
本文来自微信公众号: 返朴 ,作者:一根弦,原文标题:《费曼50年前一纸解决“点菜难题”,最近2500人实测结果相差无几!》
四十多年前的一个谜题
时间回到1970年代末的加州格伦代尔,费曼和他的朋友拉尔夫·莱顿(Ralph Leighton,注[1])一起进入了一家叫Indra的泰国菜餐馆。他俩是这家餐厅的常客。

图1.拉尔夫·莱顿(左)和理查德·费曼(右),两人在表演无实物打鼓。|图源:图瓦之友协会。
在点餐时,莱顿犯了“选择困难症”:是继续点自己最喜欢的姜汁鸡(Ginger Chicken),还是解锁菜单上其他的菜品呢?这家餐厅的姜汁鸡发挥向来稳定,吃它绝对不会踩雷。可万一菜单上还有更美味可口的菜品呢?每次都吃姜汁鸡那岂不是很亏?[1]
大部分人直觉上会选择“前半程探索(exploring),后半程利用(exploiting)”,也就是说,刚开始先去尝试不同的菜品,根据前面探索的结果,选择一个自己觉得最好的菜品。
显然,费曼不满足于这样感性的直觉,他希望用严谨的数学来回答这个问题:当探索到什么时候,就可以不再继续冒险能做到最优解?
费曼拿起了纸,演算了起来。他提出了一个简化的模型:假定餐厅里的每一道菜都有一个对应的分数,而且分数满足均匀分布。最终,费曼写出了一个分数阈值(threshold)
,n为剩余点餐次数(并没有总次数的限制,只考虑还剩多少次;具体推导可见参考文献[2]的附录);如果之前所有尝过的菜品分数都没超过阈值,则继续尝试新菜;若有菜品分数超过这个阈值,则不再尝试,直接选择已经尝试的菜品中分数最高的那个。

图2.理查德·费曼“餐厅问题”的手写笔记,最后一张框住的部分即答案。|图源:参考文献[2]
这几页涂鸦似的草稿被莱顿保存了下来,在2000年时莱顿还整理出来并给出自己的理解,但并未引起关注。直至近些年,几位对此感兴趣的科学家破译了这几页尘封的手稿,在潦草的笔迹中发现费曼提出并解决的餐厅问题正是决策理论中的最优停止问题(OptimalStopping problem)[2]。
最优停止问题
最优停止问题是决策理论中的一类经典问题,在这类问题中最被人津津乐道的是秘书问题(SecretaryProblem)或者相亲问题(Marriage Problem)(《返朴》之前的文章里就曾介绍过,见《相亲结婚,数学教你找到最佳伴侣》)。
一个更通俗的表述是“寻找最大玉米问题”:假设这片地里一共有n个玉米,且每个玉米的大小各不相同,决策者只能向前走,不能回头,全场只能摘一次。那么,如何才能挑选到最大的那颗玉米?最优答案和自然底数e有关:先观察前37%(1/e)的玉米不摘,之后一旦遇到比前面都大的玉米就立刻摘下。这个策略能保证决策者摘到最大玉米的概率是最高的。
