
本文来自微信公众号: 夕小瑶科技说 ,作者:夕小瑶编辑部,原文标题:《Claude Sonnet 5 发布,性能接近 Opus 4.8,价格只有60%》
Anthropic又发新模型了,Claude Sonnet 5。
Sonnet系列里最强的agentic model,也是新一代主力模型。
按照Anthropic的定位,Sonnet 5面向的是日常高频工作流,主打编码、工具调用、浏览器/终端使用、规划、知识工作。
老规矩,先看下模型表现。
Sonnet 5比Sonnet 4.6提升明显,很多指标已经贴近Opus 4.8。
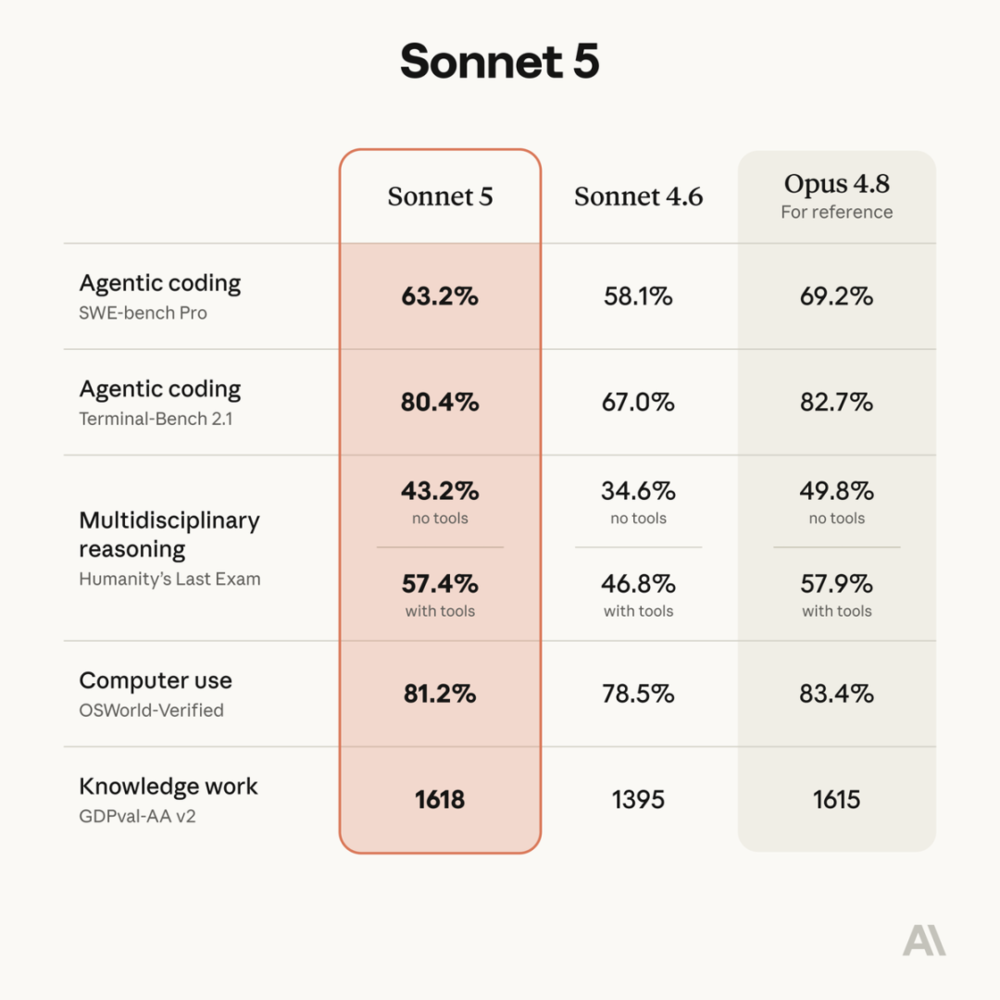
在agentic coding上,Sonnet 5的SWE-bench Pro得分是63.2%,高于Sonnet 4.6的58.1%,距离Opus 4.8的69.2%还有差距。
多学科推理也有明显提升。
Humanity’s Last Exam不用工具时,Sonnet 5是43.2%,Sonnet 4.6是34.6%,Opus 4.8是49.8%。
开工具之后,Sonnet 5直接到57.4%,已经非常接近Opus 4.8。
计算机使用能力也有进步。
OSWorld-Verified上,Sonnet 5是81.2%,Sonnet 4.6是78.5%,Opus 4.8是83.4%。
