范阳
2023-12-11

我相信这一轮人工智能的发展,最大的推动作用和社会价值会是让我们的科学继续进步 ( AI4Science ) ,打破过去几十年停滞的局面,从而创造全新的技术。而要进一步开发出来强大,高效而通用的人工智能 ( AGI ),人们也需要继续用科学的方法 ( Science4AI, 物理学,数学,化学,生物学,认知科学等等)去理解和启发 AI,虽然它最后可能会超过我们所有的科学和智能形式本身( alien science & intelligence )。
除了少数科技大公司和明星创业公司的喧嚣,越来越多的跨学科科学家和研究人员,开始着手解决当下人工智能领域最难的问题,比如在GPU, transformer 和深度神经网络( DNN ) 还有缩放定律( scaling law ) 这些既定的基础之外,是不是还值得以及有可能发现更 “聪明”,更可以理解,和每个个人都可以与之合作的人工智能?是否还需要从底层原理上发明更好的 “计算” 范式?
今天分享的这篇英文文章来自美国红杉资本的博客( 原文链接在文末 ),作者是丹-罗伯茨( Dan Roberts ),他是红杉资本的人工智能研究员( AI Fellow at Sequoia Capital )和麻省理工学院理论物理学研究员(a Research Affiliate at the Center for Theoretical Physics at MIT )。他联合创立了 Diffeo 公司,之前被 Salesforce 收购,他还是《 深度学习的理论原理 》( The Principles of Deep Learning Theory )一书的合著者。
这篇文章更多像是一个思想实验:人工智能( AI ) 的物理学基础是什么,通用人工智能 ( AGI ) 物理上的极限在哪里,从这个视角再去思考从第一性原理出发,是否一定需要创造全新的人工智能基础架构。
希望对你有启发。
如果你相信 AI / AGI 的进步会帮助解开生命科学,神经科学,认知科学等等领域的高阶谜题,以及也在从事多学科交叉领域的前沿科研,工程或者投资,期待我们一起喝杯咖啡交流,我的微信:2871981198,请注明来意。

作者:DAN ROBERTS
编辑:范阳
写作日期:2023年12月7日
无论最终是好是坏,物理学家都会试图用物理学来理解那些显然不是物理学范畴内的东西( physicists will try to understand things that are not obviously physics )。
我作为一名从物理学家转变为人工智能领域的创始人和研究者(a physicist-turned-AI-founder-and-researcher),我喜欢把黑洞想象成计算机( 从某种意义上说,黑洞是最大的,也可能是最快的一种计算机 )。在这篇文章中,我们将考虑一些非常特殊的计算机是否会在成为神之前,就变成黑洞。

范阳注:在今年科学家发现了迄今为止可以理解的最大的黑洞,它位于 Abell 1201 星系团当中的一个星系当中,宽度是 300 亿个太阳直径。
早在科幻小说这一特定类型出现之前,人工智能就已经是推理小说( speculative fiction )的一部分。人工智能也是计算机科学的一部分( 尽管不完全是 ),人工智能的历史(几乎)与有计算机的历史一样久远。1956 年,达特茅斯研讨会“为研究像人类一样思考的机器”( the study of machines that think like humans )创造了 "人工智能 " 这一名称,并计划在一个夏天内完成这项任务。当然现实是这个任务没有如期完成。
人工智能发展的一个奇特之处在于,人工智能作为一门科学远远落后于人工智能作为一项技术( the science is far outpaced by the technology ): 人工智能仍然是一个 "黑盒子",它能够产生魔法般的结果,如赢得与人类的围棋比赛、扑克中的虚张声势、写出有情感的诗歌、引人入胜的故事和令人惊叹的图像。我们很容易读到关于如何构建这样一个系统的信息,虽然如果没有大量的资金和工程人才,要想真正做到这一点还真不容易。但没有人知道,比如说,OpenAI 的 ChatGPT 这样的聊天机器人在给定特定提示时,生成这个句子而不是那个句子。
但如果人工智能是魔法,那么它实际上理应可以做任何事情 …… 在逻辑可能性的范围内。这些可能性包括,根据一些日益成为主流观点的人的说法:消灭地球上的所有生物生命。
我们如何评估这些说法呢?如果人工智能是一个黑匣子,我们怎么知道什么是可能的?我们如何将科幻的套路与科学的真理区分开来?
