
本文来自微信公众号: InfoQ ,作者:褚杏娟
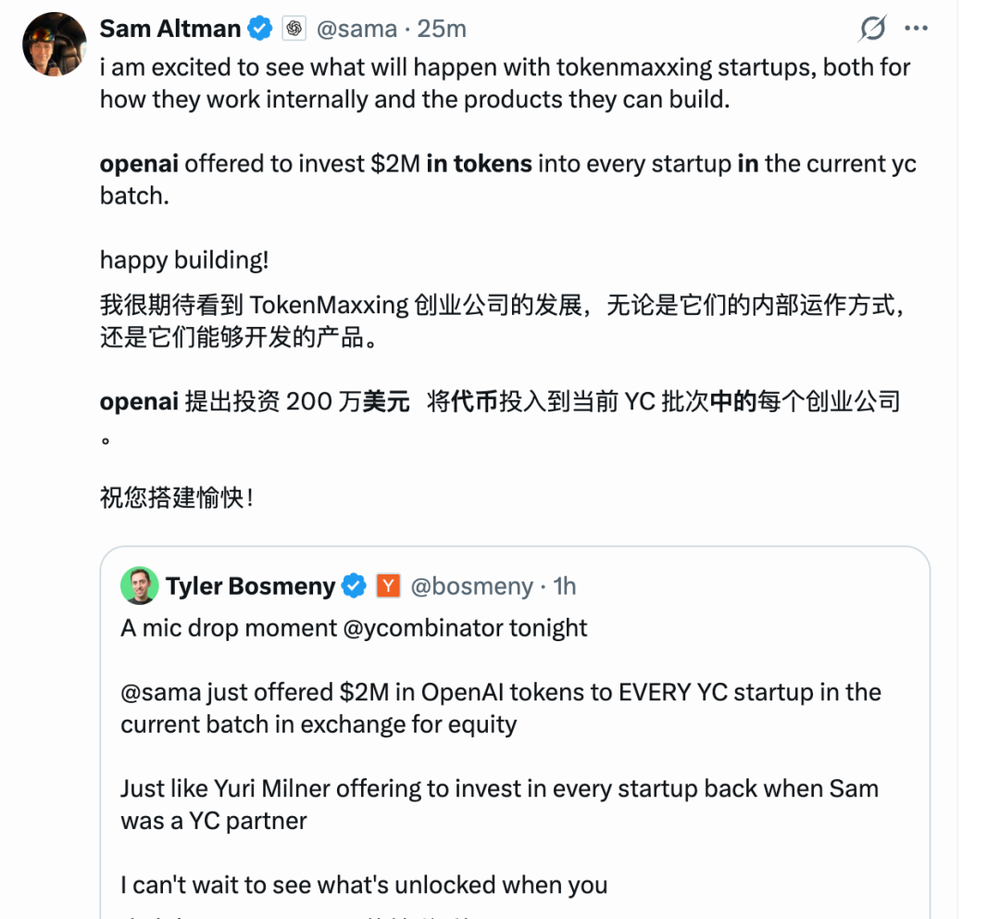
今天,YC合伙人Tyler Bosmeny在x上表示,Sam Altman刚刚向YC当前这一期的每一家创业公司提出,用200万美元的OpenAI tokens换取股权。
Bosmeny表示,“这有点像当年Sam还在YC做合伙人时,Yuri Milner曾提出投资每一家创业公司。我已经迫不及待想看看,当你让那些最有驱动力、最有创造力、最强悍的创始人们把token用到极致时,会解锁出什么东西。”
对此,Altman也在x上回应称,“我很期待看到这些把token用到极致的创业公司会发生什么变化,无论是它们内部的工作方式,还是它们能够打造出的产品。”
200万美元听起来不少了,但是一旦换算成token,那这笔帐就不一样了。
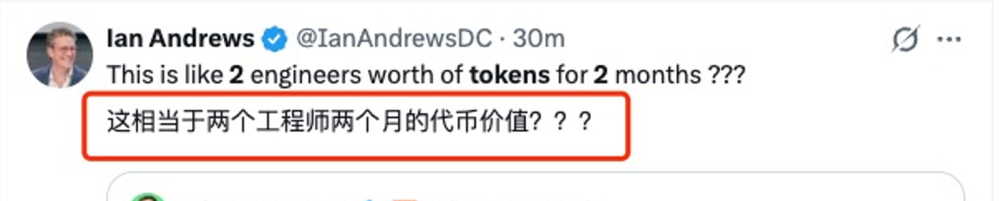
据悉,现在归入OpenAI旗下的OpenClaw创始人Peter Steinberger在一个月内就会花掉130万美元的tokens,而这笔账由他的雇主OpenAI买单。Peter表示,其中大部分开销都用于开发OpenClaw,他每天的花费接近2万美元。算下来,200万美元的token只够“龙虾之父”造一个半月的。
对于一家token maxxing的创业公司来说,假设按照Peter的使用量来算(理论上应该更高),OpenAI免费供你一个半月的token,就能拿走你的部分股权,你干不干吧?
