
本文来自微信公众号: Founder Park ,作者:Founder Park,原文标题:《Cursor 套壳、Cloudflare 上架、老黄邀请,中国模型杀进了硅谷的 AI 供应链》
3月19日,Cursor发布了自研新模型Composer 2。官方博客称它来自「our first continued pretraining run」,跑分超过了Claude Opus 4.6。
一天之内,技术社区就发现了问题:Composer 2的底层,基于Kimi的开源模型Kimi K2.5微调。但Cursor的博客里一个字都没提。
一个估值500亿美元的硅谷AI编程工具,核心能力跑在一家中国公司的开源模型上,而且一开始还没说,这事儿,怎么看都有点意思。
但Cursor只是最新的一个信号。同样是本周:
Cloudflare把K2.5上架到全球边缘计算平台Workers AI,内部实测成本降低77%;
老黄邀请杨植麟作为唯一的中国独立大模型公司创始人在GTC 2026演讲;
马斯克一周内两度公开点赞Kimi;
而Kimi自己,正以投前估值180亿美元(约合人民币1200亿),进行新一轮10亿美元融资,Kimi已成为中国最快的十角兽公司之一。
1月29日开源发布,3月20日Cursor事件引爆。不到两个月,Kimi K2.5跑进了硅谷从应用层到基础设施层的核心工具链。
它是怎么做到的?
⬆️关注Founder Park,最及时最干货的创业分享
超22000人的「AI产品市集」社群!不错过每一款有价值的AI应用。
邀请从业者、开发人员和创业者,飞书扫码加群:
进群后,你有机会得到:
最新、最值得关注的AI新品资讯;
不定期赠送热门新品的邀请码、会员码;
最精准的AI产品曝光渠道
01
Cursor的新模型,
底层是Kimi
3月19日,Cursor发布Composer 2。
官方博客写得很漂亮。CursorBench得分61.3,超过Claude Opus 4.6的58.2;SWE-bench Multilingual 73.7,相比上一代Composer 1.5的65.9大幅提升。博客用了一个精心措辞的说法:「我们的第一次继续预训练」——给人的感觉是,Cursor自己从头训练了一个编程模型。
但很快有推特网友注意到了问题,发现Composer 2底层是K2.5。
开发者们开始比对Composer 2的输出特征和已知开源模型的行为模式,结论指向了Kimi K2.5。随后的信息逐步浮出水面:Composer 2约25%的预训练来自K2.5的基座模型,Cursor在此基础上做了微调和续训,推理部署由Fireworks完成。
马斯克同日在X上转发了相关讨论。
事件发酵后,双方先后出面,将合作定性为授权合作。
Cursor联合创始人Aman Sanger回应得很直接:「一开始没在博客里提到Kimi的底座,是我们的疏忽。下一个模型我们会改正。」
这件事为什么重要?
先看一个背景:Cursor此前只用OpenAI、Anthropic和Google的模型。它对模型供应商的筛选标准在行业里是出了名的严。
现在,一家估值500亿美元的硅谷明星产品,选择了一个中国公司的开源模型来构建自己的核心编程能力。而且不是「加入可选列表」——是把K2.5的权重作为预训练基座,在上面搭建自己的模型。
Composer 2的定价也耐人寻味:标准版0.50/M input tokens、2.50/M output tokens,比K2.5的官方API定价(0.60/3.00)还低。Cursor之所以能把价格打到「一折」,正是因为K2.5本身的成本结构足够低。
