
本文来自微信公众号: 深思圈 ,作者:Leo,原文标题:《今天刚听完的硅谷 AI 工程师实践分享:AI agent 到底怎么才算真正落地》
今晚,我在旧金山Howard Street的Inngest总部,参加了一场叫做{AI}in Production的小型聚会。主办方是Inngest,Cursor、Arcade、Vapi联合参与。清一色是在一线真正跑AI agent的工程师和创始人,一群人坐在一起,讲他们把AI部署进生产环境之后遇到的真实问题。
这种氛围让今晚的内容特别值钱。我记录了其中两位演讲者的内容,一位是Cursor的Strategic GTM Kash Yechuri,一位是Inngest的Head of DevRel Sterling Chin,讲的东西都很落地,有数据,有案例,也有坦承自己还没解决的难题。我把今晚最有共鸣的观点整理下来,也加上我自己的一些判断。
我一直有这样一个感受:真正的变化,不是从大型峰会的主题演讲里能感受到的,而是从这种小房间里工程师的真实对话里才能看到。今晚正是这样。
AI开发的三个阶段:你现在在哪里
Kash一开场就画了一条清晰的线:软件开发的AI化,正在经历三个阶段的演进。理解自己在哪个阶段,是判断下一步该怎么做的前提。
第一阶段是大家都熟悉的AI辅助阶段。你用Copilot补全代码,用Claude写文档,用ChatGPT回答技术问题。在这个阶段,AI是工具,人是主导。每次交互都是你主动发起的,AI给你一个建议,你决定要不要用。这个阶段门槛低,效果也确实好,大部分开发者都在这里待了很长时间。
第二阶段是"照看AI agent"阶段。你开始把更复杂的任务交给AI agent去做,但你不能离开电脑。它跑偏了你要拉回来,它卡住了你要推它,它做完一步你要确认一下再让它继续。这个阶段很耗精力,因为你既没有解放双手,又没有在做真正有价值的决策,你只是在"管理"一个不太可靠的系统。Kash用了一个很生动的说法:这就像在照看婴儿,你一秒都不能走神,但其实没做什么真正有意义的事。
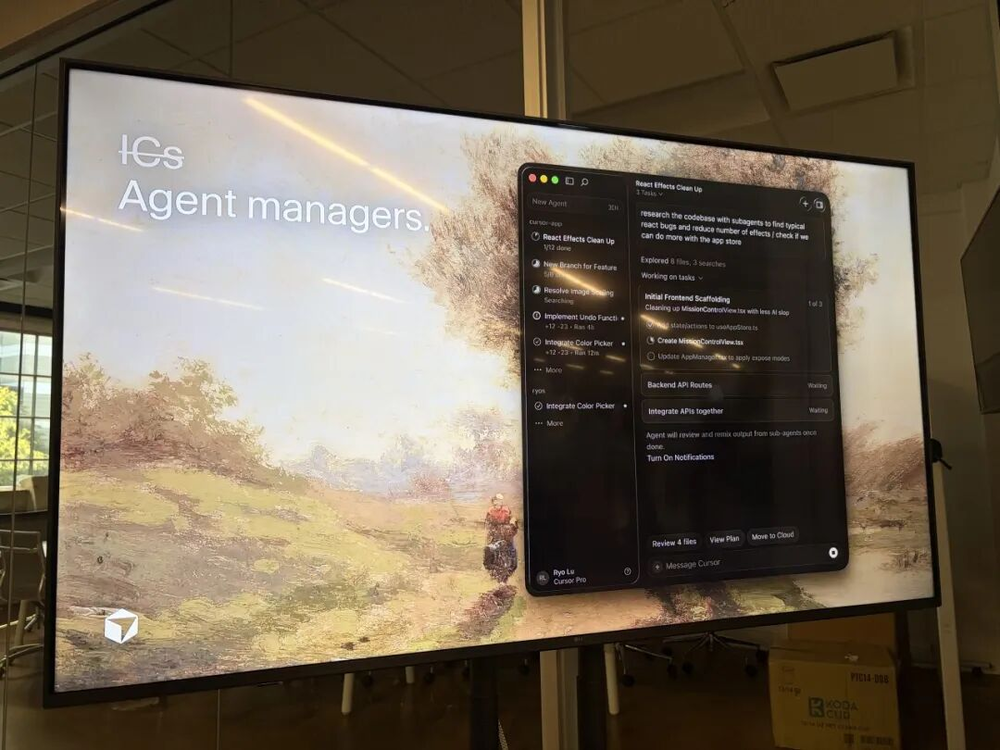
第三阶段才是真正有意思的地方:AI agent团队在后台自主运行。你给它设一个触发条件,比如"有新的issue提交了就去分析",然后你去做别的事。agent会在它自己的计算环境里工作几个小时甚至几天,做完了再来找你。你的角色变成了:只在最关键的决策节点上出现,其他时候放手。
我坐在台下听到这个框架的时候,第一反应是:大多数人以为自己在用AI agent,其实还停留在第二阶段。他们以为在驾驭AI,其实只是在照看一个需要不断被推动的系统。真正的agent时代,是agent可以在你不在的时候继续工作,而不是你一转身它就停下来等你。
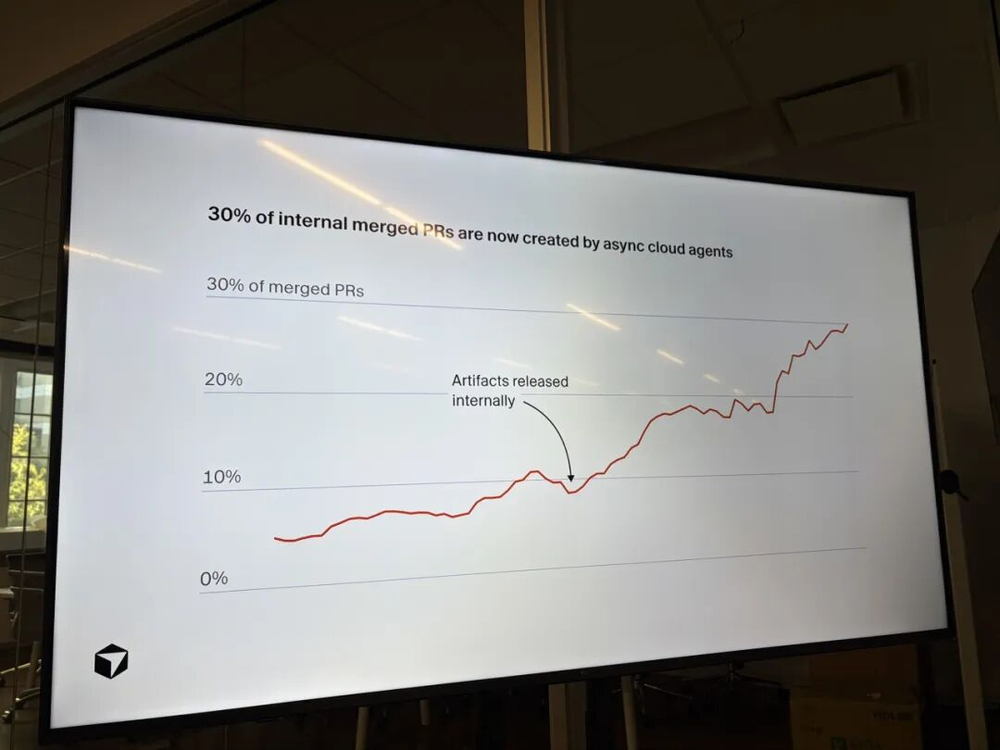