“200万美元的token听起来很多,但一旦你把智能体接上长工具调用轨迹(long tool trajectory),就会发现其实也没那么夸张。”个人builder ByteCrafter说道。
“我们这个跑在4个平台上的分诊智能体,推理消耗比我预想中快得多,主要是工具输出会不断吃掉上下文。后来,我们在每次输出重新进入上下文之前,先加了一个便宜的Haiku摘要器,确实帮我们省回了相当一大块成本。”他随后追问:有人真正按任务粒度做过token成本埋点吗?还是说,对大多数人来说,这事现在仍然主要靠感觉判断?
当然,不是每个人都有Peter的消耗量。有开发者称,自己整个AI开销就是每周在Codex上花200美元,而且两三天就用完了。“200万美元的token,差不多相当于我这笔账单192年的额度。真想看看,当团队不用再精打细算token时,到底能做出什么东西。”但这个情况可能并不够“tokenmaxxing”。
无论如何,这事儿对OpenAI来说一定是划算的。
有网友表示,这基本上就是终极版的供应商锁定策略。发放200万美元免费额度,等于确保整整一代YC创业公司都把核心基础设施建在一个封闭生态上。等补贴耗尽时,它们已经负担不起迁移成本,也离不开这个体系了。
也有网友指出,这是一个聪明、低风险的决策:直接从Anthropic手里抢竞争筹码。YC公司一旦成功,就会使用越来越多的OpenAI token。这样一来,OpenAI不仅能把这200万美元赚回来,甚至还能赚更多。而且,这会形成一个黏性极强的创业公司群体,因为他们会一直记得:自己能走到今天,是因为你当初帮了他们。除此之外,OpenAI还拿到了股权。
“Token真的变成金融证券了?”有网友忍不住问道。
但这种事儿并不只发生在了硅谷。