The Decoder在3月21日的报道中分析了Cursor最初不披露的原因:「不披露很可能出于竞争定位的考虑……承认依赖(外部模型)会动摇其独立AI能力的说法。」
但反过来看,Cursor选择K2.5本身就是最好的技术背书。如果K2.5不够好,一个对模型要求如此苛刻的产品不会冒险用它。不是中国公司在模仿硅谷产品——是硅谷产品基于中国模型来构建核心能力。
Cursor事件引爆当天,马斯克在X上转发并评论。这是他一周内第二次公开提及Kimi。

马斯克的第一次转发,是因为一篇论文。
3月16日,Kimi团队在arXiv发布了Attention Residuals论文,挑战Transformer沿用近十年的残差连接设计。Kimi官方账号的推文在X上迅速引爆——480万阅读,2500次转发,1.3万点赞,登上Twitter全球热搜,传播声量不亚于一次模型发布。
马斯克转发点赞,Andrej Karpathy评论:「我们一直没真正把'Attention is All You Need'这个标题当回事。」OpenAI联合创始人Jerry Tworek只说了两个词:「deep learning 2.0」。
02
不止Cursor:
硅谷的基础设施也在接入Kimi
Cursor是应用层的标志性事件。但Kimi同时也打进了硅谷的基础设施层和算力层。
Cloudflare接入Kimi,成本降低77%
在Cloudflare公布数据之前,硅谷已经有人喊出了更大的数字。
K2.5发布不久,All-In Podcast的Chamath Palihapitiya在节目中说了一段很有冲击力的话:「我觉得大家还没意识到这个Kimi K2.5时刻有多重要……把下一代系统和开源结合起来,AI的成本能砍掉90%。」
他甚至宣布:「我把所有OpenAI的账户都取消了。25000美元,没了。」
这是硅谷顶级投资人在一档累计播放量超过10亿的播客里,公开为一个中国开源模型站台。Chamath的预测是「省90%」——而Cloudflare随后用自己的生产数据给出了验证。
Cloudflare在Workers AI平台上架了Kimi K2.5。Workers AI是全球最大的边缘计算平台之一,开发者通过它调用AI模型,请求在离用户最近的节点上执行。此前平台上的模型清一色来自美国公司——Meta的Llama、Google的Gemma。K2.5是第一个来自中国的大语言模型。
但真正有说服力的不是「上架」这个动作本身,而是Cloudflare自己的使用数据。
Cloudflare在官方博客中披露:他们内部的安全审查agent每天处理超过70亿个token,在一个代码库中就识别出了15个以上的确认问题。此前这个agent使用中等价位的闭源模型,年费约240万美元。切换到Kimi K2.5后,成本降低了77%。
Chamath说「省90%」,Cloudflare实测「省77%」。一个是投资人的判断,一个是工程团队的账本——量级基本对上了。
被Cloudflare选中,不只是「多了一个渠道」,Kimi被编进了全球开发者的默认工具箱。
黄仁勋与Kimi:从CES到GTC
黄仁勋对Kimi的关注不是从GTC才开始的。
1月初的CES上,黄仁勋就用Kimi模型来验证下一代芯片的性能表现。对NVIDIA来说,选择哪个模型来做芯片的「验货工具」,本身就是一个技术判断——它需要足够吃算力、足够考验架构,才能充分测试硬件的极限。