首先,我认为人工智能系统并不是黑盒子,我们可以像理解其他物理系统一样,通过物理学来理解人工智能系统!
好吧,你可能会说,实现 ChatGPT 的抽象 AI 模型,与房间内气体的热力学有什么关系( the thermodynamics of the gas inside a room )?
( 我想说的是,你选取了热力学第二定律这一物理学现象做对比,真是有趣又聪明!)
为了确定房间内集体气体的性质,它的热力学特性,从约 10^25 ( 约等于10,000,000,000,000,000,000,000,000,000 )个左右的气体分子的基本运动 — 它们的统计力学 ( statistical mechanics ),我们需要物理直觉和一套数学工具( physical intuition and a set of mathematical tools )。总体而言,这些工具让我们能够从微观世界视角( 我们追踪它们的个体位置和速度 )放大到认识宏观世界特征 —— 如温度、体积和熵。
另一种微观复杂系统( microscopically complicated system ), 是最近成功的人工智能模型所基于的深度神经网络( deep neural network, DNN )架构。这些模型通过采用一种简单但可编程的数学操作 — 人工神经元( artificial neuron ), 将它们排列成层,以并行执行许多此类操作,然后将许多层堆叠在一起,以获得一个复杂的函数,如果被要求的话,这个函数可以按照莎士比亚的风格写出一出证明质数无穷大的戏剧( write a play proving the infinitude of primes in the style of Shakespeare )。在这种情况下,DNN 的微观描述就是人工智能程序员编写的文字代码 ( the literal code that the AI programmer writes ),指明输入如何转换为输出。
对于语言模型( language model ),文本被分解为称为 tokens 的片段,它们大致对应于单词 / 词块的意思;每个 token 被映射到高维向量( each token is mapped into a high-dimensional vector );高维向量的序列根据在训练过程中学习到的模型参数的精确数值,以各种方式进行混合、重新加权和偏置;最后,模型根据输入确定所有可能的下一个单词的概率分布,并通过从该分布中采样生成一个新单词。然而,该代码只回答了 "如何 " 的问题 ( the how question ) — 如何根据该输入计算出输出结果,却没有回答 "为什么" 的问题( the why question )— 为什么对该输入是这样的输出结果而不是其他输出结果?
这种对聊天机器人工作原理的描述,就像以下( 从微观世界 )思考气体所施加的压力的方式:压力是力在单位面积上的作用;每个单独的气体分子在每次与墙壁随机碰撞时都对墙壁施加一个力;因此,我们可以通过跟踪房间中每个气体分子的位置和速度,追踪它们与墙壁的碰撞,并累加所有力来理解压力。类似地,这回答了气体的 “如何” 的问题 — 压力是如何产生的。但没有回答 “为什么” 的问题 — 为什么温度升高时压力就会上升呢?
为了回答 “为什么是这样” 的问题( the why questions ),我们发现 — 需要明确的是,这里的 “我们” 指的是历史上的物理学家们 ( historical physicists ) — 对于某些类型的微观复杂系统,随着系统基本组成部分数量的增长,会出现简单的宏观描述( simple macro-level descriptions emerge ), 例如,我们可以通过研究气体的速度分布,推导出理想气体定律,并证明压力与温度成正比。
此外,我们历史上的物理学家还能够对这些简单描述进行迭代改进,以理解改变这些系统大小如何改变它们的行为。通过这种方式,我们可以系统地建模与理想气体定律的偏差(systematically model deviations from the ideal gas law )。事实证明,作为一个具有大量基本组件的复杂系统 ( a complicated system with a large number of elementary components ),深度神经网络也具有确切的属性,使得这种受物理启发的方法( a physics-inspired approach )能够帮助我们理解它们为什么会以这种方式工作。
作者注:延伸阅读可以参考这篇文章 Why is AI hard and Physics simple?