与传统校友捐赠图书馆、奖学金或教学楼不同,三位00后选择向母校捐赠价值20亿的token。
据媒体报道,5月13日下午,郑州西亚斯学院外语学部报告厅,数百个“Token蛋”盲盒被学生一抢而空。这些盲盒里装的不是普通礼品,而是总计20亿的AI Token。这批Token可用于跨境生意AI工作台Accio Work,预计能覆盖约500名在校学生一个月的使用费用。
这批Token的捐赠者,是三位从郑州西亚斯学院走出的“00后”创业者:何佳坤、李佳乐、王腾。他们都在校期间或毕业后进入跨境电商领域,其中有人已经把外贸年销售额做到千万元级别。
“3年前创业时我没有AI,如果有,从0到3000万的速度会快一倍。”何佳坤在创业分享会上说。除了捐赠Token,三人还现场分享了适合“一人公司”、外贸新手和学生创业者使用的AI Skill应用方法,试图把自身经验沉淀成可复制的工具和流程。
20亿token也是一个听起来很唬人的数字,但有网友表示,按照ds4 1亿5块钱计算,这相当于给母校捐款100块钱。“搞半天20亿token都不如手上拿着那张捐赠证书值钱。”其评价道。
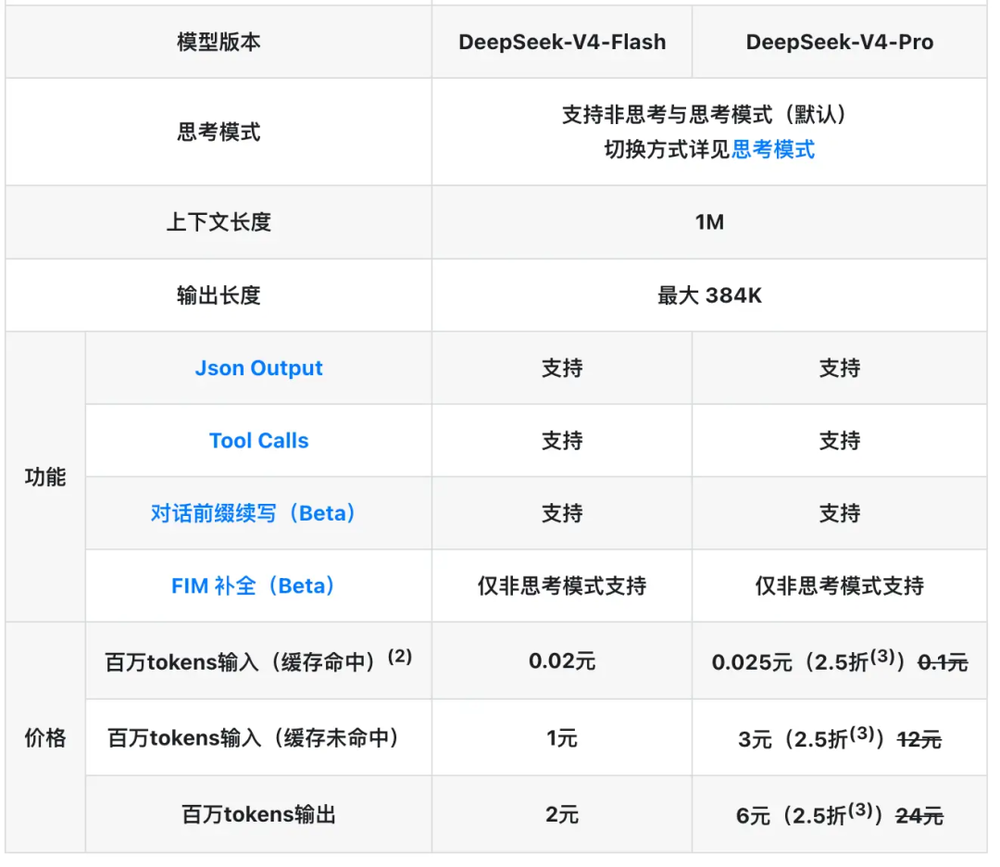
DeepSeek两款模型当前价格表,deepseek-v4-pro现2.5折,优惠期至5月31日
知乎上,网友“杰拉德笔下的男人”表示,“20亿Token,放在大模型世界里,差不多是十几亿个字。这相当于把整套《三国演义》让AI读上上千遍。对一个多数人来说,一辈子也写不出这么多字,读也读不完。但在工作中,比如一个程序员,如果连着大模型的API天天洗数据、写代码、测代码,一天用个上亿Token,真不难事。这也是为什么很多打工人一看到20亿,第一反应是这点钱够干嘛,跑两天就没了。”
觉得自己AI落后了,那就“tokenmaxxing”?
