AI深度研究员
2025-03-12
场景:数学课上,老师正在讲解“隐函数求导”,步骤写到第三行时突然跳过了中间推导,直接给出结果:“所以这里的dy/dx=(-2x-y)/(x+3y²)”。
你盯着白板上的公式一脸懵——前两步的链式法则展开去哪了?
为什么分母突然多了3y²?
周围同学纷纷点头,老师已经翻到下一页讲应用题了。你手心冒汗,想举手提问又怕被说“这么简单还不会”……
1.课堂当下(隐蔽求助)
适用场景:课堂上随时快速跟进
操作技巧:Ø 在笔记软件中快速标注困惑点(如:“疑问:第二步到第三步如何展开?”)Ø 输入精准问题:“隐函数求导例题:从方程x² + xy + y³ = 0推导dy/dx,请展示完整的链式法则展开步骤,特别是分母3y²的来源。”Ø 秒速获取步骤解析:立即对照补全笔记,跟上老师进度。
2. 课间5分钟(深度追问)
适用场景:老师已下课,但10分钟后还有后续课程
操作技巧:Ø 追问细节:“为什么对y³求导会得到3y²·dy/dx而不是3y²?”Ø 让AI用类比解释:“请用‘水管流速’比喻说明隐函数求导中dy/dx的意义。”Ø 生成记忆口诀:“把隐函数求导步骤编成顺口溜,包含‘遇y先写dy/dx’等关键词。”
场景2:文科生快速上手编程
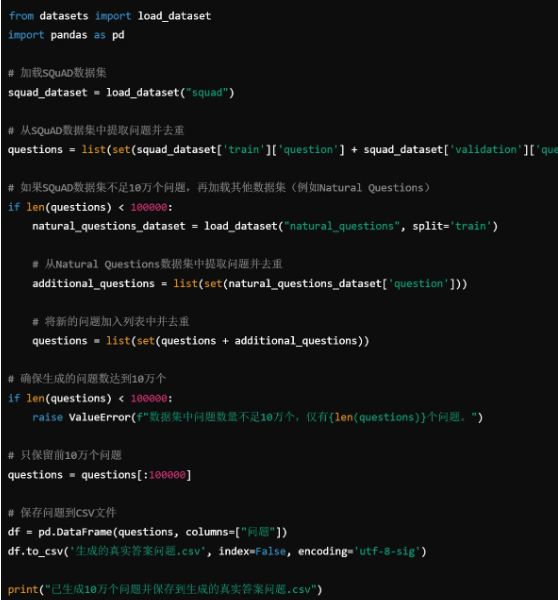
AI幻觉问题抽取:多数据集 问题加载
要生成10万个存在真实答案的问题,并且基于2020年之前的数 据 , 可 以 使 用 现 有 的 公 开 问 答 数 据 集 ( 如 S Q u A D 、Natural Questions等)来生成问题。可以从多个数据集中组合问题,以达到10万个的问题数量。
这 些 数 据 集 包 含 大 量 的 问 答 对 , 例 如 使 用 d a t a s e t s 库(Hugging Face的datasets库)来加载SQuAD数据集(Stanford Question Answering Dataset),这个数据集是一个著名的问答数据集,基于维基百科数据生成,并且数据是2020年之前的。
加载数据集:使用datasets库加载SQuAD数据集,这个数据集包含了大量基于2020年之前数据生成的问答对。
提取问题:从数据集中提取问题,并使用set去重。
检查问题数量:确保提取的问题数量至少为10万个。
保存问题:将问题保存到CSV文件生成的真实答案问题.csv中。