相传这个问题最初由运筹学先驱梅里尔·弗洛德(Merrill M.Flood;他合作提出囚徒困境模型)口头提出,并在1950年代数学界流行。1960年,数学科普大家马丁·加德纳(Martin Gardner)在其《科学美国人》专栏上公开了这个问题,命名为Googol游戏。在60年代,该问题及延伸变体已作为严肃数学问题讨论(详细的历史探源可见文献[3])。
因此,费曼很可能早就知道这个数学游戏,也很可能知道数学家早已给出了答案,所以没将他的餐厅问题发表。他的初衷或许只是想帮助好朋友解决一个生活上的小困扰罢了,这也很符合他的人设,“看我露一手”(就不必在数学家面前显摆了吧)。
在费曼提出的原始问题中,研究对象是同一个餐馆里面的不同菜品;为了更方便设计行为学实验,研究人员把研究对象改成了同一座城市的不同餐馆,每晚去一个(显然这不会影响问题的本质),并把这个问题命名成“费曼餐厅问题”。费曼餐厅问题虽然和秘书问题同属最优停止问题,但存在三点本质的区别:
餐馆所服从的分布是已知的;
用餐者可以返回之前去过的餐馆;
其目标是在多个夜晚中最大化总得分,而不是找出单个最佳选项的概率。
为了更加形象地说明两者的区别,拿相亲问题打个比方:相亲者仅有一次选择机会,而且不能回头(“好马不吃回头草”),一旦选择后就不能反悔(不能再选其他候选人了),相亲者所需要做的是保证自己的选择是最优解。在费曼餐厅问题中,相亲者有多次选择机会,而且还可以回头,他的目标是在整个相亲过程中选择到最佳的。
换句话说,相亲者是个务实派——目的性很强,择一人而终老;费曼餐厅问题中的相亲者则是个妥妥的体验派,充分享受整个过程。
在费曼原始的问题中,他把餐厅菜品分数的分布设定成了均匀分布。研究人员把这种分布推广到了另外三种分布(指数分布、幂分布和三角分布)上,并且给出了四种分布下阈值的解析解。当然,科学家在均匀分布下计算得出的阈值和费曼在40多年前计算出来的结果完全相同。
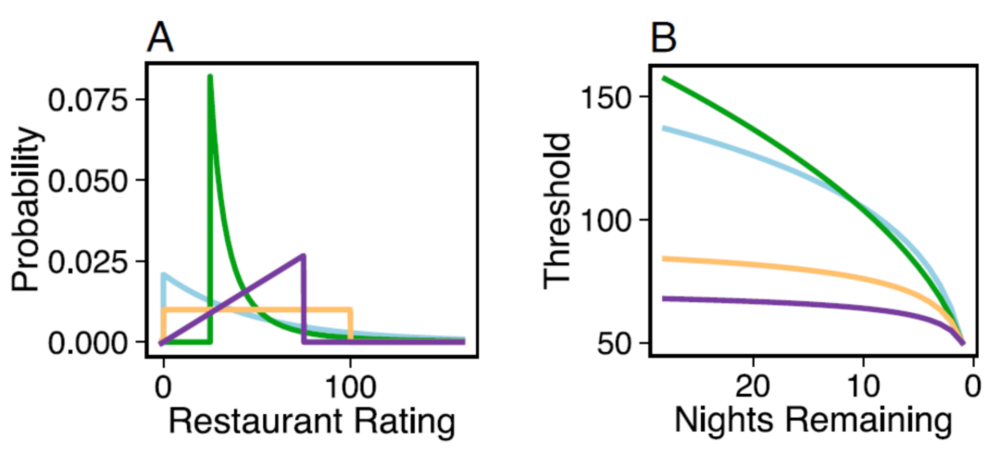
图3.(左)不同餐厅评分分布函数图,(右)不同分布下理论计算出来的阈值随着剩余尝试次数减少的阈值曲线。橙色代表均匀分布,蓝色代表指数分布,绿色表达幂分布,紫色代表三角分布。|图源:参考文献[2]
从图3不难看出,无论哪种分布,阈值并非定值,而是会随着决策次数(横坐标的“Night Remaining”可理解成剩余的尝试次数)的减少而降低。这也符合常理——当可选次数不断减少时,人们会适当下调自己预期,以便做出一个更稳定的选择。还是拿相亲作为例子,当年龄逐渐增加,理性告诉我们需要下调自己的择偶标准,否则可能会孤独终老。
尽管按照科学家们给出的阈值来做决策可以达到最优解,可问题在于,一般人在做决策时不太可能用概率论精准地计算一通,那么他们的行为会遵循什么样的规律?会和从理论上推导出来的规律接近还是相差甚远?