欢迎来到“tokenmaxxing”的时代。
如果你担心自己在AI上已经落后了,开发者Sigrid Jin给出了一条建议:大量使用AI,直到你的月度账单差不多能和房租相提并论。Jin认为,“tokenmaxxing”是理解AI价值的最佳方式,他自己一年内就使用了500亿token。
Jin在3月底走红。当时Anthropic意外泄露了Claude Code的源代码,他随后重建了Claude Code的代码库。为了避免遭到这家AI实验室的版权下架,他用Python重新写了一遍。这场tokenmaxxing确实带来了回报:Jin创建了史上增长最快的GitHub仓库,名叫Claw Code。此后,Jin收到了几家AI实验室的工作邀请,但他决定把精力放在个人项目上。他计划在下个月创办一家创业公司。
Jin认为,大多数人并没有真正体验到AI能提供多少价值,因为他们用的只是免费版,或者每月20美元的订阅套餐。他表示,那些只使用基础版AI的人,正在错过200美元套餐所能提供的“更高智能”,这些更高阶套餐能带来更清晰的投资回报。
“如果你想知道AI的未来是什么样,就试试tokenmaxxing。”他还补充说,自己会建议朋友,“在AI上花的钱,尽量接近你每个月付的房租”,这样才能获得“投资回报”。
这种回报可能表现为“同时运营多项业务”,也可能是把日常生活中的常见任务交给AI agent来处理。Jin表示,AI的成本效益没有一套通用衡量方式。每家公司、每个个人使用这项技术的方式都不同,因此需要建立自己的基准,用来衡量回报。
如此同时,越来越多公司花在AI账单上的钱,已经超过了支付给人类员工的薪水。但问题是,AI带来的收入必须超过token成本,才能证明这些支出是合理的。对于企业用户来说,尤其如此。
推高token消耗的压力,短期内不会消退。当被问到要使用更多token时是否感到有压力,Jin的回答是:“是的,当然。”
这种tokenmaxxing的执念也出现在企业中,员工不得不像有些某宝刷量的商家一样,为自己的token刷量。
此前The Information报道称,一些Meta工程师正在竞相消耗token,只为登上一个由员工自制的“Claudeonomics”仪表盘排行榜。这个仪表盘会追踪使用量,并让员工争夺类似“Token Legend”这样的称号。
“按token消耗量给工程师排名,就像我按谁花钱最多来给市场团队排名一样。不要把高烧钱速度误认为高成功率。”Linear COO Cristina Cordova在X上写道。
据悉,Meta、OpenAI、Anthropic等公司内部都设有token排行榜。
这也逐渐变成一种炫耀方式。创始人和前沿工程师会在X上晒出自己的token消耗量,以此表明自己对AI的投入程度。一名xAI员工写道,科技行业正在把每一个好想法都变成“表演”。
有人在X上写道:“我个人每周会在token上花掉数千美元……感觉很疯狂,但我停不下tokenmaxxing。”
YC CEO Garry Tan似乎也认同这种做法。他转发了一条批评公司在token上“抠门”的帖子,并写道:“我们tokenmaxxing的时间比大多数人都久。”
tokenmaxxing是一个好激励吗?科技圈内部对此分歧很大。
Khosla Ventures合伙人Jon Chu在X上称,用token消耗量作为衡量方式是“绝对愚蠢的政策”。他写道:“不少我在Meta的朋友告诉我,因为这项政策,有人已经在写机器人,让它们不停循环运行,用最快速度烧token。”
Cursor员工Edwin Wee Arbus则谨慎些。他称这个指标是一个“有用、快速的代理指标,但略有缺陷”。他将其类比为身体质量指数BMI:BMI可以提供一些健康参考,但无法反映肌肉量或骨量。
也有人持完全相反的看法。
“tokenmaxxing是我听过最离谱的启发式指标。事实上,我会认为更好的工程师应该能用更少token解决问题。”一名用户在X上写道。
《The Pragmatic Engineer》作者Gergely Orosz认为,这种做法很浪费。他写道:“只要某个指标和更多奖金或晋升挂钩,开发者就会想办法刷它。这个也一样。”