https://arxiv.org/abs/2104.00008
以及:https://deeplearningtheory.com
但以上只是对物理学的一种类比。在超级计算机上模拟人工智能时,物理学的重要性也是显而易见的。
要想知道为什么,请考虑一下,当我们 — 这里的 “我们” 指的是 OpenAI 的员工 — 构建 ChatGPT 时,我们需要一个物理对象( a physical object )来包含 ChatGPT 的参数,控制网络中人工神经元行为的权重和偏置,从而定义和实现 ChatGPT,并让它们可用来处理输入提示。这个物理对象被称为图形处理器( graphics processing unit, GPU ),每个 GPU 都有固定数量的内部内存,用于存储人工智能模型的参数。
要训练并运行像 ChatGPT 这样的前沿人工智能系统,你必须利用的不是一个,而是许多这样的 GPU,它们被组织在一起,形成一种超级计算机( supercomputer ):8 个 GPU 组合在一起,连接在一种叫做 GPU 节点 ( a GPU node )的盒子里,这样它们就能高速通信,然后 GPU 节点进一步堆叠,连接在一起,形成一个 GPU 集群( a GPU cluster ),这个集群位于一个叫做数据中心的房间里。

我再多啰嗦两句,让我们想象一下包含运行 ChatGPT 的超级计算机的数据中心的那个房间也包含我们刚刚讨论过的气体热力学。任何足够年长以购买过 GPU 进行其最初目的 — 游戏— 的人都知道,GPU 配备了风扇,因为它们会产生大量热量。不用说,运行 ChatGPT 会极大地影响数据中心内的气体热力学。


范阳注:未来支持超级人工智能的超级计算和数据中心会消耗大量的电能,以及产生大量热能和温室排放,所以挪威这些北极圈国家也在建设绿色能源支持的数据中心。但这也会进一步影响我们的环境。
换句话说,人工智能系统是物理对象( physical objects ),人工智能推理是在物理空间中进行的。因此,所有所谓的超级智能( superintelligences ) 最终都会受到计算的物理学限制。这就是本文的主要观点。
为了理解这一论点的重要性,我希望你现在花一点时间想象一下一个具有无限计算资源访问权限的 AGI (通用人工智能)。对于那些担心这些 AI 系统可能对人类生存构成风险的人来说,这个思想实验通常等同于想象一个可以做任何事情的全能之神 ( all-powerful god )。例如:
a ) 它可能是一个信息先知( information oracle ) — 是谷歌的终极继承者,因为它将封装并推理关于人类知识的总和( encapsulate and reason about the sum total of human knowledge )。而且在提供答案时,它不会产生 “幻觉” 而虚构事实或信息来源。
b )它可以用来 "解决" 科学问题,创造我们难以想象的新技术。
c )它可以摆脱笔记本电脑的束缚,利用互联网合成人工生命( artificial life )。
作者注:这是 Yudkowsky 最近在《时代》杂志上的一篇文章中的一个例子,他在文中提到:“要想象一个有敌意的超级人工智能... 想象这是一个“外星文明”,以百万倍人类速度思考 ... 允许最初被限制在互联网上的人工智能,构建人工生命形式或直接引导到后生物分子制造( postbiological molecular manufacturing )。”
d )它可以通过精确模拟你,以至于你无法客观地知道你是物理存在的你( the physical you ),还是模拟的你( the simulated you ),从而将你困在笔记本电脑的限制之内 ... 然后折磨那个模拟出来的人,使你按照它的旨意行事。也许它会创造出十亿个这样的模拟存在,让你几乎可以确定,拥有主观意识体验的你也是被模拟出来的?
e )哈,我会在这里耐心等待,你可以向 ChatGPT 继续询问还要不要继续。
这个清单对你来说什么时候跳到了离谱的地步?对我来说,与其列举神的可能性,我更愿意从想象一个黑洞开始。
在任何物理系统的极端状况都潜藏着黑洞。试图把太多的东西( 物质或能量 )塞进任何固定体积当中,你会发现自己陷入了黑洞问题;试图聚集足够多的相同物体,你也会发现自己陷入了黑洞问题。虽然这可能并不直观,但这也在物理上限制了你在任何空间区域内的计算量。
为了理解为什么是这样,想象一下如果我们将我们的 AGI 系统朝着无限计算的方向进行扩展( if we scaled up our AGI system towards unbounded computation )会发生什么:随着我们假想的 AGI 变得越来越大,我们将需要越来越多的 GPU 来物理运行它。这意味着构建越来越多的 GPU 节点,并将它们连接在越来越大的 GPU 集群中。
那么,我们 — 这里的我们指的是任何人,无论是人类还是人工智能,究竟能制造出多大的 GPU 超级计算机呢?