Kash给了一组Cursor内部数据,让我印象深刻。他们现在有30%的PR是由AI agent自动完成并提交的,整个过程没有任何人工干预。一年前,企业客户中使用云端AI agent的比例大概是15%到20%,现在这个数字已经到了75%。这个增速,比我预期的还要快。这不是未来的趋势,这已经是正在发生的现实。而且这个数字不是来自初创公司,而是跨越了初创公司和大型企业的整个用户群体。
工程师的角色正在变
演讲过程中,台下举手的一幕让我印象深刻。Kash问:有多少人现在花在review代码上的时间,比花在写代码上的时间还要多?台下几乎所有人都举了手。
这不是个人感受,这是整个行业的结构性变化。AI生成代码的速度远超人工,但生成出来的结果需要人来判断对不对、合不合适、符不符合架构意图。所以review的工作量在上升,而写代码本身退居次要位置。这个变化乍一看是好事,但它带来的挑战比表面上看起来要复杂得多。
Kash提到,从token消耗的分布来看,工程师现在大量的精力都放在了"写完代码之后"的环节上:review、验证、测试、调试。这背后有一个清晰的逻辑:AI生成代码很快,但快速生成出来的东西不一定正确,也不一定能跑,也不一定符合产品意图。"写完代码"只是起点,后续的验证反而成了新的瓶颈。
随之而来的是一个具体的问题:PR在变大。AI agent一次性改动的文件越来越多,生成的PR越来越巨大,review的难度直线上升。Kash把这种PR叫做"mega PR",他们做了一些任务拆分的尝试,但承认这只是缓解,没有从根本上解决review压力。这个问题,我觉得整个行业目前都还没有特别好的答案。
我自己对这一点有很真实的体感。用AI写代码,最大的陷阱不是AI写错了,而是AI写得太快,你根本没时间跟上它的节奏。你以为在提速,实际上在积累技术债。等某天需要修改某个地方,你会发现那段代码完全陌生,因为不是你写的,你也没有认真review过。这种"速度幻觉"是我见过很多团队都在经历的困境。
所以我认为,在AI时代,工程师最核心的能力不再是"写代码的能力",而是"判断代码好坏的能力"。你要能快速识别AI生成的代码是否符合架构意图,是否有潜在的性能问题,是否有安全漏洞。这种判断力反而更难培养,因为你不再有机会通过大量手写代码来积累经验,但你又必须具备这种能力才能真正驾驭AI的输出。
还有一个让我觉得很实用的观察:不同的模型在不同任务上的表现差异很大。Kash提到,某些模型在做整体架构思考和大局规划上表现更好,另一些在细节执行和任务拆解上更擅长。这不是在说哪个模型更好,而是说在搭建AI agent团队的时候,你需要根据任务类型来选择合适的模型,而不是用一个模型包打天下。这种"用人所长"的思维,放到AI agent身上同样适用。
40%的生产力天花板,背后是什么
Kash分享了一个让我很感兴趣的观察:很多开发者用上AI agent之后,生产力提升会稳定在40%左右,然后停在那里不再增长了,甚至会开始对AI的输出越来越怀疑。这个"40%天花板"不是个例,是跨越很多公司都能观察到的现象。