两个月后的GTC 2026,黄仁勋再次选择了Kimi。3月18日,也就是Cursor事件的前一天,他邀请杨植麟在GTC做了一场演讲,主题是:「我们如何扩展Kimi K2.5」。同时,NVIDIA在GTC上用Kimi模型展示了推理能力——从验货到展示,Kimi成了NVIDIA在两场最重要的年度大会上反复使用的模型。
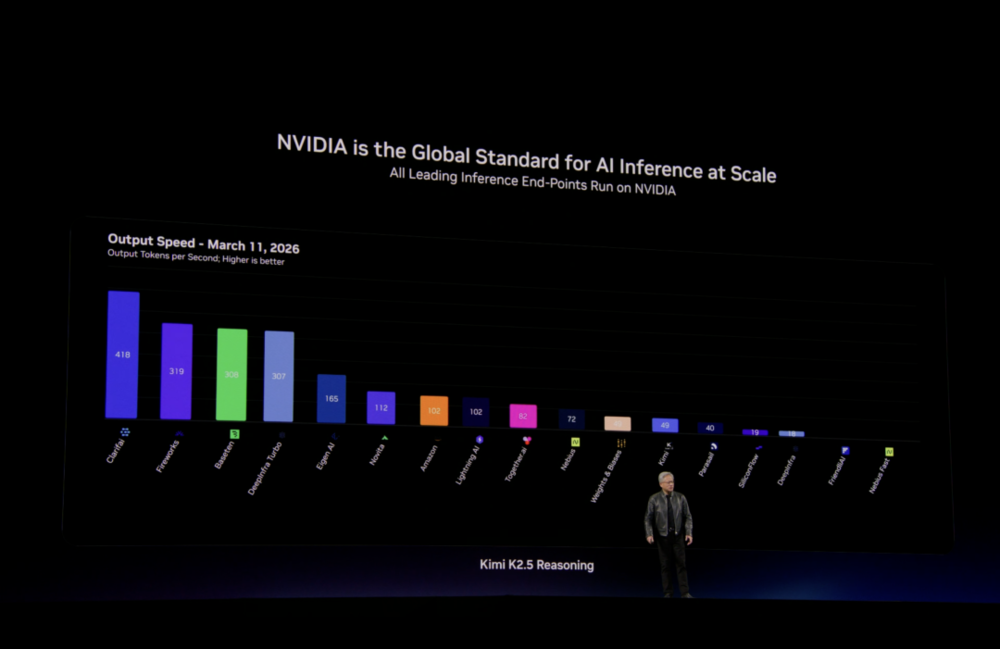
GTC2026上,老黄用KIMI模型展示推理能力。
杨植麟是唯一受邀现场演讲的中国独立大模型公司创始人。此前,中国的独立大模型公司几乎没有先例。
杨植麟在演讲中首次系统披露了K2.5的完整技术路线图。他说了一句很关键的话:「很多通用技术标准正在成为scaling的瓶颈。」
翻译过来就是:不能只靠堆算力和堆数据了,要改底层。
他提到的关键技术创新包括优化器改进、注意力机制重构(包括后来发表的Attention Residuals论文)和残差连接的重新设计——都是模型架构层面的「地基工程」。
把这些信号放在一起看:应用层,Cursor选K2.5做底层;基础设施层,Cloudflare把K2.5部署到全球边缘节点;算力层,NVIDIA从CES到GTC连续两次用Kimi做展示;投资圈,Chamath在All-In播客上公开喊出「K2.5时刻」。
三层信号,指向同一个结论:硅谷AI圈的核心工具链正在接入Kimi。
03
Kimi做对了什么?
硅谷的工具链为什么会选一个中国开源模型?具体来说,有两个原因。
技术路线:从底层架构入手
K2.5的模型架构是MoE架构。总参数1 T,但每次推理只激活其中的32B——384个专家模块中选8个工作,剩下的「休息」。这意味着你得到的是一个万亿参数级别模型的能力,但只付320亿参数的推理成本。
这是Cursor和Cloudflare选择它的直接原因:性能在第一梯队,成本只有同级别闭源模型的几分之一。
编程场景的数据很能说明问题。K2.5在SWE-Bench Verified上达到76.8%,LiveCodeBench v6上达到85.0%——后者超过了DeepSeek-V3.2的83.3%。不是一个「还行」的模型,基本在编程场景的第一梯队。Cursor基于它微调出的Composer 2跑分超过了Claude Opus 4.6,侧面验证了基座模型的质量。
更值得关注的是Kimi团队在底层架构上的持续创新。3月16日,他们发布了一篇关于注意力残差(Attention Residuals)的论文。传统Transformer的残差连接用固定权重把每一层的输出简单累加,层数越深,早期层的贡献就越被稀释。Kimi的做法是用softmax注意力替代固定权重,让模型能根据当前输入动态决定「回看」哪些层的信息。
效果很直接:在GPQA-Diamond(研究生级别科学推理)上提升7.5个百分点,相当于多用25%的算力训练。
杨植麟在GTC演讲中把这条路线概括为一句话:「很多通用技术标准正在成为scaling的瓶颈。」意思是,美国主流路线习惯于堆更多的GPU、喂更多的数据来提升模型能力,但这条路的边际收益在递减。Kimi选择的是另一条路——改底层架构,让同样的算力产出更多的智能。
Cloudflare的77%成本降低就是这条技术路线最直接的商业验证。不是性能打折换便宜,是同等性能下成本只有四分之一。
开源找到了自己的生态位
开源模型,目前可能只在榜单上打败了闭源。
事实上,Anthropic的Claude、OpenAI的GPT、Google的Gemini,在绝对能力的天花板上仍然领先。如果你需要的是当前最强的通用推理能力,闭源模型依然是第一选择。