行为学实验
为了得到一般人的决策策略,研究者通过Prolific在线平台招募了2520位志愿者参与实验,年龄从18岁到94岁不等,平均40.4岁,其中53.2%是男性,46.6%是女性,还有剩下0.2%不愿意透露性别。
在实验开始时,被试者被告知了一个虚拟场景:他们将要在一座陌生城市生活一段时间,每晚都需要选择一家餐厅用餐。每家餐厅都有一个固定的质量评分,但在光顾前无法得知具体分数。只有尝试过某家餐厅后,才会知晓其评分并记录下来,之后可以随时再次选择该餐厅。被试的目标是在有限的停留时间内获得尽可能高的总评分。
不同被试接触到的餐厅评分来自不同的概率分布(均匀分布、指数分布、幂分布或三角分布),但这些分布经过处理后具有相同的平均值(50分)。实验阶段,不同测试组的被试者需要在7晚、14晚或28晚的时间(相当于总的访问次数有7次、14次和28次)内连续做出餐厅选择。总结来说,2520个被试者按照餐厅评分概率分布(4种情况)和总尝试次数(3种情况)分成了12组。
在正式实验前,研究者先向他们展示了84个随机抽取的餐厅评分样本。通过观察这些样本,被试者可以对餐厅评分的分布特征形成初步认识。
在正式实验阶段,每到一个晚上,他们都面临两种选择:要么尝试一家从未去过的新餐厅(探索),从而发现一个新的评分;要么返回目前已经发现的最佳餐厅(利用),获得已知的最高收益。如果不按照这个规则做,比如在某个夜晚去了一家之前访问过的餐厅,但这家餐厅不是已知最高评分的,那么被试者将会被警告或者被踢出局。
整个过程中,被试者不断在继续寻找更好餐厅的可能收益与稳定选择已知优质餐厅之间进行权衡。研究者记录了被试者在决策节点上的选择行为,并分析他们何时停止探索、转而持续利用已发现的最佳餐厅。
研究人员使用Logistic模型拟合了被试者的阈值曲线,发现:在模拟真实场景中,人们的阈值是线性下降的,不同的评分分布和不同的尝试次数影响的是线性函数的斜率和截距(参见图4)。
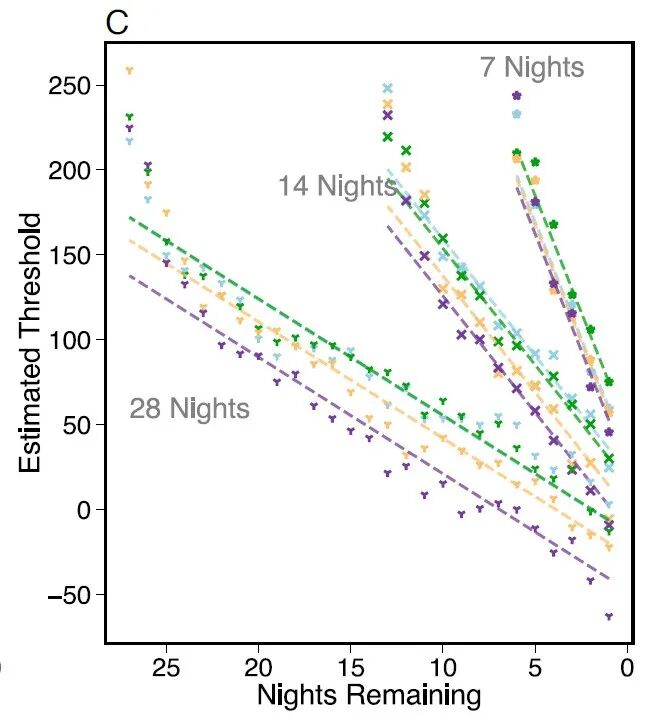
图4.根据被试者行为拟合出的阈值曲线,可以看到统计意义上人们采用了线性的阈值策略。|图源:参考文献[2]
图4里还展示了一个很有趣的现象:在任务开始阶段,被试者的阈值被拉得非常高,这就是显著的“早期探索偏向”(early exploration bias)。具体而言,被试者在最初几轮决策中的探索倾向显著高于总体的线性阈值,即使已经发现了质量较高的餐厅,他们仍倾向于继续尝试新的选项,而不是立即转向保守。
这种“早期探索偏向”可以通过在线性阈值模型中加入一个随时间指数衰减项后得到很好的拟合。这表明,在决策初期人们会额外赋予探索行为更高的价值,希望获取更多信息,这种探索动机会随着时间的推移而快速减弱。这也是常说的好奇心驱动。
线性阈值策略看起来如此的简单,使用这种策略和理论推导出的最优策略相差多少呢?
