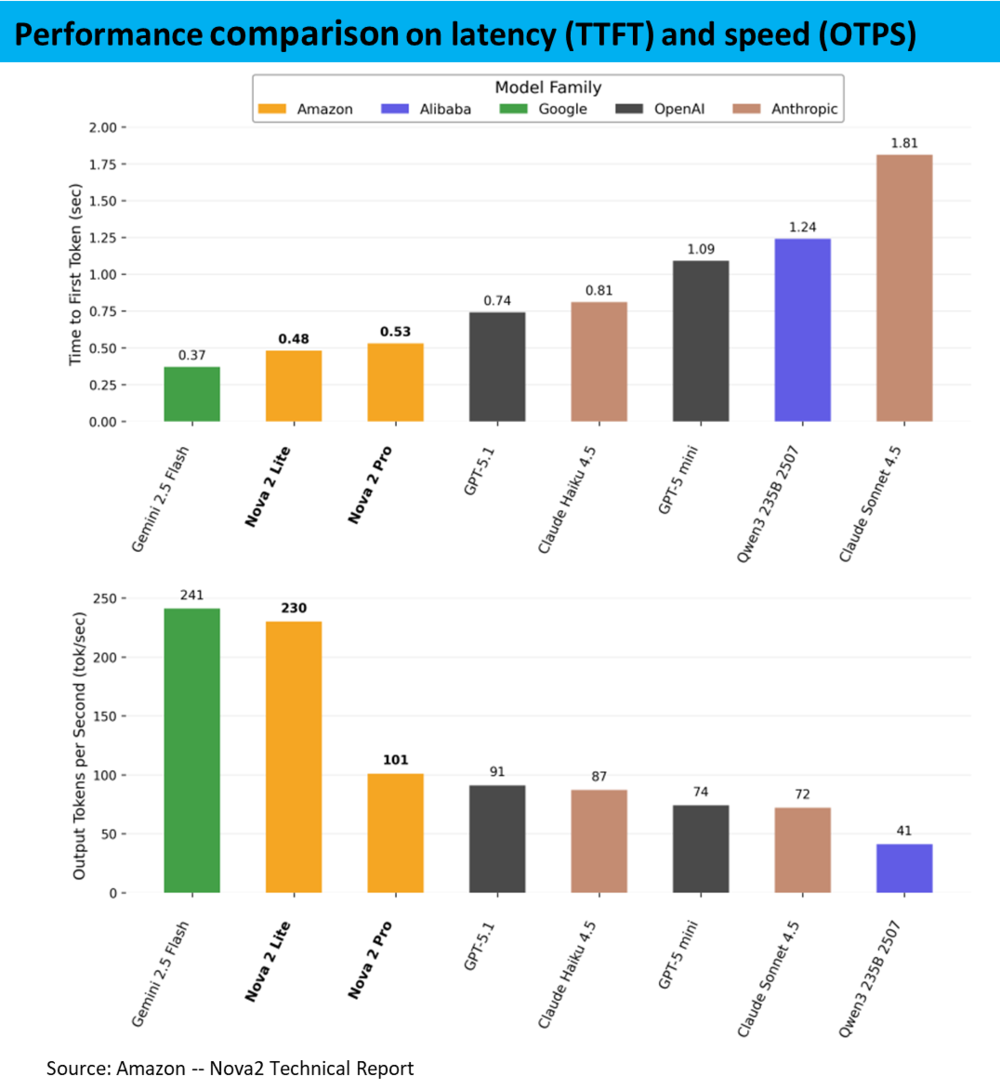
另一个亚马逊突出强调的Nova优势在其有更高的相应速度,在输出首个Token所需时间和平均每秒输出Token量,这两个指标上Nova 2 Lite和Pro都明显快于其对标模型。
d.基于Nova目前的多模态路线和能力,海豚君认为Nova目前应当更多是用于企业内部的提效,用来快速处理相对简单且重复的任务(如合同、发票识别处理、电商内的图片搜索、AI客服等)。
换言之,亚马逊的自营模型目前对拉动营收增长的作用应当很有限,但可能体现在成本、费用的压缩上。
小结:当前亚马逊在云业务上的综合实力有从落后者重回领跑的迹象,其在MaaS业务上的领先是最大亮点;在芯片能力上,亚马逊实际也有完善的产品线布局。虽目前按已发布的版本性能,相比Google TPU仍有一定差距,但正在快速解决。
大模型能力上,虽然仍差距明显,但凭借和Anthropic的深度合作,在中期内算是能起到曲线救国的作用。
因此,亚马逊的AI综合实力其实并不算很弱。后续,海豚君将继续梳理、探讨其他云公司的AI能力和布局,并在最后尝试给出一个行业性的整体判断和具体公司偏好,尽请期待。