为什么会卡在这里?Kash给出的解释是:这是同步AI agent的根本限制。所谓同步agent,就是你得在场:agent做一步,你确认一下,agent再做下一步。这种模式下,你的注意力就是整个系统最大的瓶颈。agent再快,也快不过你处理信息、做出判断的速度。你没有被解放,你只是换了一种方式被绑定。
打个比方,就像你雇了一个助理,但要求他每做一件事都来问你一次。你在不在场,决定了助理能不能动。这不叫提效,这叫换了个角度让你忙。
当你转向异步AI agent团队,情况就不一样了。agent可以在后台并行处理多个任务,你不需要全程盯着,只需要在关键节点做决策。Cursor内部就是这么实践的:AI agent自动分析issue,自动生成对应的PR,自动tag相关负责人,但最终merge PR的决定还是由工程师来做。agent做agent擅长的事,人做人擅长的事,两者配合,才是真正的提效。
但异步AI agent也带来了新的麻烦。Q&A环节,有人提到了一个非常实际的挑战:当你并行跑多个AI agent,每个都在修改同一个代码库,最后merge PR的时候,冲突会变得极其复杂,review压力成倍增加。有时候agent会因为之前的merge而进入"过时状态",之前做的工作全都白费了。这不是小问题,这是multi-agent工作流里目前最棘手的工程难题之一。
把AI agent真正部署进生产环境
今晚第二位演讲者是Inngest的Head of DevRel Sterling Chin,他分享了一个在我看来非常关键的概念:durable agent,也就是有持久性、能从失败状态恢复的AI agent。他的核心观点是:把AI agent跑在本地是一件事,把它真正部署进生产环境是另一件事。这两件事之间,有一道很大的鸿沟。
Sterling给durable agent的定义非常简洁:一个能从失败状态恢复的agent。这听起来简单,但在生产环境里非常难做到。失败的原因千奇百怪:LLM的API超载了,某个第三方服务挂掉了,网络中断了,某个步骤的输出格式不符合预期。而传统的处理方式,是整个任务重新跑一遍。这不仅浪费时间,也浪费成本,更重要的是在某些场景下根本不可行,因为有些步骤是有副作用的,跑两遍会出问题。
我在台下看到这个demo的时候,第一反应是:这其实和分布式系统里的checkpoint机制是同一个思路,只不过保存的不是计算状态,而是AI agent的执行进度。很多软件工程里的经典难题,在AI agent时代以新的形式重新出现了。这让我觉得,那些在传统工程领域有深厚积累的人,在AI agent这个新领域会有很大的优势,因为他们见过这些问题,知道解法的方向在哪里。
从更大的视角来看,这背后是一个关于human-in-the-loop的设计哲学。人工参与不是AI agent的缺陷,而是现阶段AI能力边界的必要补充。关键问题是:你怎么把这个人工参与的过程做得不那么痛苦,不那么打断工作流,不那么让人觉得在给AI擦屁股。Sterling和Inngest的这些设计,本质上都是在回答这个问题。
让agent可信,比让agent聪明更重要
今晚让我思考最多的一个问题是:我们距离真正信任AI agent,还有多远?