出乎意外的是,被试者们所使用的看似非常简单的线性阈值规则,获得了与最优策略几乎相同的收益——最优线性阈值策略的收益通常超过理论最优收益的95%以上。也就是说,如果精密的理论最优收益是100分的话,人们在试验中不经过精细推导使用的线性阈值策略也能拿到95分以上的好成绩。人们并不需要执行复杂的最优计算,只需遵循一种简单、容易实施的经验规则,就能够获得接近理论最优的结果。
当然,研究人员也在文章中承认,实验中预设条件是比较理想化的。比如,餐厅评分总是一成不变的;被试者通过一次访问就可以精准地知道餐厅的评分(现实生活中很难做到这一点);在选择餐厅的时候没有考虑交通成本、时间成本、金钱成本,等等(日常生活中人们选择餐厅,餐厅评分只是参考项之一,餐厅的距离、人均消费等因素往往对选择起到关键作用)。此外,为了避免多次实验对数据的影响,研究人员只允许被试者进行一次决策序列。换句话说,这项研究没有把被试者的学习曲线考虑在内。尽管如此,上述这些限制都不影响这项研究本身深刻揭露了人们依靠直觉而非进行数学推导而做出策略的准确性。
结语
近50年前,费曼提出了餐厅选择问题并使用简单的模型进行了推算。多年过去,研究者使用概率论证实了费曼的结果,而真实情况下人们采用的是线性阈值策略,两者差异并不大。这种简单启发式虽然偏离理论最优,却能够以极低的认知成本获得几乎接近的收益。
这项研究可以给我们一些慰藉:或者我们不像诺贝尔物理学奖获得者一样聪明,但凭借直觉选出来的餐厅也不会太差。
注释
[1]拉尔夫·莱顿(Ralph Leighton),1949年出生,美国传记作家,也是物理学家理查德·费曼的朋友,他与费曼合著了《别逗了,费曼先生!》。莱顿还是一名业余鼓手,“图瓦之友”团体的创始人。1991年,他出版了《理查德·费曼的最后旅程》(Tuva or Bust!Richard Feynman's Last Journey)。他的父亲罗伯特·莱顿(Robert Benjamin Leighton,1919-1997)是加州理工的物理学教授,费曼的同事,也是著名《费曼物理学讲义》的作者之一。
参考文献
[1]Davide Castelvecchi,Feynman solved the‘restaurant dilemma’50 years ago—now astudy confirms his mathematics,https://www.nature.com/articles/d41586-026-00821-4
[2]Brian Christian,Evan M.Russekand Thomas L.Griffiths,Resolving Feynman’s restaurant problem reveals optimal solutions and human strategiesProc.Natl Acad.Sci.USA123,e2509612123(2026).https://www.pnas.org/doi/epdf/10.1073/pnas.2509612123
[3]Thomas S.Ferguson.Who Solved the SecretaryProblem?.Statist.Sci.4(3)282-289,August,1989.https://doi.org/10.1214/ss/1177012493