有人用一句话概括了tokenmaxxing的问题:“没有tokenverifying的tokenmaxxing,只是tokenslopping。”也就是说,如果只是烧token,却不验证结果,那就只是制造一堆token垃圾。
在硅谷,巨额token预算正在变成开发者之间的一种“荣誉勋章”。但如果用它来衡量生产力,其实非常奇怪。因为token消耗衡量的是投入,而你真正关心的应该是产出。如果你的目标是鼓励员工更多使用AI,或者你本身就在卖token,那这个指标或许说得通;但如果你的目标是提升效率,那只看token消耗就没什么意义。
工程师们不得不回头修改AI的代码
不过,最有资格回答这个问题的或许就是token消耗大户:软件工程师。
现在,一批做“开发者生产力洞察”的公司发现,使用Claude Code、Cursor、Codex这类工具后,开发者确实提交并保留了更多代码。但与此同时,它们也发现,工程师之后不得不更频繁地回头修改这些已经被接受的代码。
这削弱了“AI显著提升生产力”的说法。
Waydev CEO兼创始人Alex Circei表示,工程管理者看到的AI代码接受率通常在80%到90%之间,但他们往往忽略了后续几周发生的返工和修改。工程师不得不反复修订这些代码,导致现实中的有效接受率被拉低到了10%到30%。
整个行业的数据正在指向一个结论:写出来的代码更多了,但其中相当大一部分并没有真正沉淀下来。
GitClear公司在今年1月发布报告称,AI工具确实提高了生产力,但“经常使用AI的开发者,平均代码流失率是不使用AI开发者的9.4倍”。这个流失幅度,已经超过了这些工具带来的生产力提升幅度的两倍。
工程分析平台Faros AI在3月份的报告中,使用了两年的客户数据。结果显示,在AI高采用度环境下,代码流失率(也就是删除代码行数相对于新增代码行数的比例)增加了861%。
面向AI融合工程的智能平台Jellyfish,收集了2026年第一季度7548名工程师的数据。平台发现,token预算最高的工程师,确实产出了最多的PR,但生产力提升并没有等比例放大。他们用10倍token成本,只换来了2倍吞吐量。也就是说,这些工具带来了更多“量”,但不一定带来更多“价值”。
这些统计数据,和很多开发者的真实感受是吻合的。开发者一边享受新工具带来的自由,一边也发现代码审查和技术债正在堆积。一个常见现象是,高级工程师和初级工程师之间差异明显:后者更容易接受AI生成的代码,因此后续也要承担更多重写和返工。
大公司们仍在摸索如何高效使用AI工具。比如去年,Atlassian以10亿美元收购了另一家工程智能创业公司DX,目的就是帮助客户理解编程智能体的投资回报率(ROI)。
不过,即便开发者还在努力搞清楚自己的AI工具到底在做什么,他们也并不认为行业会很快回到过去。
“这是软件开发的新时代,你必须适应。作为一家公司,你也被迫适应。它不像是一阵风,过了就会消失。”Circei说道。
Token狂欢太贵了,经济帐岌岌可危
但是,这场海内外的token狂欢,至今还没有把经济帐算通。
“就目前而言,AI对参与其中的绝大多数人来说,在经济上都不可行。”EZPR CEO Ed Zitron在发布的最新文章里直接指出。
他认为,真正赚钱的不是AI应用公司,也不是大模型实验室,而是建筑公司、英伟达以及围绕数据中心建设受益的硬件供应链。整个行业正在用一种近乎非理性的乐观,押注一个尚未被证明能赚钱的未来。
过去三年,微软、谷歌、Amazon、Meta等超大规模云厂商已经在AI基础设施上投入超过8000亿美元,并计划在2026年继续投入约7000亿美元,2027年再投入1万亿美元。换句话说,仅仅为了打平,它们就需要至少数万亿美元级别的AI收入。
但是,这些公司至今都不愿意清晰披露自己的真实AI收入。
微软曾称AI年化收入达到370亿美元,Amazon也说达到150亿美元,但Ed Zitron认为,这类“年化收入”只是某个月份的快照,不等于真实收入,更不能说明这门生意已经成立。真正值得注意的是,微软在OpenAI合作上累计投入约1000亿美元,其中包括原始投资、基础设施建设和托管计算成本。自2023财年以来,微软总资本开支约2938亿美元,其中接近三成可能都与OpenAI基础设施有关。