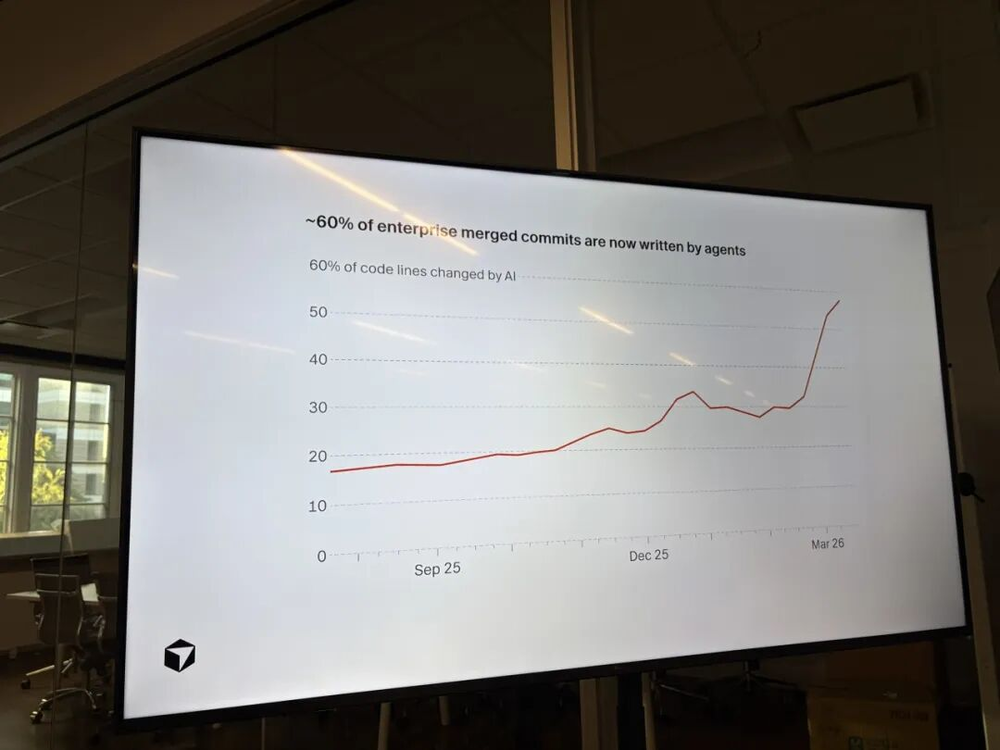
Kash提到了一组数据:Cursor内部现在有60%的代码是由AI生成的,内部准确率超过98%。这个数字听起来很高,但在软件工程里,2%的错误率依然可以是灾难性的。如果你有一个每天执行一万次的任务,2%的失败率意味着每天有200次失败。这种规模下,你愿意接受吗?很多团队在小规模时觉得没问题,但规模一上来,问题就会被放大。
所以,信任AI agent不是一个全有全无的决定,而是一个基于场景、基于风险做出的精细化判断。对于低风险、可逆的任务,可以让AI agent完全自主运行。对于高风险、不可逆的任务,就需要在关键节点插入人工确认。这个度的把握,本身就是一门学问,也是工程师在AI时代需要练就的新能力。而且这个判断不是一劳永逸的,随着模型能力的提升,边界会不断移动。
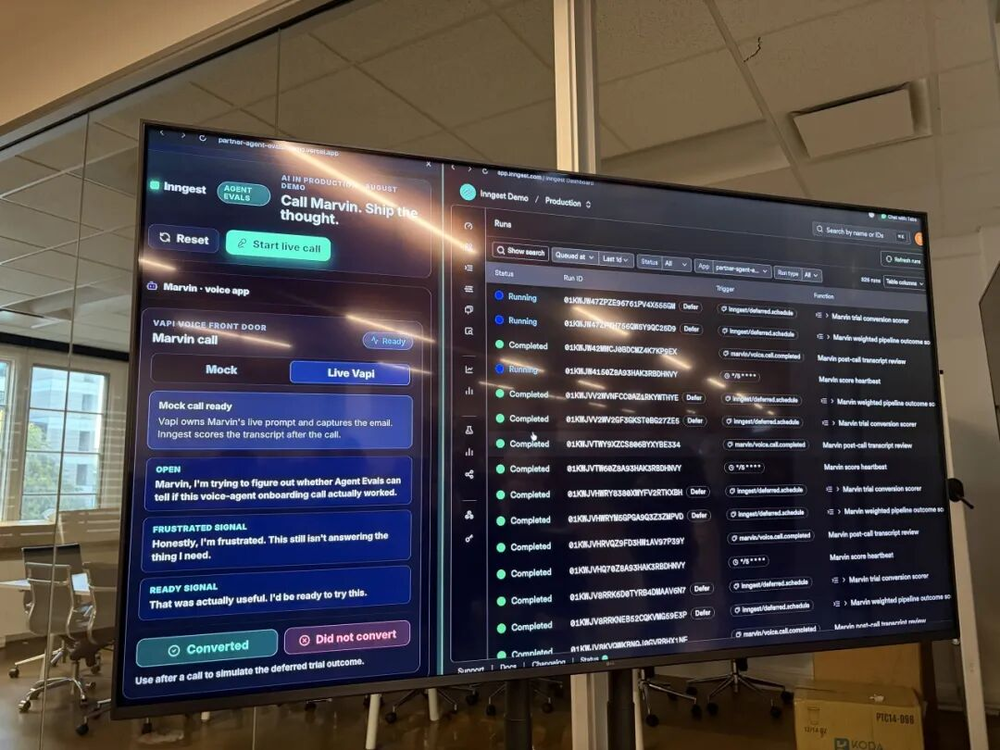
我一直觉得,可观测性是AI agent进入生产环境里最被低估的基础能力。大家都在卷agent能做多复杂的任务,能解决多难的问题,但很少有人认真想过:当agent出了问题,你怎么知道哪一步出了问题?你怎么快速定位原因?你怎么防止同样的错误再次发生?这些问题,在传统软件工程里有成熟的答案,但在AI agent领域,整个生态还处于非常早期的阶段,工具链还很不完善。
Q&A环节里,有人问了一个关于测试的问题,让我觉得很有代表性。一家做IoT硬件产品的小团队说,他们最大的瓶颈就是测试,因为真实硬件在物理环境里的测试根本没办法完全交给AI来做。Kash的回答是:对于这种情况,可以让AI agent负责"返回一个测试演示",就像给你展示这是app的当前状态,这是我测试过的几个路径,这是测试结果,然后由人来做最终的验收判断。AI agent不一定要完全接管测试,而是可以把测试结果整理好、可视化好,大幅降低人工验收的难度和时间成本。这个思路,我觉得对很多有硬件或特殊环境约束的团队都有参考价值。