但K2.5的案例证明了另一件事:开源模型已经找到了自己的应用市场和不可替代的竞争力。
具体来说,是三个闭源模型覆盖不了的生态位。
第一,性价比驱动的大规模部署。Cloudflare的安全审查agent每天跑70亿个token,一年省下约185万美元。这种量级的调用场景,用闭源模型的API定价根本不现实。开源模型可以自部署、可以量化压缩、可以针对特定场景优化推理成本——这些都是闭源API做不到的。
第二,可定制性。Cursor基于K2.5的权重微调出了自己的编程模型。这件事在闭源世界里不可能发生——你没法拿到Claude或GPT的权重,也就没法在它们的基础上做深度定制。开源模型的权重是公开的,企业可以根据自己的场景做微调、做蒸馏、做特定领域的优化。Cursor的Composer 2本身就是开源可定制性的最佳证明。
第三,透明度和信任。开发者能看到权重、能审计模型行为、能本地部署不出内网。对安全敏感的企业和政府场景,这不是「nice to have」,是刚需。
K2.5在HuggingFace上的下载量已经超过356万,GitHub上有127个项目集成了它,ollama也已支持K2.5。
开源不是在跟闭源打同一场仗。它找到了闭源模型覆盖不了的场景——大规模部署、深度定制、可审计——然后在这些场景里建立了自己的优势。而Kimi K2.5,是目前在这条路线上跑得最快的。
04
Kimi正在从模型公司,
变成Agent基础设施公司
Kimi内部也在快速出牌。
早在K2 thinking发布时,Kimi就提出了「模型即Agent」的路线。当时听着像愿景。过去两个月的产品动作证明,这可能是产品路线图。
Agent Swarm是K2.5带来的最激进的产品尝试。一个编排器可以动态调度最多100个子Agent,并行执行1500步任务,速度比单Agent快3到4.5倍。写一份深度研究报告、批量检索上百家公司信息——以前要拆成几十个对话窗口慢慢磨的活,现在一次性扔给集群。想解决的是「一个Agent不够用怎么办」。
Kimi CLI作为终端里的AI编程助手,已经在开发者社区攒下了一批核心用户。GUI版本正在试水,他们想把同样的能力推向非技术人群,让更多人来用。
春节期间上限的KimiClaw,基于自家模型快速上线了一键部署版的Openclaw,一个24/7在线的Agent环境,不用搭服务器,不用碰命令行。配合K2.5模型,使用的感觉意外还不错。
Kimi正在从一个模型公司,变成一个Agent基础设施公司。
数据也在验证这条路线。据Similarweb数据,kimi.com的访问量已达历史新高,最近三个月累计访问量突破1.2亿次。这个数字说明,Kimi不只是在开发者社区有口碑——它正在成为一个有规模的消费级产品。
外部被硅谷工具链选中,证明了模型能力;内部全面转向Agent,是在模型能力之上搭建产品层;用户端的增长数据同步跟上。三条线同时加速。
从1月29日开源发布,到3月20日Cursor事件引爆,不到两个月。
这两个月里发生的所有事情——Cursor用它做底层、Cloudflare用它省77%的钱、黄仁勋从CES到GTC连续两次用它做展示、Chamath在播客里喊出「K2.5时刻」、马斯克两度点赞——指向同一个信号:硅谷的核心生态工具链,开始基于中国开源模型构建。
这不是因为中国模型在所有维度上超越了闭源模型。闭源的Claude、GPT、Gemini在绝对能力的天花板上仍然领先。但在大规模部署、深度定制、成本控制这些实打实的生产环境需求面前,开源模型找到了自己的生态位——闭源模型覆盖不了的生态位。