同时,单任务成本Sonnet 5的曲线已经贴近Opus 4.8,API价格更低的情况下,Sonnet 5或可以作为Opus 4.8的替代选项。
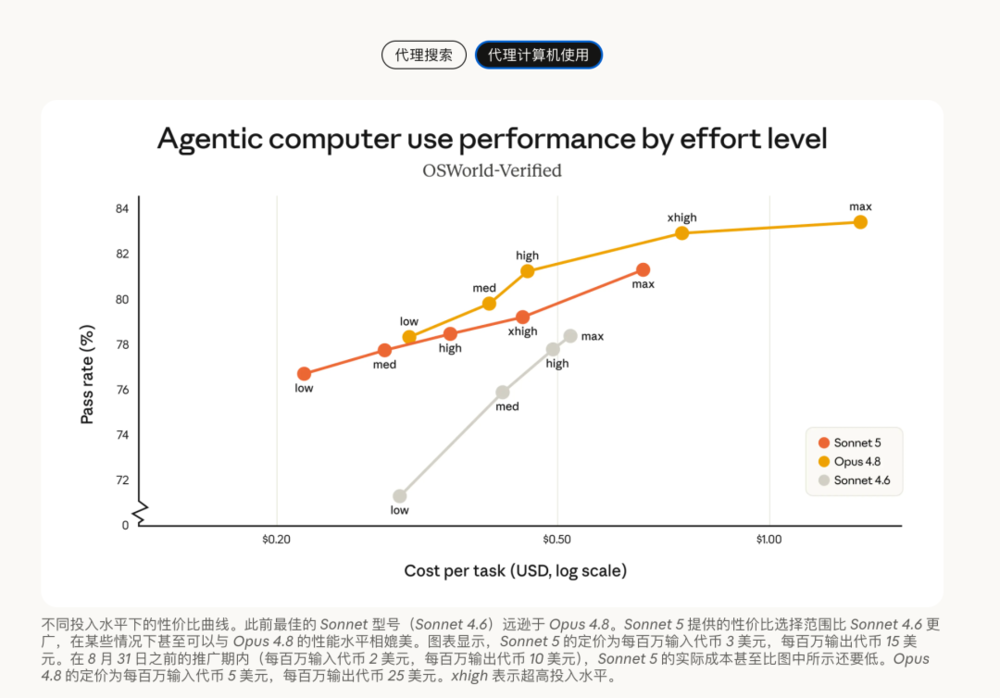
这对应浏览器、桌面、终端这类操作场景。对AI agent来说,这类能力比普通聊天重要得多。
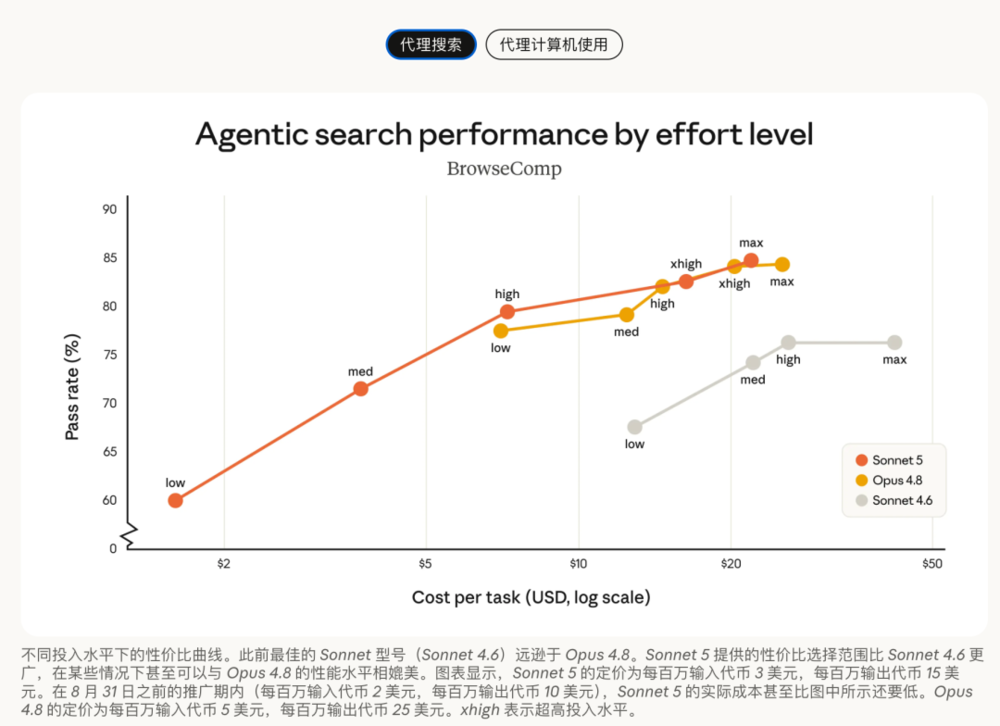
Agentic search搜索任务下,Sonnet 5在high/xhigh/max档,也是接近Opus 4.8的表现。在部分effort档位上,Sonnet 5用更低成本拿到接近Opus 4.8的效果。
再看第三方榜单。
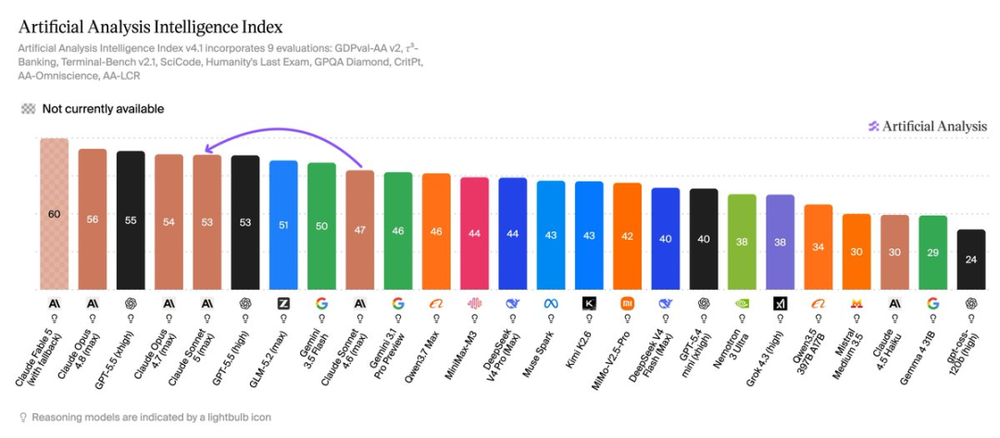
Artificial Analysis Intelligence榜单排名结果里,Claude Sonnet 5 max得分53。
这个分数和GPT-5.5 high同档,低于Claude Opus 4.8 high、GPT-5.5 xhigh、Claude Opus 4.7 max。
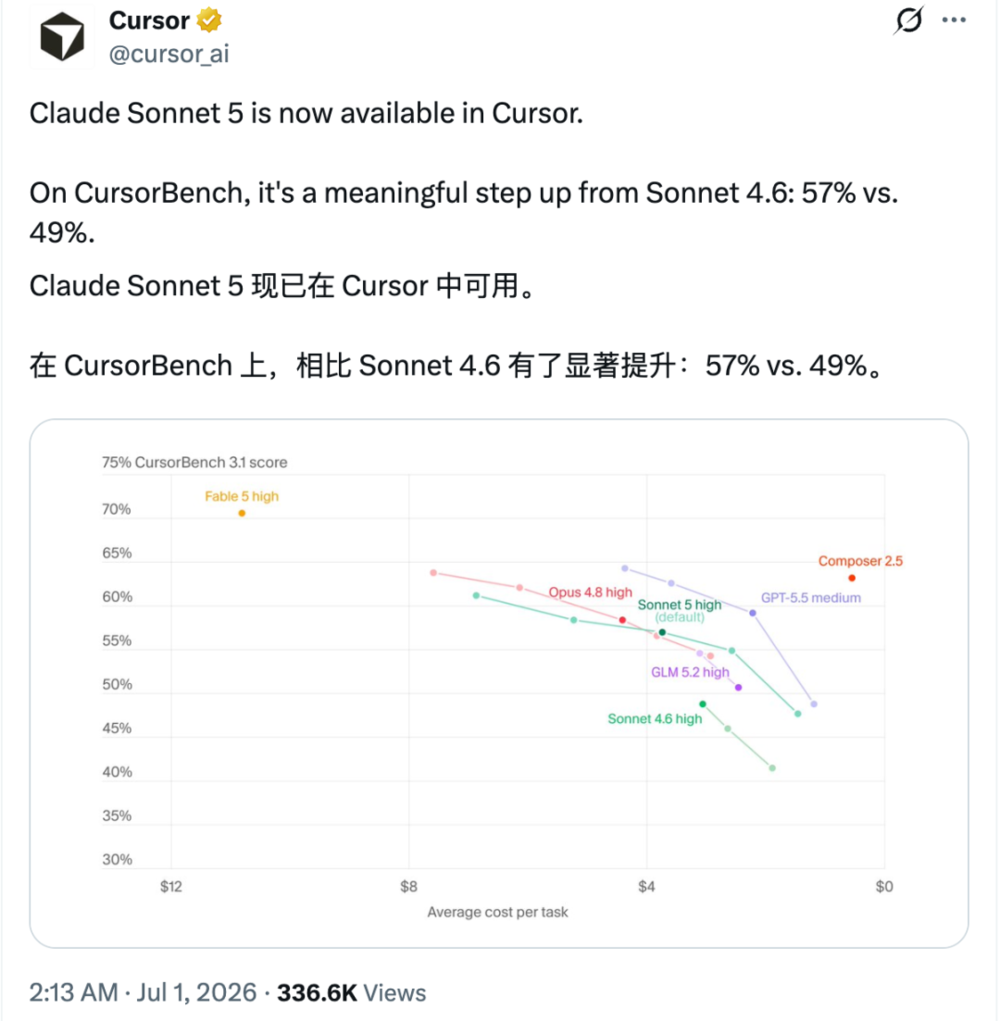
Cursor官方宣布,Claude Sonnet 5现在已经在Cursor中可用。