我对这一切的思考
离开聚会走在旧金山街头,我脑子里一直在转一个问题:在AI agent时代,工程师的核心价值究竟是什么?
我的答案是:工程师的价值,会越来越集中在"定义问题"和"设计系统"上,而不是"解决问题"和"写代码"上。这个转变,听起来像是好事,但它对工程师的要求其实更高了,只不过高的维度变了。
今晚Kash提到了一个值得反复思考的转变:以前我们问的是"我们想让AI agent做什么",现在更应该问的是"我们想让人做什么"。这两个问题看起来只是换了角度,背后的含义完全不同。前者把AI当工具,后者把AI当协作者,重新思考人在整个系统里的位置。这个视角的切换,是很多团队还没有真正完成的转变。
在软件开发的各个环节里,AI agent现在可以处理很多事:收集用户反馈、做市场调研、探索可能的解决方案、写代码、跑测试、生成并提交PR。但有些事情,至少在现阶段,还需要人来做:决定做什么功能,判断架构是否合理,评估输出是否符合产品意图,在关键节点做最终决策。这些事情的共同点是:它们都需要对"我们在做什么,为什么做"有深刻的理解。这种理解,不是AI能替代的。
这不是说工程师可以松口气了。恰恰相反,对工程师的要求在某些维度上变得更高了。你需要更强的系统设计能力,因为你不只是在设计代码结构,你在设计AI agent团队的协作方式。你需要更强的判断力,因为你要在海量的AI输出里快速识别哪些好、哪些有问题。你还需要更强的产品感,因为很多以前留给工程实现的空间,现在被AI填满了,工程师需要更深地参与"我们到底要做什么"这个层面的讨论。
今晚这场聚会让我想到一件事:硅谷的工程师文化里有一种务实的态度,叫"show me the code"。但现在,这个文化正在悄悄演变成"show me the agent"。大家不是在聊AI可以做什么,而是在聊"我已经把AI部署进生产环境了,遇到了什么问题,怎么解决的"。