这就引出了一个更直观的问题:微软花了近3000亿美元资本开支,某种意义上是在为OpenAI建基础设施,但OpenAI本身仍在巨额亏损。即便Microsoft 365 Copilot有2000万用户,假设每人每月都全价支付30美元,最高也不过72亿美元年收入,而实际上微软已经多年在给Copilot打折销售。
Ed Zitron估算,微软2025财年AI收入大约为179亿美元,不到其当年资本开支的五分之一,而且这还没有计入数据中心电力、维护、运营、税费、保险等实际运营成本。
在他看来,要让这些AI投资成立,必须同时满足四个条件:AI收入爆炸式增长;资本开支停止继续扩张;GPU在计入硬件和债务后仍然正毛利;AI收入在资本开支停止前后都能保持稳定。
但现实恰好相反。AI收入没有证明能爆炸,资本开支仍在继续,GPU运行是否真正盈利没有清晰证据,而AI收入高度依赖OpenAI和Anthropic这两家持续亏损的公司。
是的,微软、谷歌、Amazon的大量未来收入承诺,也主要来自OpenAI和Anthropic。比如微软的剩余履约义务增长,主要由OpenAI和Anthropic的云计算承诺推动;谷歌的增长也被Anthropic的TPU和计算承诺拉动;Amazon也高度依赖Anthropic的大额计算合同。
Ed Zitron的结论是:除了OpenAI和Anthropic,这些云厂商并没有看到足够大的AI收入增长。也就是说,所谓AI云收入繁荣,很大程度上来自几家公司互相输血,而不是一个真实、广泛、稳定的市场需求。
如果AI真有不可阻挡的企业需求,为什么没有出现更多OpenAI或Anthropic量级的客户?为什么云厂商的RPO增长主要还是靠这两家公司撑起来?
但实际上,AI实验室自身的财务状况更危险。
AI支持者常见说法是,芯片会变便宜、模型公司会开始卖服务、推理是盈利的。但Ed Zitron认为,没有可靠证据证明OpenAI或Anthropic在推理上盈利,反而有大量迹象说明它们亏得越来越厉害。
以Anthropic为例,根据相关文件,它曾在获得超过50亿美元收入的同时,在推理和训练上花掉100亿美元。Ed Zitron据此判断,Anthropic可能需要花3美元计算成本才能换来1美元收入,而且这还没算员工、电力和其他运营费用。
更夸张的是,Anthropic还背负了对谷歌、Amazon、微软的大额云计算承诺,未来几年可能需要支付数千亿美元级别的计算费用。OpenAI的情况也类似,据The Information报道,OpenAI到2030年底可能计划烧掉8520亿美元。
Ed Zitron认为,无论OpenAI还是Anthropic,都没有证明自己能停止大量烧钱。所谓“未来现金流转正”的说法,建立在极其乐观甚至荒唐的收入预测上。一旦需求高于预期,它们必须临时购买更昂贵的算力;如果提前购买太多算力,一旦收入没有跟上,又会陷入破产风险。
这就是所谓的“接刀子问题”:算力买少了不够用,买多了又可能被固定成本拖死。
AI迎合了“商业白痴”
AI太贵,不只是云厂商和模型公司的问题,也开始传导到企业客户。
Ed Zitron指出,Anthropic近期把企业客户转向token计费,这将真正测试AI的价值。因为过去很多企业还处在“随便用、先探索”的阶段,工程师被鼓励尽可能多地使用AI,但公司并不清楚每季度到底会花多少钱,也不知道ROI如何计算。
一些大公司已经在几个月内烧完年度API token预算。ServiceNow的CIO曾表示,公司正在和CFO一起想办法控制成本,以确保员工今年剩下时间还能继续使用Claude Enterprise。Salesforce CEO Marc Benioff也表示,2026年将花3亿美元购买Anthropic token。
一定程度上,这说明当前AI收入增长很大程度上来自企业的token狂欢,而不一定是可持续需求。很多企业并不知道AI的真实价值,也不知道预算该如何制定,只是在FOMO情绪下疯狂试用。