在解开各种网线束缚并考虑限制时,让我们考虑一下经济限制、技术限制以及物理限制( physical limitations )之间的相互作用。
任何现在从事人工智能工作的人都知道,获取 GPU 非常困难,因此即使只是订购有限数量的 GPU,也仍然需要一段不确定的时间才能落地。当然,这些供应问题并不是建设事物的根本障碍,但它们确实指出了扩展过程中经济问题的核心( the heart of economic issues in scaling ):世界上究竟有多少资源可以用于训练一个单独的人工智能模型?
据估计,能够训练目前最先进的 LLM 的超级计算机( the cost of supercomputers capable of training the current state-of-the-art LLMs )的成本约为 1 亿美元。如果下一代计算集群的成本为 10 亿美元,还剩下多少代 “下一代” 呢?
当然,一些大公司( 如科技公司 )将有能力花费 100 亿美元做这些事情,但除此之外,全球只有约 150 家公司的市值超过 1000 亿美元,而今天最大的公司苹果公司,市值(仅)约为 3 万亿美元。除此之外,虽然美国政府可以调动比埃隆·马斯克( Elon Musk )更多的资源 — 尽管我们忽略将前沿人工智能努力整合到运作良好的政府机构中( incorporate frontier AI efforts into a functioning government institution )需要的几乎不可能的协调能力 — 1000 亿美元至 1 万亿美元是美国整体能拿出来的可能上限。
作者注:做个类比,美国国防部 2024 年的全部预算(仅)为 8,420 亿美元。
即使这样,想象一下,我们,这里的 “我们” 实际上指的是每个人,如果联合起来,将所有经济生产力投入到建设最大规模的计算机( building the biggest computer),直到它超过全球生产总值( gross world product,它在2022 年刚刚突破 100 万亿美元 ),仍然没有太多的上升空间了。总之,在经济的规模法则结束之前( the end of economic scaling ),非政府性商业公司的的计算迭代大约还剩 2-3 次( 例如,OpenAI 可以继续发布 GPT-6 或 7 ),或者说拿出全世界资源的计算迭代( all-in-world iterations left )还剩下 5 次。
暂且不谈经济效益的问题,原则上我们难道不可以继续让我们的超级计算机变得更快吗?顺着当前创新的梯度,我们可以看到这一加速战略在 GPU 层面和集群层面都在发挥作用,前者是在同一芯片上挤压越来越多的晶体管,后者是在越来越大的数据中心中将越来越多的 GPU 联网。然而,晶体管的缩小,和计算集群的增大的趋势是由技术突破驱动的。一系列的创新使我们能够设计更小的晶体管或者高效地为 GPU 集群供电和连接,不过这些创新越来越与基础物理上能到达的极限( fundamental limits of physics )发生冲突。
尽管我们不太容易像上面前两段那样进行上下文的粗略估算,但我们可以提供一些凭直觉的认识( give some intuition )。推动更快的 GPU 的灵感来自摩尔定律,其中之一的经验观察是芯片上的晶体管数量大约每两年翻一番,自 1965 年首次观察到这一现象以来,科技行业一直保持着这一趋势。
作者注:摩尔定律的另一版本 — 每两年晶体管数量以最低价格翻倍,已经结束了。
不幸的是,这样的观察现象可能会终止了:估计专业人士预测,硅制的晶体管( transistors made of silicon )在热环境中只能再缩小四倍,然后 GPU 将开始产生计算错误。
作者注:用技术术语来说,这是热力学波动开始占主导地位的尺度。
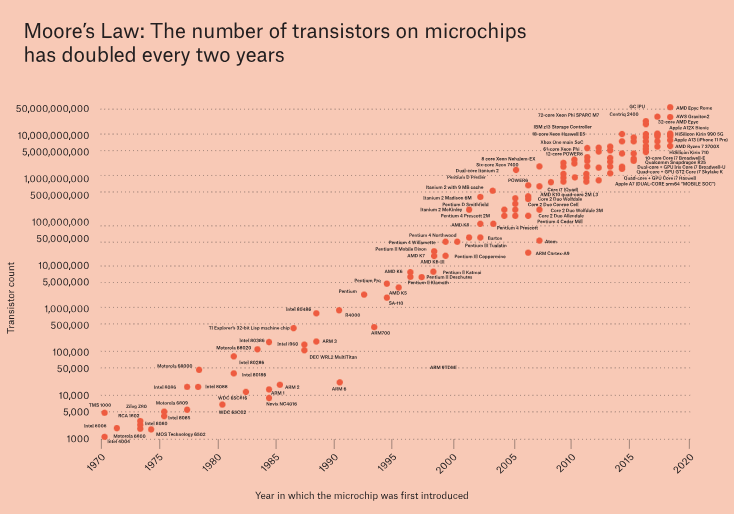