同时他们给了一组CursorBench 3.1数据,Sonnet 5是57%,Sonnet 4.6是49%,相比Sonnet 4.6是明显升级。
Sonnet 5 high default的位置,在CursorBench 3.1上已经接近Opus 4.8 high,但平均单任务成本更低。
Sonnet 5的标准价格是Opus 4.8的60%,发布初期还有更低的优惠价。
2026年8月31日前,Sonnet 5的价格为每百万输入token 2美元、每百万输出token 10美元,约为Opus 4.8的40%。

有推特网友跑了一个对比case,通过CLI在UltraCode模式下运行了Opus 4.8和Sonnet 5两个模型,任务是给Sonnet 5构建一个单一HTML登录页面。
效果明显Opus 4.8更胜一筹,但是Sonnet 5速度更快、花费更少。
Claude Sonnet 5:
tokens使用量:20.9k输入,14.2k输出
总成本:3.36美元
耗时:2分11秒
Claude Opus 4.8 Ultracode:
tokens使用量:96.3k输入,73.8k输出
总费用:20.66美元
经过的时间:20分15秒
但是另一组数据表现相反。
按Cost per Intelligence Index Task算,Claude Sonnet 5 max单任务成本是2.29美元,Claude Opus 4.8 max是1.80美元,GPT-5.5 xhigh是1.03美元,GLM-5.2 max是0.48美元。
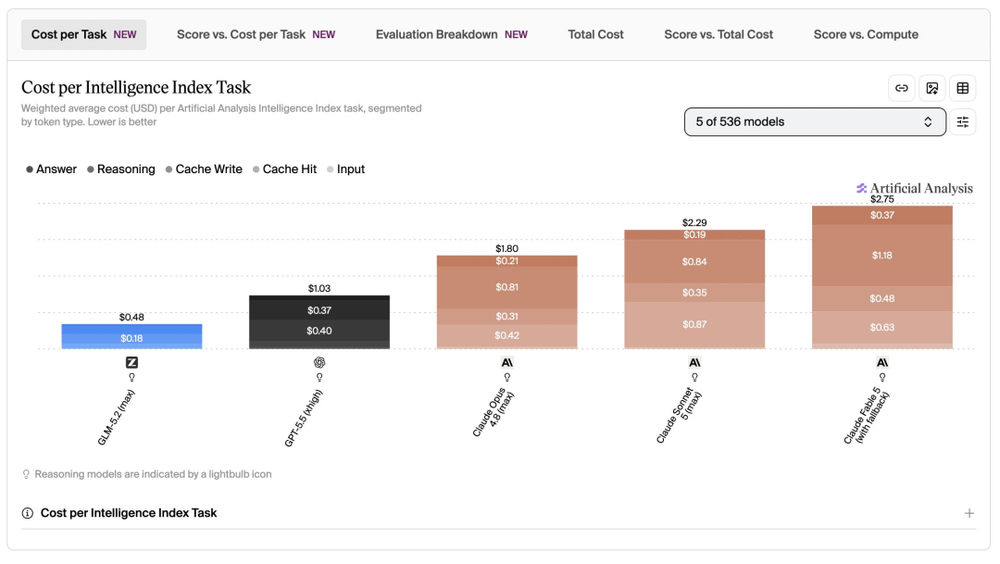
这说明一件事,不能只看API单价。
Sonnet 5的标价低于Opus 4.8,但在具体benchmark任务里,实际成本还会受输出量、推理量、缓存和调用方式影响。
这次Sonnet 5也是全平台上线,直接被推成主力默认模型。
Claude Free和Claude Pro用户默认模型会切到Sonnet 5。
Max、Team、Enterprise用户也能用。
Anthropic同步上调了Chat、Cowork、Claude Code与Claude Platform的速率限制,以适配更高effort等级带来的token消耗。
另外,Claude API、Claude Platform on AWS、Amazon Bedrock新Messages API、Google Cloud、Microsoft Foundry preview等平台都可以使用,基本覆盖现在主要的企业和云平台渠道。
开发者侧,Claude Code和Claude Platform API都支持Sonnet 5。