Stripe的例子显示,其5000多名技术员工每天平均烧掉约9.4万美元token,每月约280万美元,主要用于Anthropic编程模型。这个数字对Stripe不一定致命,但如果放在人力成本中看,AI支出已经相当可观。Goldman Sachs的报告甚至称,AI成本正在接近总人力成本的10%,按当前趋势未来几个季度可能接近人力成本本身。
另一个案例是Zillow。Zillow 2026年第一季度在AI服务上花费超过100万美元,4月又在Cursor、Anthropic、AWS Bedrock上花掉74.9万美元token。按当前速度,它2026年AI支出可能达到700万到1000万美元,接近其2025年净利润的相当大比例。
Zillow的问题不只是花钱,而是组织正在被AI重塑。Zillow内部提出所谓“AI-Native Engineering”,目标包括让软件工程师“不再打开代码编辑器”,从“AI辅助”走向“AI原生”,从“独奏者”变成“指挥家”,再变成“作曲家”,由人类定义规则,agent执行整个软件开发生命周期。
但现实中,据Ed Zitron获得的信息,Zillow工程资源基本没变,需要人工审查的产出却增加近50%;代码部署和PR增加39%;代码审查负载每月增加29000小时,约等于每位工程师额外多出19小时,只是在检查大模型生成的代码。
Blind上的Zillow员工抱怨,代码正在慢慢变成“AI slop”,大量代码在缺乏护栏和充分审查的情况下被批准。有人甚至说,“垃圾就是工作保障”,因为只要AI输出足够混乱,管理层就没法轻易用AI替代工程师。
当公司把AI使用量当作目标,而不是把业务结果和代码质量当作目标,token烧钱会迅速变成“补贴瞎忙”。
而且,现在的公司很难回答下面的基础问题:完成一个具体任务到底需要多少token?不同模型是否一致?不同员工是否一致?同一提示词重复执行,消耗是否稳定?如果没有按任务粒度做多次测量,所谓年度token预算就像蒙眼扔飞镖。
Ed Zitron更为犀利地指出,“生成式AI之所以能如此流行,是因为它完美迎合了一类脱离真实工作、却掌握决策权的高管和经理。”
普通工程师会告诉老板:“这个时间做不到”“资源不够”“需求不合理”。但AI永远不会说不,它会说“当然可以”,然后生成看似像工作的东西:PRD、原型、方案、邮件、幻灯片、代码。哪怕结果很差,它也会道歉,并承诺下次做得更好。
这让高管产生了幻觉:既然AI能快速吐出一个原型,那工程师为什么不能更快?既然AI从不拒绝,那拒绝的工程师是不是懒?于是,AI成为管理层压迫执行层的新工具。
Ed Zitron认为,很多企业不是因为AI真的有效才每年烧掉数百万、数亿美元,而是因为它们由并不理解真实工作的人管理。对这类人来说,AI最大的吸引力不是可靠产出,而是它永远服从、永远积极、永远制造“工作感”。
这也是Ed Zitron所谓“商业白痴的复仇”:一个由不做实际工作的人主导的经济,终于遇到了一种最适合骗他们的钱、迎合他们幻觉的技术。
参考链接:
https://x.com/TFTC21/status/2056415353375465505
https://www.businessinsider.com/openclaw-peter-steinberger-ai-token-bill-2026-5?utm_source=chatgpt.com
https://www.businessinsider.com/tokenmaxxing-ai-token-leaderboards-debate-2026-4
https://www.axios.com/2026/05/13/tokenmaxxer-ai-claude-code-codex
https://www.wheresyoured.at/ai-is-too-expensive/
https://techcrunch.com/2026/04/17/tokenmaxxing-is-making-developers-less-productive-than-they-think/?utm_source=chatgpt.com
https://mp.weixin.qq.com/s/PQbE8I7tb4y2swH2BVeuQQ