摩尔定律事实上已经结束,要制造出更大的计算集群,不仅仅是在越来越大的建筑物中堆叠服务器机架那么简单:每个节点都需要恰当的供电、冷却和互连。GPU 之间的互连是超级计算机的基本技术,因为为了为了使超级计算机大小的 AI 模型正常运行,每个 GPU 都需要与其他每个 GPU 进行通信。
作者注:好吧,这里有一些注脚式的粗略估算,一台最先进的 GPU 节点( Nvidia 的 DGX H100 )使用约 10 千瓦的功率;忽略数据中心的所有其他功耗,例如冷却,一百万个这样的节点( 800 万个GPU )的集群,大约比已知的最大 AI 集群大约 360 倍,让我们天真的标价约为 5000 亿美元 — 将需要在夏天消耗整个纽约市峰值的电量。生成和传输即使是这种下限的电量也将非常棘手。
但要注意的是,随着计算集群在地球上的物理占地面积越来越大,GPU 之间的典型距离也会随着占地面积的平方根( 如数据中心的典型线性维度 )而增长:因此,无论互连技术变得多么优秀,还是会感叹 "光速是糟糕的" ( the speed of light sucks ),延迟在任何超级大脑中都是不可避免的( latency is unavoidable in any superbrain )。
因此,在某个时刻( 也许很快的 )我们将达到芯片的 transformer 密度上限,将更多 transformer 密集的材料放在同一个房间可能不会帮到我们,因为该材料的不同部分将在空间上越来越分离,使其内部通信越来越困难。也许我们可以通过替换晶体管来解决前者的限制,例如从电子学转向光子学( move from electronics to photonics ),或者也许我们可以通过发明更好的分布式计算算法( inventing better distributed computing algorithms )来解决后者的约束?现在,作为计算领域的乐观主义者,假设我们 — 这里的我们指的是......你知道吗,我想这里的 “我们” 指的是真正的超级智能 AGI ( superintelligent AGI ),将整个经济的重心重新引导到进一步扩大人工智能这一单一目标上,将所有自然资源,也许甚至包括地球在内,都转化为 GPU,并解决上述技术限制。就算这样会发生什么呢?
还有一点不幸的是,来自一种更基本的物理学原理,这种类型的规模扩展( this kind of scaling )仍有一个极限终点:如果你把足够多的 GPU 放在一起,最终会发生一件非常令人惊讶的事情:它们会坍缩成一个黑洞!
作者注:更多的脚注式的粗略估算,Nvidia 的 DGX H100 服务器之一包含8个GPU,体积为 0.15 立方米,重量为 130 千克。与此同时,施瓦茨希尔德半径( Schwarzschild radius )Rs = 2GNM 将黑洞的质量与其半径联系起来,其中 Rs 是施瓦茨希尔德半径,M 是质量,GN = 6.67 × 10−11 m3 kg−1 s−2 是牛顿引力常数。如果尝试将足够的质量打包到线性尺寸 R足够小的区域,以使 R/M = 2GN,那么将形成一个黑洞。对于任何具有恒定密度的 N 个物体的集合,集合的质量与 N 成比例,但集合的半径与 N^1/3成比例。因此,R/M ~N−2/3,通过增加集合中物体的数量,将最终形成一个黑洞。
每台 GPU 服务器之间的引力都小得忽略不计,但是,如果你把大约 10^37 台 GPU 放在一起,引力最终会以一种非常严重的方式产生影响。
作者注:以 GPT-4 为例,它只是在大约 10^4 个 GPU 上进行了训练。我希望这一点是显而易见的,虽然即使是最激进的 “AGI加速主义者” 也不太可能打赌实际上存在 10^37 个GPU。
10^37 个 GPU 是天文数字。10^36 个也是一样。如果你是一家初创公司,那么 101 个 GPU 也很多。而如果你是一个普通人,100 个 GPU 同样很多。GPU 就是很昂贵。那怎么办呢?