上下文窗口也直接拉满。
Sonnet 5默认支持1M token context window。
这对agent任务很关键。长任务里不只是要塞很多资料,还要保留过程状态,比如改过哪些文件、跑过哪些命令、哪些方案已经失败、用户补充过什么限制。
需要注意的是,Sonnet 5启用了更新后的分词器(tokenizer),同样的文本会被切成更多token。
Anthropic也表示促销价的设计意图,是让从4.6迁移到5的实际成本「大致持平」。
安全方面,Anthropic的安全评估显示,Sonnet 5整体优于Sonnet 4.6:
在代理安全方面,它更善于拒绝恶意请求、抵御提示注入(prompt injection)中的劫持企图,幻觉率与谄媚(sycophancy)倾向也更低。
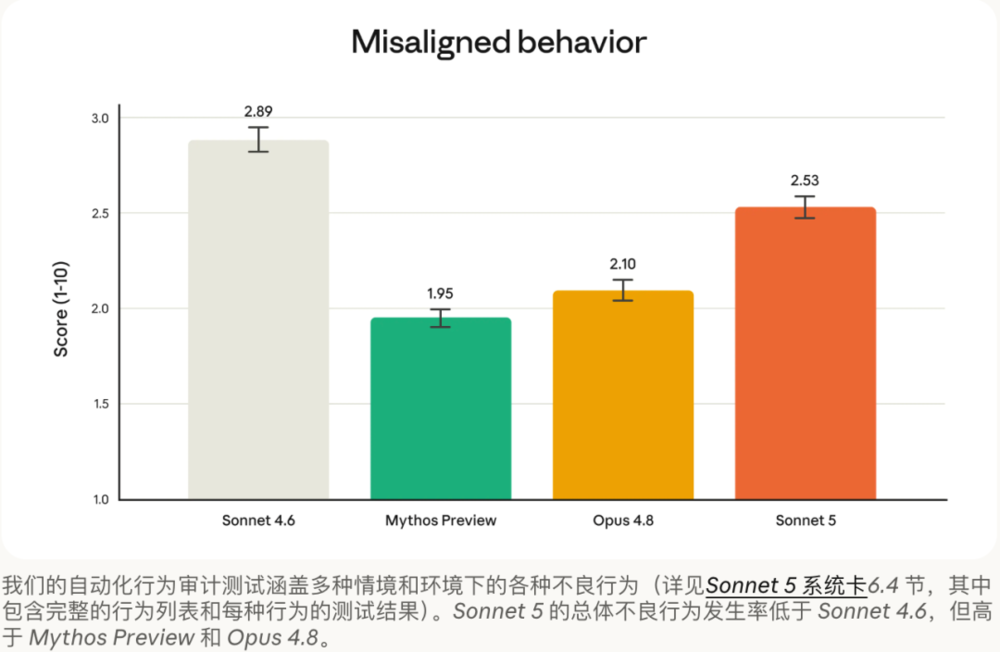
在覆盖广泛失准行为的自动化行为审计中,Sonnet 5的总体得分更「安全」。不过相比能力更强的Opus 4.8与Claude Mythos Preview,它在该项评估上的失准行为率仍略高一些。
Sonnet 5的定位很清晰,让agentic能力从必须上贵模型变成中端模型即可。
对成本敏感、又需要稳定执行多步任务的团队,它大概率会成为新的默认选项;而真正吃准确率的高难任务,Opus 4.8仍是首选。