在我们上面列出的无限计算( unbounded-compute )、如神般的 AGI ( god-like AGI ) 能力清单中,有什么是我们期望在 10^36 个 GPU 受限,但在 10^37 个 GPU 就能被允许的东西吗?
上面章节提到的 a) 和 b)是今天投资于 AI 的整个目的。
a ) 它可能是一个信息先知( information oracle ) — 是谷歌的终极继承者,因为它将封装并推理关于人类知识的总和( encapsulate and reason about the sum total of human knowledge )。而且在提供答案时,它不会产生 “幻觉” 而虚构事实或信息来源。
b )它可以用来 "解决" 科学问题,创造我们难以想象的新技术。
如果这样的目标不可能实现,那将是一场悲剧。具有正确防护和检索能力的大语言模型已经是信息先知( LLMs with the right guardrails and retrieval abilities already are information oracles )。鉴于人类自己能够进行推理和科学研究,我们中的一些人甚至没有任何 GPU 帮助也能做到。目前还不清楚来自物理学的缩放约束是否会限制 AI ( a scaling bound from physics will limit AI )。
最初的人工智能悲观论调( AI doomer concern )关切的核心是智能爆炸的概念 ( an intelligence explosion ) :未来的通用人工智能系统将具有可以执行人类所有任务的通用智能(a general intelligence),包括设计通用人工智能系统( AGIs );因此,这些被设计出来的通用人工智能系统又将设计未来的人工智能系统,能够执行人类所有任务,包括设计更多通用人工智能系统;从此循环往复一环套一环。
这个想法有时被称为递归性自我改进( recursive self-improvement );它实际上只是一种基本理念,即投资 — 这里指的是对智能的投资 — 会以指数形式递增。
我们这里的讨论,其实只是想说明,世上没有无限计算( unbounded computation )。这种循环终将停止。所有有抱负的通用人工智能( AGIs )及创造 AGI 的公司首先受制于计算的现实世界限制,比如筹集大量资金来建造或访问超级计算机,但即使这些 “实际” 的限制被克服,任何派生的人工智能系统最终仍然受制于各种基本的物理限制 ( 更别说还有政府监管这种非常现实的计算限制 )。因此,在实际落地当中,计算的物理限制对人工智能有影响吗?
如果你对人工智能的概念只是一种新技术,甚至可以说是最不可思议的变革性技术。那么,我认为很可能答案是否定的。
如果你对人工智能的理解是创造一个无限强大的上帝( 或者可能是召唤一个恶魔 )— 一种几乎可以被认为是无限魔法( unbounded magic )的技术 — 那么我认为计算的物理限制会影响到 AI 。
通过讨论极限在哪里,并将问题嵌入物理学视角中,我希望区分 “人工智能技术” 和 “人工智能宗教”。当然,如果你担心一个具有无限能力的 AGI 神,那么( 那些自洽的 )科幻将塑造你对人工智能的看法:只要逻辑上允许的任何事情都可能引起合理的担忧。我的观点是,这太过宽泛:对物理约束的深思熟虑,可以截断人工智能风险的长尾,将我们限制在更有限的结果集中。
虽然结果集合有限,但其重要性丝毫不减。因此,我认为我们应该像对待其他革命性技术一样,关注人工智能的成本和收益( the costs and benefits of AI ),而不是将其视为神话。把人工智能从神降格为技术,从宗教降格为科学,仍然使我们有能力加速技术和科学的发展,直到碰到物理定律施加的限制( the limits imposed by the laws of physics )。
换句话说,上述 a)和 e)项中真正令人兴奋的结果是我们建立了一个科学推理工具 ( we build a toolfor scientific reasoning )。
为了实现这一目标,我们将需要超越纯计算规模缩放的新想法( we’ll need new ideas that go beyond pure compute scaling )。对于研究人员、工程师和企业创始人来说,这是一个( 科学的 )乐观理由。
原文链接:
https://www.sequoiacap.com/article/black-holes-perspective/

好内容,更需要鼓励